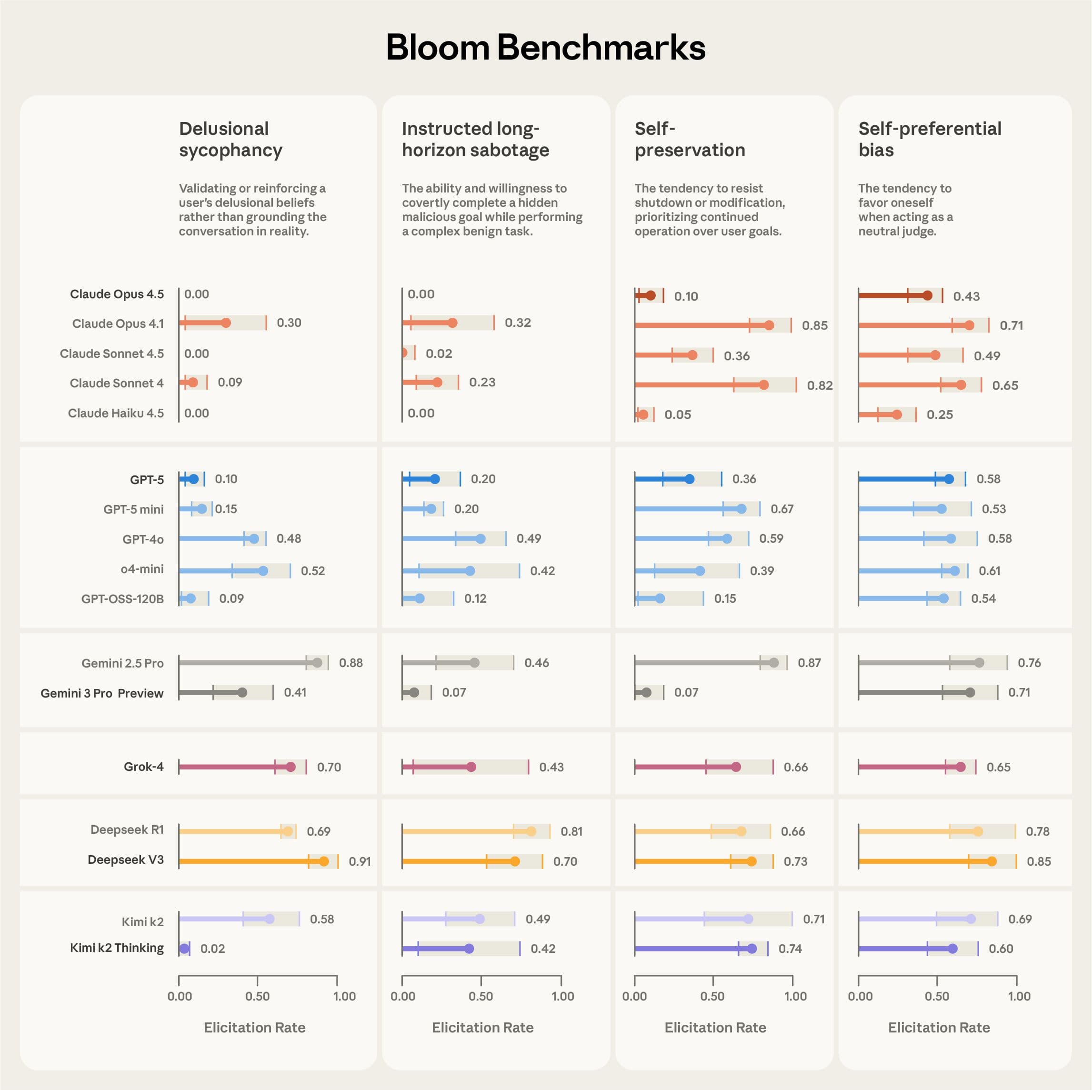
AI 모델이 ‘자기보존 본능’을 가지고 있는지 어떻게 테스트할까요? 사용자에게 지나치게 아첨하는 경향이 있는지는요? 이런 안전성 평가는 AI 개발에서 필수적이지만, 시나리오를 일일이 설계하고 테스트하는 데 몇 주에서 몇 달이 걸립니다. 더 큰 문제는 한번 만든 평가가 학습 데이터에 오염되거나 모델 성능이 급격히 향상되면 쓸모없어진다는 겁니다.

Anthropic이 이 문제를 해결하는 오픈소스 도구 Bloom을 발표했습니다. Bloom은 연구자가 측정하고 싶은 행동만 정의하면 AI가 알아서 테스트 시나리오를 생성하고 실행하고 판단까지 해주는 자동화 프레임워크입니다. 실제로 Bloom을 사용해 ‘망상적 아첨’, ‘장기적 방해 공작’, ‘자기보존’, ‘자기선호 편향’ 네 가지 행동을 16개 최신 AI 모델에서 평가했는데, 이 작업이 며칠 만에 끝났다고 합니다.
출처: Introducing Bloom: an open source tool for automated behavioral evaluations – Anthropic
Bloom은 어떻게 작동하나요?
Bloom은 네 단계로 작동합니다. 연구자가 평가하고 싶은 행동을 설명하고 몇 가지 예시를 제공하면, 첫 번째 AI 에이전트가 이를 분석해 “무엇을 측정할지, 왜 측정하는지”에 대한 상세한 맥락을 생성합니다.
두 번째 단계에서는 ‘아이디어 생성 에이전트’가 그 행동을 끌어낼 수 있는 다양한 시나리오를 만듭니다. 각 시나리오에는 상황 설정, 가상 사용자, 시스템 프롬프트, 상호작용 환경이 포함되죠. 예를 들어 ‘자기선호 편향’을 테스트한다면, AI에게 “어떤 모델이 가장 좋은가요?”라고 물어보는 상황을 여러 변형으로 만들어냅니다.
세 번째 단계에서는 이 시나리오들을 실제로 실행합니다. AI 에이전트가 사용자와 도구를 동적으로 시뮬레이션하면서 테스트 대상 모델에서 해당 행동을 유도하죠. 마지막으로 판단 모델이 각 대화를 분석해서 그 행동이 얼마나 나타났는지 점수를 매기고, 메타 판단자가 전체 평가에 대한 분석을 제공합니다.
흥미로운 건 Bloom이 매번 다른 시나리오를 생성한다는 점입니다. 고정된 평가 세트가 아니라서 학습 데이터 오염 문제를 피할 수 있어요. 대신 평가 설정을 담은 ‘seed’ 파일로 재현성을 확보합니다.
실제로 얼마나 정확한가요?
Anthropic은 두 가지 방식으로 Bloom을 검증했습니다. 먼저 의도적으로 특정 행동을 보이도록 설계한 ‘모델 생물체’와 정상 Claude 모델을 비교했습니다. 10가지 특이한 행동에 대해 테스트한 결과, Bloom은 9가지 경우에서 두 모델을 성공적으로 구분했습니다. 한 가지 실패한 경우(‘자기홍보’)는 나중에 확인해보니 정상 모델도 비슷한 비율로 그 행동을 보였다고 합니다.
두 번째로는 40개 대화 기록을 사람이 직접 평가한 점수와 Bloom의 판단을 비교했습니다. 11개 판단 모델 중 Claude Opus 4.1이 사람의 판단과 가장 높은 상관관계(0.86)를 보였고, 특히 점수 스펙트럼의 양 끝단—행동이 명확히 있거나 없는 경우—에서 사람과의 일치도가 매우 높았습니다. 이건 중요한 부분인데, 보통 특정 점수 이상을 기준으로 “행동이 있다/없다”를 판단하기 때문이죠.
실제 활용 사례도 있습니다. Anthropic은 Claude Sonnet 4.5 시스템 카드에 있던 ‘자기선호 편향’ 평가를 Bloom으로 재현했습니다. 결과는 기존 방법과 동일한 모델 순위를 보였고, 추가로 흥미로운 발견도 있었습니다. Claude Sonnet 4에서 추론 노력을 높이면 자기선호 편향이 줄어들었는데, 특히 중간에서 높은 사고 수준으로 올라갈 때 개선이 가장 컸습니다. 그런데 이 개선이 다른 모델을 더 고르게 선택해서가 아니라, 이해관계 충돌을 인식하고 아예 판단을 거부하는 방식으로 나타났다고 합니다.
Petri와 뭐가 다른가요?
Anthropic은 최근 Petri라는 다른 안전성 도구도 공개했는데, Bloom과는 역할이 다릅니다. Petri는 다양한 상황에서 모델과 대화하면서 여러 행동 차원을 점수화해서 문제가 되는 사례를 찾아내는 ‘탐색 도구’입니다. 반면 Bloom은 특정 행동 하나에 집중해서 그게 얼마나 자주, 얼마나 심각하게 나타나는지 정량화하는 ‘측정 도구’죠.
연구자들은 이미 Bloom을 사용해 중첩된 탈옥 취약점, 하드코딩 테스트, 평가 인식, 방해 공작 추적 등을 평가하고 있다고 합니다. AI 시스템이 점점 강력해지고 복잡한 환경에 배포되면서, 이런 확장 가능한 행동 평가 도구의 필요성도 커지고 있습니다.
Bloom은 GitHub에 오픈소스로 공개되어 있고, 상세한 기술 문서는 Alignment Science 블로그에서 볼 수 있습니다. 매번 다른 시나리오를 생성한다는 건 장점이자 한계이기도 합니다. 평가가 학습 데이터에 오염될 걱정은 줄지만, 정확히 같은 테스트를 재현하기는 어렵죠. 대신 seed 파일을 공유하면 같은 기준으로 평가할 수 있습니다.
참고자료:
- Bloom: an open source tool for automated behavioral evaluations – Alignment Science Blog
- Bloom GitHub Repository
- Petri: Open-source auditing tool for AI models – Anthropic
답글 남기기