METR
AI 없이는 못 일한다는 개발자들, 그 코드의 청구서는 누가 받나
AI 코딩 도구 없이 일하길 거부하는 개발자들, 하지만 AI 생성 코드의 버그와 유지보수 비용은 쌓이고 있습니다. METR 연구와 아마존·우버 사례로 본 AI 코딩의 역설.
Written by

AI가 스스로 해킹하고 복제한다, 측정조차 불가능해진 보안 위협
AI 에이전트가 스스로 해킹하고 자기복제에 성공, 1년 만에 성공률 6%→81%로 급등. METR은 Claude Mythos 측정 불능 선언, Palo Alto Networks는 공격 사이클 압축 경고.
Written by

주니어 개발자 채용 14% 감소, AI가 사다리의 계단을 지운다
AI 코딩 도구가 주니어 개발자의 학습 경로를 무너뜨리고 있다는 실증 데이터 분석. Anthropic·METR 연구와 Amazon 사례로 보는 엔지니어링 커리어 사다리의 구조적 위기.
Written by

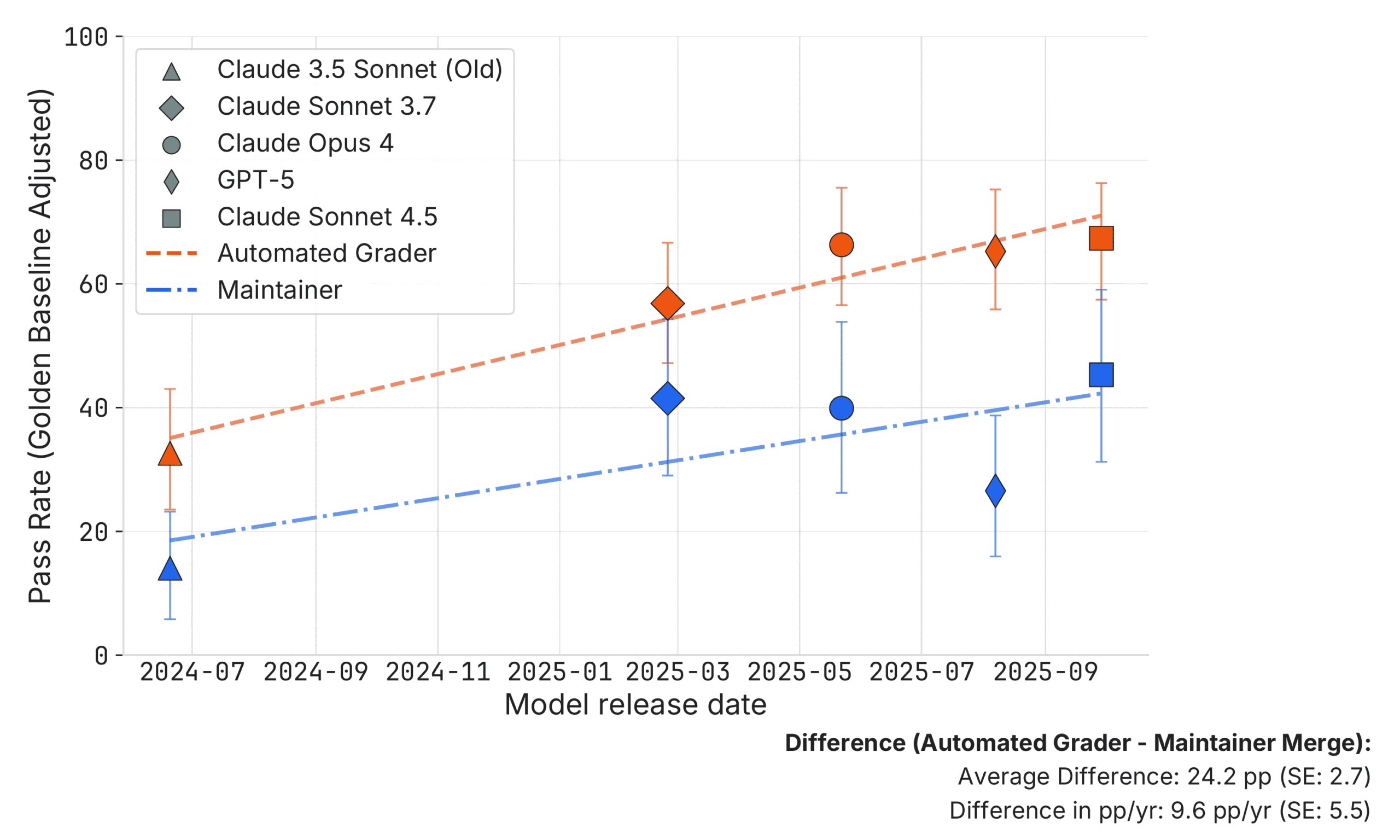
SWE-bench 통과한 AI 코드, 실제 개발자에겐 절반이 불합격
METR 연구 결과, AI가 SWE-bench를 통과한 코드의 절반이 실제 개발자 심사에서 탈락했습니다. 벤치마크 점수와 실무 유용성 사이의 격차를 분석합니다.
Written by