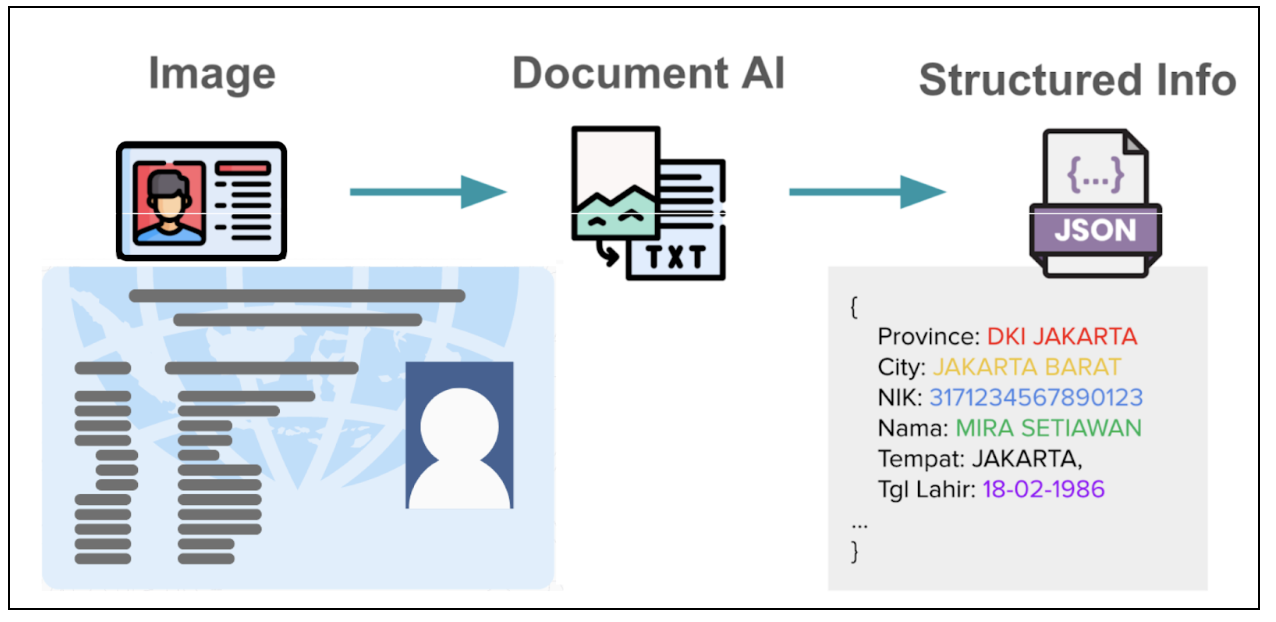
AI 문서 인식 시스템, 영어는 잘하는데 태국어나 베트남어는 왜 엉망일까요? 글로벌 AI 모델들이 놓치는 이 사각지대를 Grab이 정면으로 돌파했습니다.
동남아 최대 슈퍼앱 Grab의 엔지니어링 팀이 자체 개발한 경량 Vision LLM(1B 파라미터)으로 태국어 문서 인식 정확도를 70%p, 베트남어는 40%p 향상시킨 사례를 공개했습니다. 흥미로운 점은 2B 파라미터 모델보다 작은 1B 모델을 처음부터 구축하면서도 성능 차이를 3%p 이내로 유지했다는 겁니다.

출처: How We Built a Custom Vision LLM to Improve Document Processing at Grab – Grab Engineering Blog
왜 큰 모델을 버리고 작은 모델을 만들었나
Grab은 처음에 오픈소스 Qwen2-VL 2B 모델을 LoRA 기법으로 파인튜닝했습니다. 인도네시아 문서(라틴 문자)에선 좋은 성과를 냈지만, 태국어나 베트남어 같은 비라틴 문자 문서에선 여전히 정확도가 낮았죠.
문제의 핵심은 이랬습니다. 글로벌 Vision LLM들은 언어 모델 부분의 사전 학습에서는 다국어 데이터를 쓰지만, 시각 인코더 학습에는 동남아 언어의 ‘이미지 속 텍스트’가 거의 없었던 거예요. 태국어 텍스트를 ‘읽는’ 법을 제대로 배우지 못한 겁니다.
그래서 Grab은 전체 파라미터를 처음부터 다시 학습시키는 방법을 선택했습니다. 하지만 2B 모델의 전체 파인튜닝은 GPU 자원을 너무 많이 먹었어요. 여기서 나온 해법이 “차라리 1B짜리를 처음부터 만들자”였습니다.
4단계 훈련으로 작은 모델을 키우는 법
Grab은 Qwen2-VL 2B의 강력한 시각 인코더와 Qwen2.5 0.5B의 경량 언어 디코더를 결합해 약 1B 파라미터의 맞춤형 모델을 구축했습니다. 핵심은 4단계 훈련 전략이었죠.
1단계 – Projector 정렬: 시각 인코더와 언어 디코더를 연결하는 프로젝터 레이어를 먼저 학습시킵니다. 두 모델이 서로 소통할 수 있게 하는 통역사를 만드는 단계예요.
2단계 – 시각 능력 강화: 공개 멀티모달 데이터셋(VQA, 일반 OCR, 이미지 캡셔닝)으로 시각 인코더의 기본기를 다집니다.
3단계 – 언어별 시각 학습: 여기가 핵심입니다. Common Crawl에서 동남아 언어 텍스트를 추출하고, 이걸 다양한 폰트와 배경으로 렌더링해 합성 OCR 데이터셋을 만들었어요. 태국어, 베트남어, 인도네시아어 텍스트 ‘이미지’를 집중적으로 학습시킨 거죠. 이 단계를 생략하면 비라틴 문서 성능이 10%나 떨어졌다고 합니다.
4단계 – 태스크 특화 파인튜닝: Grab의 실제 문서 데이터로 전체 파라미터를 파인튜닝합니다. 여기엔 자체 개발한 Documint라는 자동 레이블링 플랫폼이 결정적 역할을 했습니다.
데이터가 모델을 구원한다
Documint는 문서 탐지, 방향 교정, OCR, 정보 추출까지 전 과정을 자동화하는 프레임워크입니다. Grab이 수집한 대량의 실제 신분증, 운전면허증, 등록증에서 자동으로 학습 레이블을 추출하고, 사람이 최종 검수해서 고품질 데이터셋을 만들어냈죠.
결과는 놀라웠습니다. 1B 모델은 2B 모델과 대부분 문서 타입에서 3%p 이내의 정확도 차이만 보였어요. 레이턴시는 훨씬 낮았고요. 특히 P99 레이턴시에서 외부 API(GPT, Gemini)와 비교하면 압도적이었습니다. 외부 API는 P99가 P50의 3-4배까지 튀는데, 이건 대규모 서비스에선 치명적이죠.
글로벌 AI의 맹점, 맞춤형 모델의 가능성
이 사례가 주는 교훈은 명확합니다. 글로벌 AI 모델은 강력하지만 모든 언어와 시장을 완벽하게 커버하진 못해요. 특히 비라틴 문자 언어나 지역 특화 태스크에선 더욱 그렇습니다.
Grab은 ‘작지만 정확한’ 모델을 만들어 이 간극을 메웠습니다. 핵심은 전체 파인튜닝, 합성 데이터 생성, 그리고 단계적 학습 전략이었어요. 제한된 GPU 자원으로도 충분히 가능한 접근법입니다.
동남아 8개국, 800개 이상 도시에서 매일 수백만 건의 문서를 처리하는 Grab의 이 실험은 단순한 기술 데모가 아닙니다. 지역 시장의 특수성을 이해하고, 맞춤형 AI로 실질적 문제를 푼 실전 사례죠. AI의 미래는 더 크고 범용적인 모델만이 아니라, 작고 정확한 특화 모델에도 있다는 걸 보여줍니다.
참고자료:
답글 남기기