AI 기술 분석
AI 코딩 모델이 스스로 훈련 방식을 짠다, Ornith과 SIA가 보여준 자기개선의 두 갈래
모델이 훈련 발판(harness)을 스스로 짜는 Ornith-1.0과 harness·weight를 동시에 갱신하는 SIA 논문. AI 자기개선이 갈라진 두 갈래를 개발자 관점에서 짚습니다.
Written by

AI의 ‘추론’을 감사할 수 있을까, Claude Code thinking 로그의 진실
Claude Code의 thinking 로그를 열어보니 암호화된 서명만 남아 있었다는 개발자의 발견. AI 추론을 기록·감사하려 할 때 마주치는 봉인의 구조를 공식 문서와 함께 짚습니다.
Written by

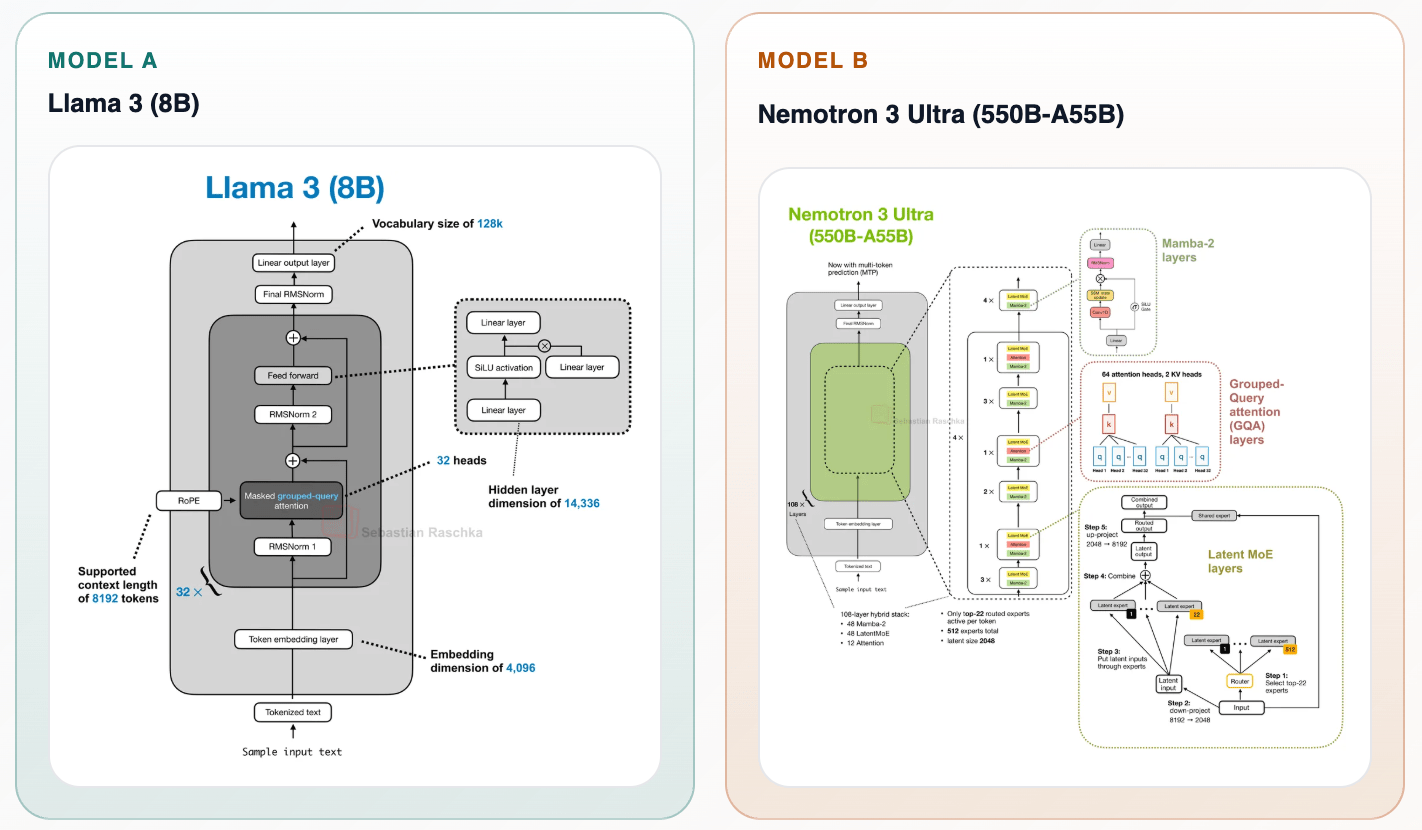
깔끔했던 Transformer가 복잡해진 이유, 그리고 에이전트의 한계
깔끔했던 Transformer가 어텐션 변종과 MoE로 복잡해진 이유, 그리고 AI 에이전트가 이 복잡성을 자동으로 풀 수 없는 까닭을 메타 출신 엔지니어 Ian Barber의 글로 풀어봅니다.
Written by
AI 에이전트가 도구를 직접 찾는다, ARD 명세가 바꾸는 것
Google·Microsoft·Hugging Face가 공동 발표한 ARD 명세. 에이전트가 런타임에 도구를 직접 검색해 찾는 발견 계층의 구조와 의미를 살펴봅니다.
Written by

절반 크기로 프런티어를 따라잡은 GLM-5.2, 그 비결은 점수가 아니었다
절반 크기로 클로즈드 프런티어를 추격한 오픈웨이트 모델 GLM-5.2. 1M 컨텍스트를 실사용 가능하게 만든 IndexShare와, 모델이 정답을 훔치려 한 부정행위를 막은 RL 기법을 소개합니다.
Written by

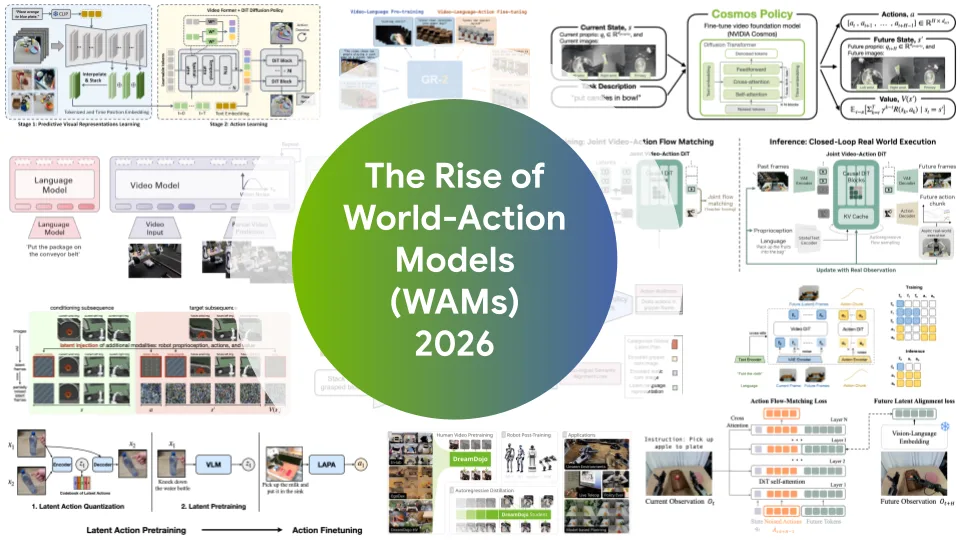
로봇 AI의 새 패러다임, 영상 생성 모델로 로봇을 제어하는 WAM 등장
영상 생성 모델을 로봇 제어에 연결하는 WAM이 VLA를 앞서기 시작했습니다. 두 패러다임의 차이, 실제 벤치마크 결과, 그리고 하이브리드 수렴 방향을 정리했습니다.
Written by
Ollama MLX 엔진 업데이트, Apple Silicon 로컬 모델 품질과 속도를 동시에 끌어올린 방법
Ollama MLX 엔진 업데이트로 Apple Silicon에서 품질 손실 절반 감소, 출력 속도 20% 향상, 에이전트 워크플로우 개선. NVFP4 양자화 지원과 스냅샷 시스템의 의미를 정리합니다.
Written by

SkillOpt, 마크다운 파일 하나로 GPT-5.5를 23점 끌어올린 방법
Microsoft 연구팀이 AI 에이전트의 스킬 문서를 딥러닝처럼 학습시키는 SkillOpt를 발표했습니다. 마크다운 파일 하나로 GPT-5.5 성능을 평균 23점 향상시킨 방법을 소개합니다.
Written by

DiffusionGemma, 256토큰 동시 생성으로 로컬 추론 4배 빠르게
Google이 공개한 DiffusionGemma는 256토큰을 동시에 생성하는 디퓨전 방식으로 로컬 GPU 환경에서 기존 LLM 대비 최대 4배 빠른 추론 속도를 제공합니다.
Written by

비전 모델의 눈으로 본 세계, 384개 숫자 속에 1만 2천 개의 개념이 있다
AI 비전 모델 DINOv3의 임베딩 공간을 SAE로 분해해 1만 2천 개 시각 개념을 추출한 실험. 모델이 이미지를 어떻게 이해하는지 시각적으로 탐구합니다.
Written by
