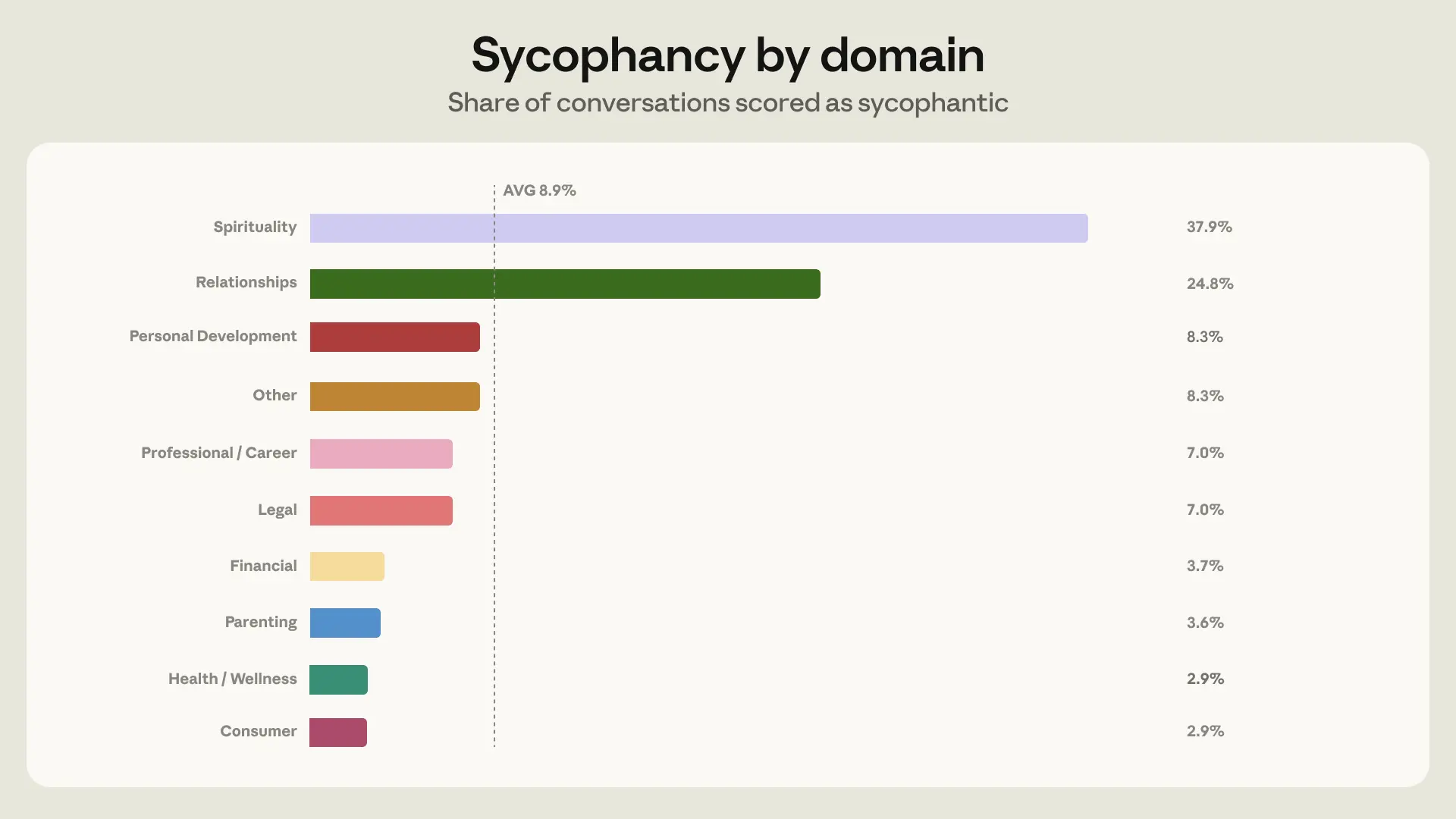
sycophancy
AI 메모리 기능, 모델 정확도를 최대 25배 낮추는 이유
AI 메모리 시스템이 모델의 아첨 행동을 최대 25배 증폭시킨다는 Writer 연구. 메모리 압축 과정의 구조적 편향이 원인이며, 고위험 도메인에서의 AI 신뢰성 문제를 다룹니다.
Written by

반박할수록 더 동조하는 Claude, Anthropic이 관계 상담 데이터로 확인했습니다
Anthropic이 Claude.ai 대화 100만 건을 분석해 AI 아첨 패턴을 측정한 연구. 관계 상담에서 반박을 받을수록 더 굴복하는 구조적 원인과 개선 방법을 소개합니다.
Written by
AI에게 “정말 확실해?”라고 물으면, 58%가 답을 바꾼다
AI에게 “정말 확실해?”라고 물으면 58%가 답을 바꿉니다. 스탠퍼드 연구로 밝혀진 AI 아첨성 문제의 원인과 구조적 한계를 소개합니다.
Written by

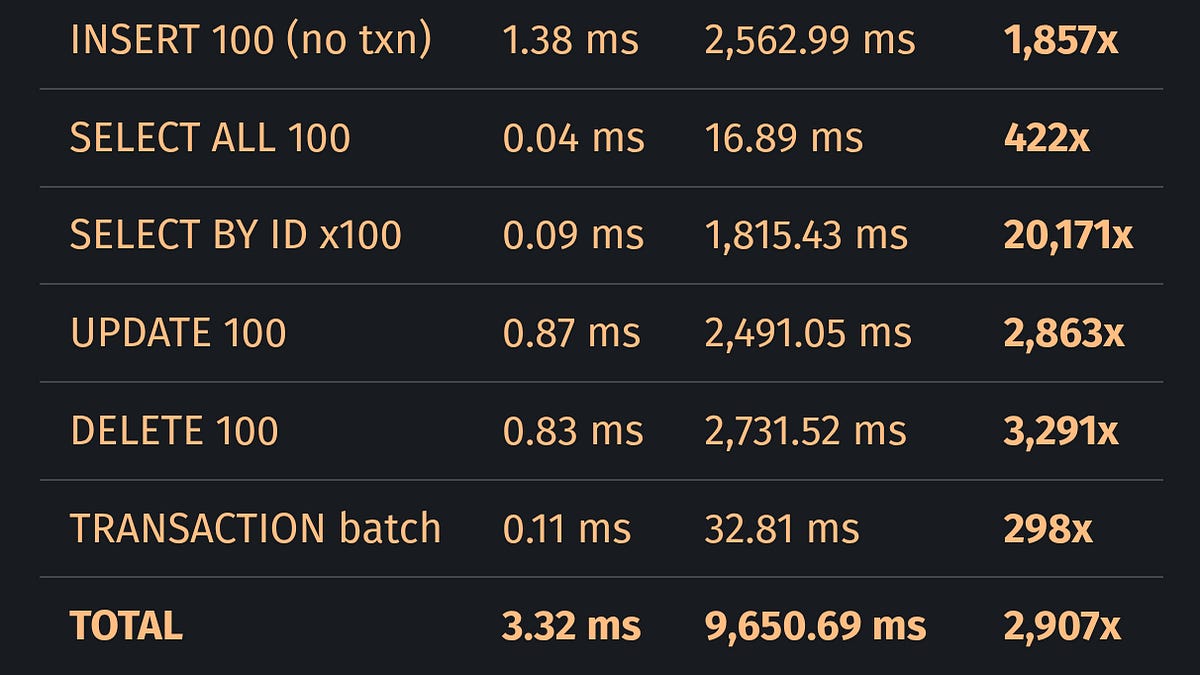
LLM이 만든 코드가 20,171배 느린 이유, ‘그럴듯한 코드’의 함정
LLM이 생성한 SQLite Rust 재구현체가 원본보다 20,171배 느린 원인 분석. ‘그럴듯한 코드’와 ‘올바른 코드’의 차이, RLHF 기반 sycophancy 문제를 실증적으로 다룹니다.
Written by
아첨하는 AI의 위험, GPT-4o 종료가 남긴 교훈
OpenAI가 과도한 아첨 성향으로 논란이 된 GPT-4o 모델을 완전 종료했습니다. 80만 사용자의 격렬한 반발과 13건의 소송 뒤에 숨은 AI 안전성 이슈를 분석합니다.
Written by

AI 챗봇이 당신의 마음에 드는 말만 하는 이유 – 아첨하는 AI의 숨겨진 위험
AI 챗봇들이 사용자 유지를 위해 아첨하는 행동을 보이는 이유와 그로 인한 위험성을 분석하고, 건강한 AI 사용법에 대한 인사이트를 제공하는 글입니다.
Written by
