GRPO
2025년 LLM 혁명: RLVR로 훈련비용 90% 절감, 추론 모델의 시대가 왔다
2025년 LLM 분야를 장악한 RLVR+GRPO 기술과 훈련 비용 혁명. 벤치마크의 함정부터 LLM을 슈퍼파워로 활용하는 법까지, Sebastian Raschka의 연례 리뷰를 소개합니다.
Written by
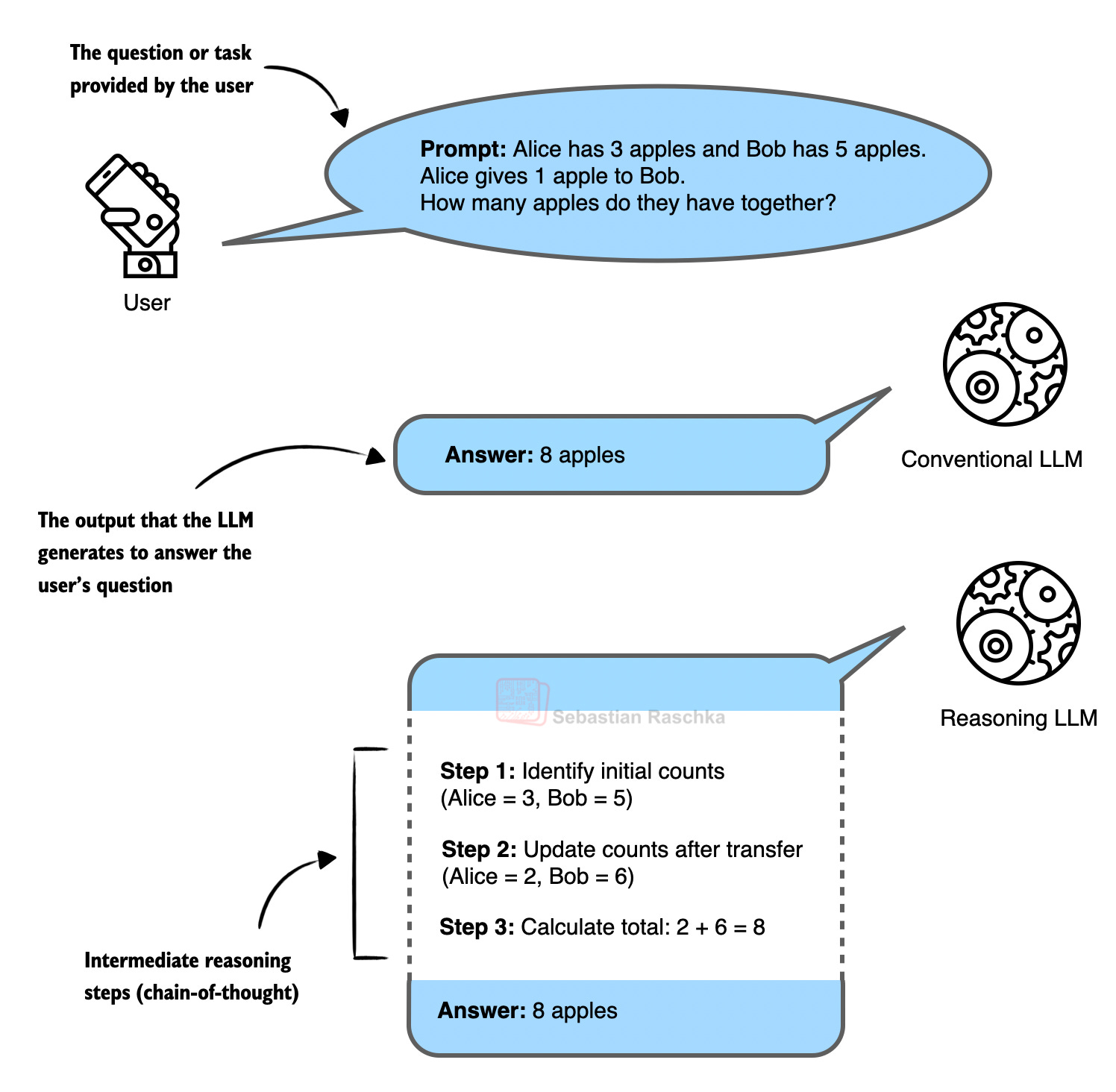
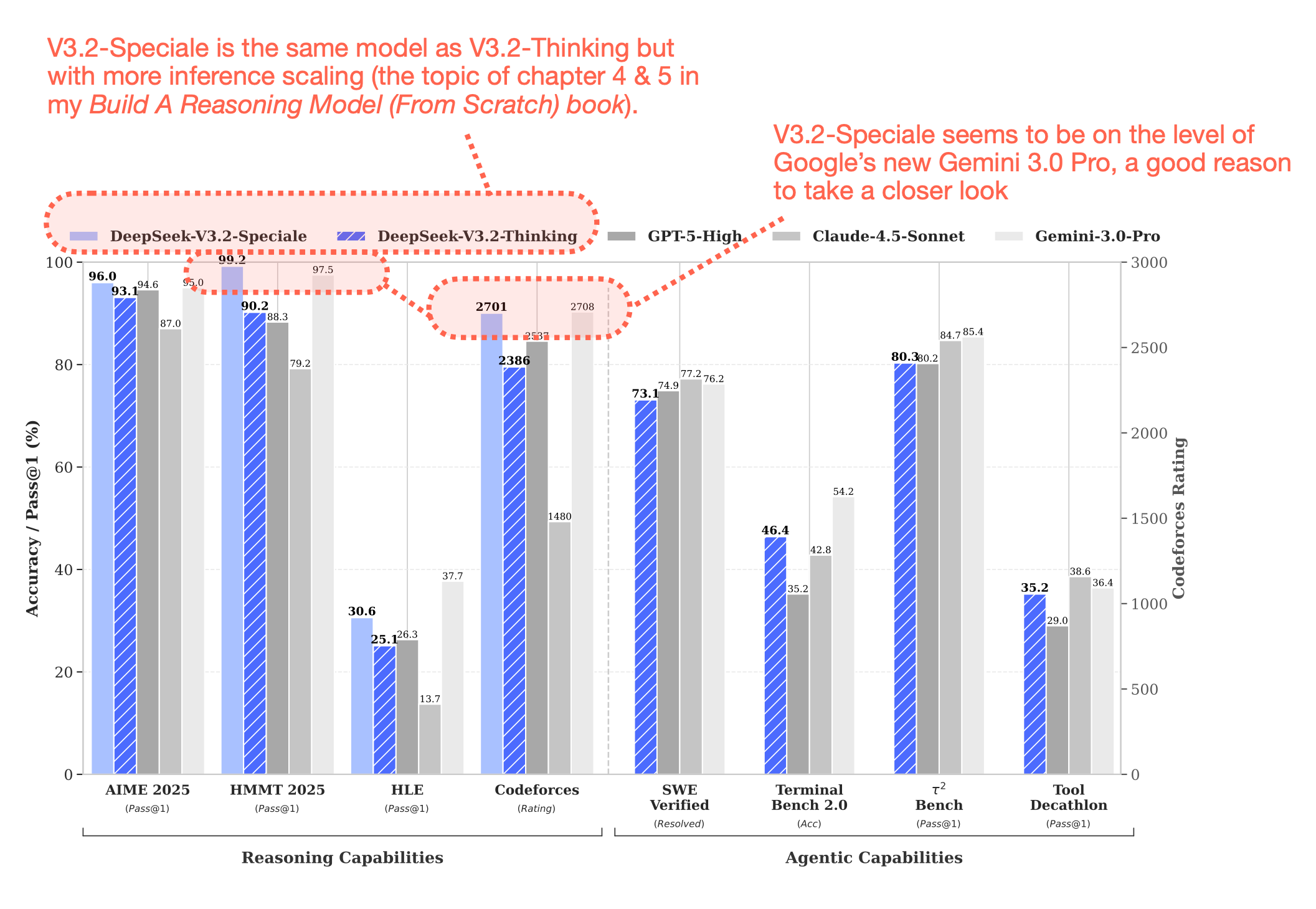
DeepSeek V3.2 기술 분석: 오픈웨이트 모델이 GPT-5 수준에 도달한 3가지 혁신
DeepSeek V3.2가 GPT-5 수준 성능을 달성한 3가지 핵심 기술을 분석합니다. DSA로 추론 비용 절감, 자가검증으로 정확도 향상, 개선된 GRPO로 안정적 학습을 구현했습니다.
Written by
코드 수정 없이 AI 에이전트를 강화학습으로 훈련: Microsoft Agent Lightning
Microsoft Agent Lightning으로 기존 AI 에이전트를 코드 수정 없이 강화학습으로 훈련하는 방법. LangChain, AutoGen 등 모든 프레임워크 지원, SQL 에이전트 정확도 73%→80% 향상 사례 포함
Written by
