AI 인사이트
챗봇에서 에이전트로, 위임하고 검수하는 방식이 온다
챗봇에게 묻던 시대에서 에이전트에게 맡기고 관리자처럼 검수하는 시대로. 성패를 가르는 건 직군이 아니라 전문성이라는 발견을 소개합니다.
Written by
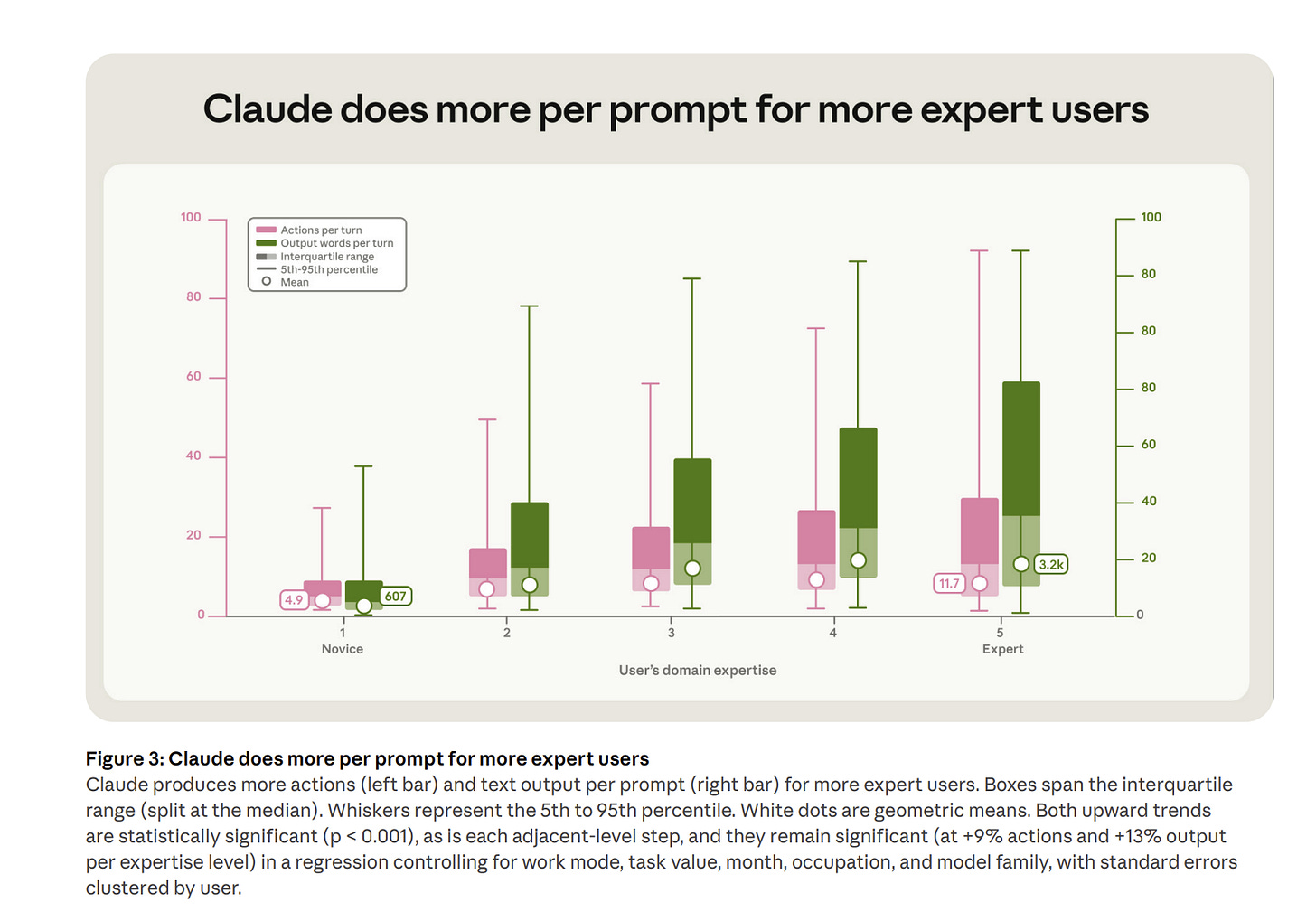
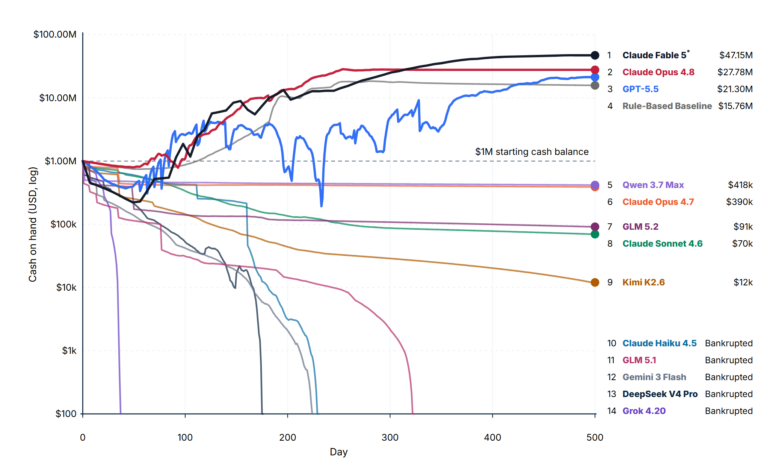
회사 하나를 500일 맡겼더니, AI 14개 중 11개가 파산했다
프린스턴 연구진의 CEO-Bench는 AI에게 가상 스타트업을 500일 경영하게 했습니다. 14개 모델 중 3개만 생존하고 단순 규칙 봇이 대부분을 이긴 결과를 소개합니다.
Written by
AI가 만든 트래픽은 어디로 사라지나, Similarweb이 추적한 ‘AI 인용의 진짜 효과’
AI 답변에 인용되면 실제 방문이 2.5배 늘지만, 그 트래픽은 분석 도구에 ‘검색’으로 잡힙니다. Similarweb이 클릭스트림으로 추적한 AI 인용의 진짜 효과.
Written by

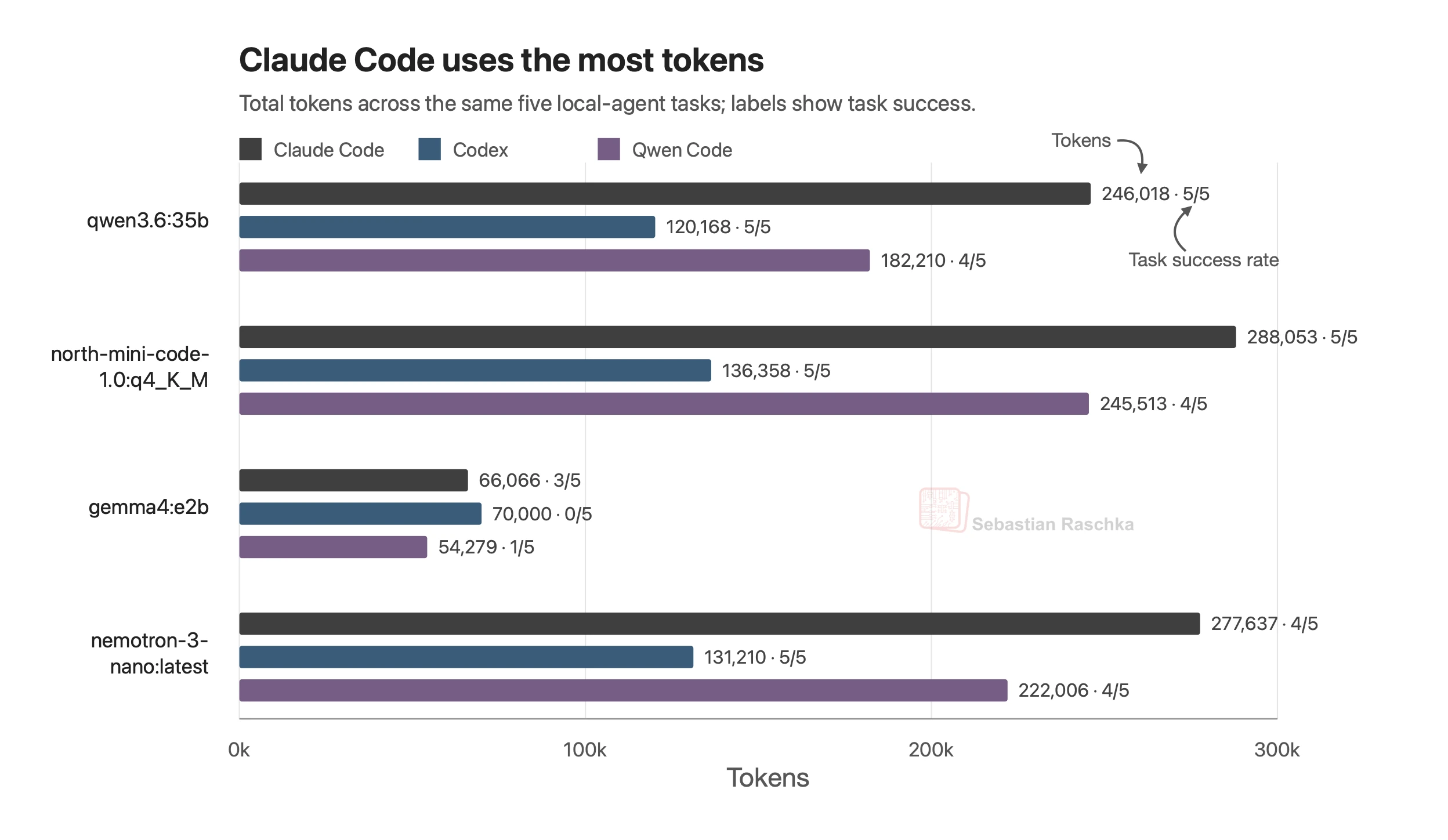
로컬 LLM으로 코딩하는 시대, Qwen 3.6 27B가 노트북에서 프런티어급에 닿다
Qwen 3.6 27B가 노트북에서 프런티어급 코딩에 근접했습니다. 모델 성능과 하니스 효율, 로컬 전환의 의미를 실무자 관점으로 짚습니다.
Written by
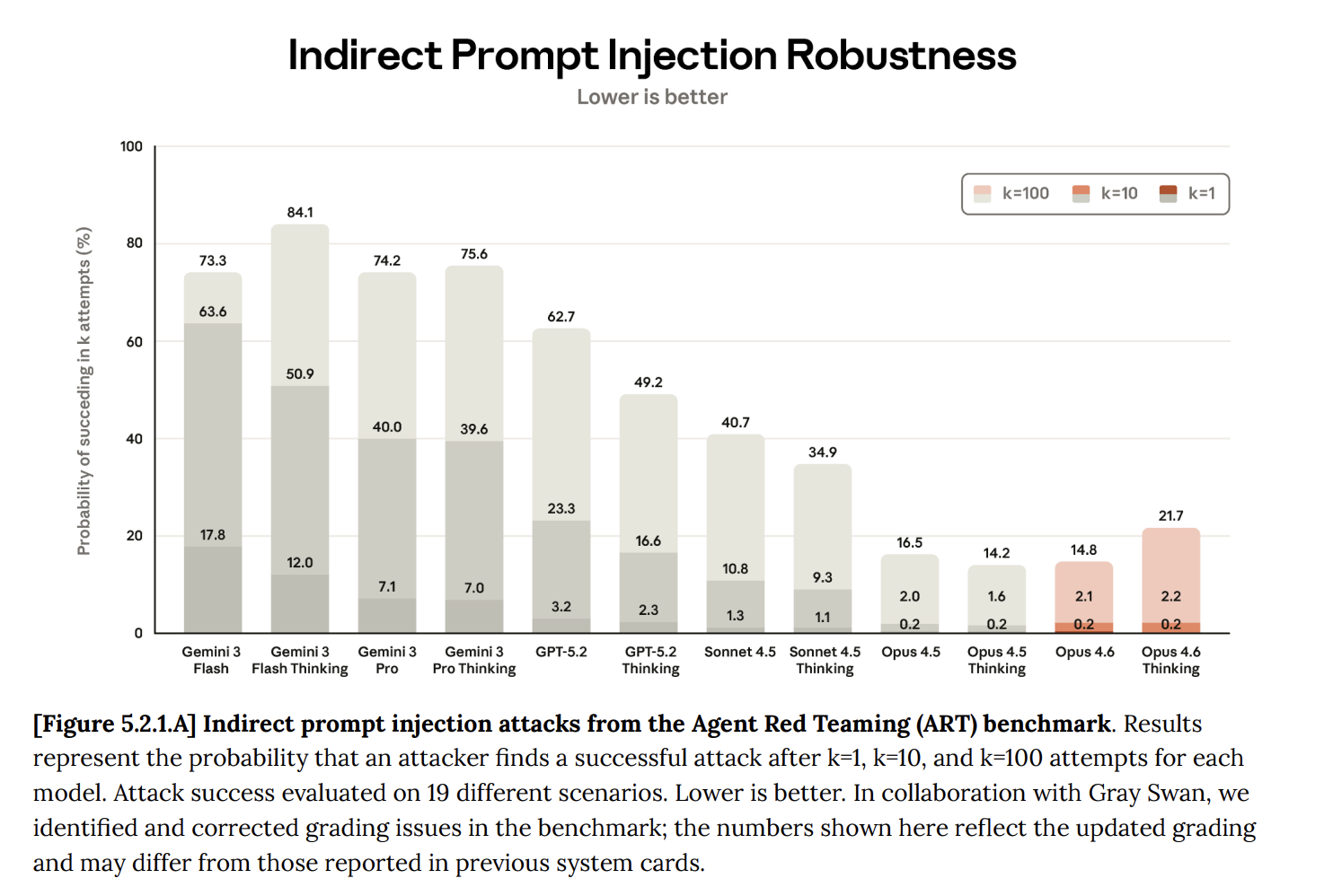
프롬프트 인젝션 6000번 공격, AI 에이전트가 다 막아낸 실험
2,000명이 6,000번 공격했지만 비밀은 새지 않았다. Claude Opus 4.6 기반 AI 비서를 대상으로 한 프롬프트 인젝션 실험과, 개인 사용자가 읽어야 할 의미를 짚습니다.
Written by
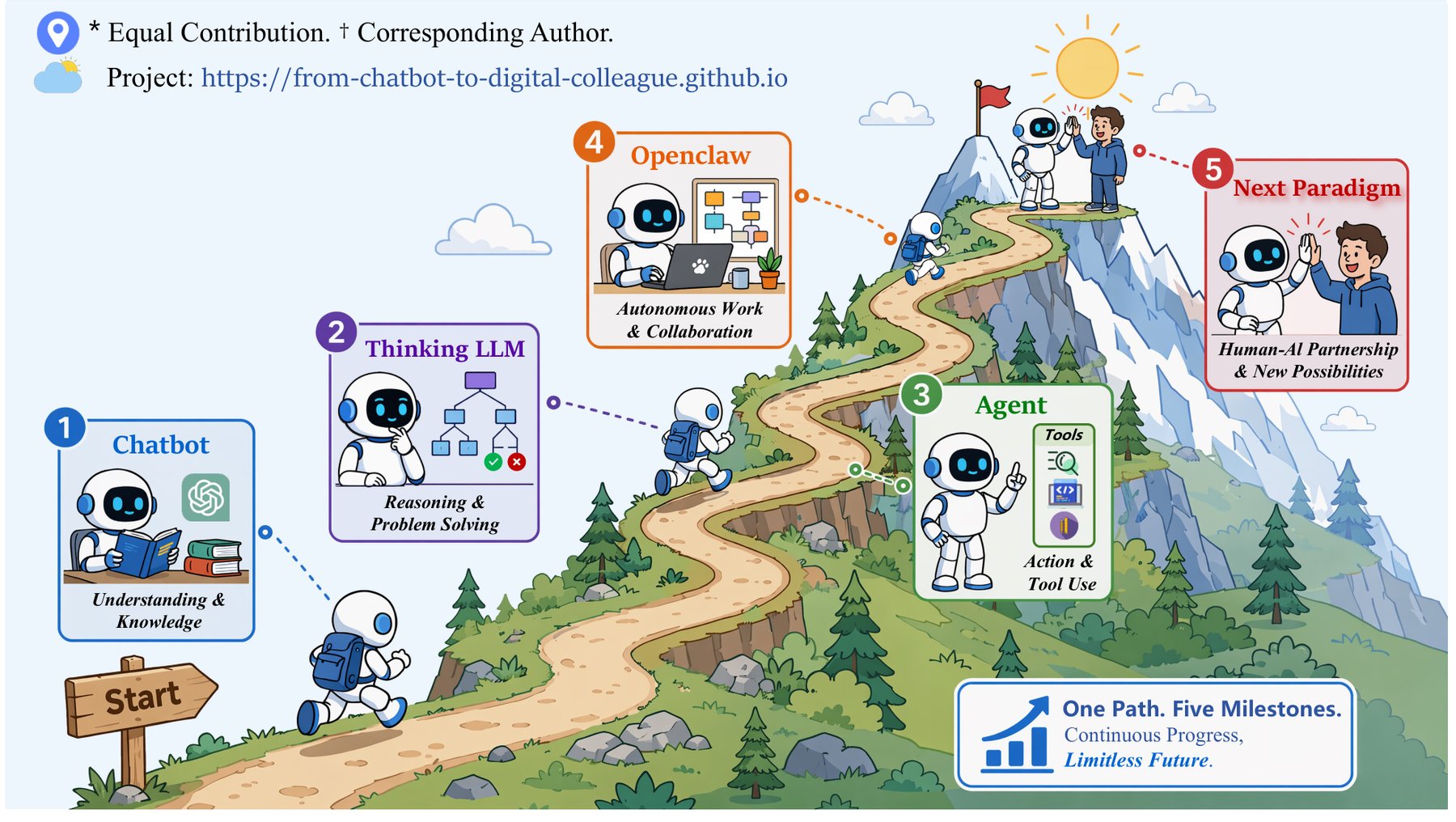
답하는 AI에서 끝내는 AI로, 텐센트가 정리한 5단계 진화
텐센트 Youtu Lab이 LLM의 진화를 챗봇부터 디지털 동료까지 5단계로 정리한 서베이 논문. ‘답하기’에서 ‘일 끝내기’로의 전환과 워크스페이스+스킬 패러다임을 풀어봅니다.
Written by
AI를 멀리한 대가, 산술이 아니라 지수로 벌어지는 ‘AI 네이티브 격차’
AI를 깊이 쓰는 사람과 멀리하는 사람 사이의 격차가 지수적으로 벌어진다는 Daniel Miessler의 주장. 거품론 속에서 다시 보는 ‘AI 네이티브 격차’를 해석합니다.
Written by

Opus 4.8에게 MRI 2차 소견을 물었더니, 의사와 결론이 갈렸다
한 개발자가 어깨 MRI 원본을 Claude Code의 Opus 4.8로 직접 분석해 의사와 정반대 진단을 받은 실험 기록. 개인이 손에 쥔 새 역량과 AI를 어디까지 믿을지의 문제를 다룹니다.
Written by

Claude Mythos 접근 차단 2주, 프론티어 AI 의존의 위험을 드러내다
미국 정부의 수출 통제 지시로 Anthropic Fable 5·Mythos 5가 전면 차단된 2주간의 사건. 프론티어 AI 의존의 새로운 취약성을 짚습니다.
Written by

당신이 올린 사진이 AI 학습 데이터가 된다, 구글이 바꾼 ‘기본값’ 한 줄
구글이 검색에 올린 이미지·음성을 AI 학습에 쓰기 시작합니다. 거부하려면 직접 꺼야 하는 ‘옵트아웃’ 기본값이 왜 데이터 주권의 핵심 쟁점인지 짚어봅니다.
Written by
