AI 모델을 운영하는 비용이 절반 이하로 떨어지면서 동시에 성능은 GPT-5 수준이라면 어떨까요? 더 놀라운 건 이 모델을 누구나 무료로 다운로드해서 쓸 수 있다는 사실입니다.

중국 항저우의 AI 스타트업 DeepSeek가 12월 1일, GPT-5 및 Gemini-3.0-Pro와 경쟁하는 두 개의 대규모 언어 모델 DeepSeek-V3.2와 DeepSeek-V3.2-Speciale을 MIT 라이선스로 공개했습니다. 685B 파라미터 규모의 이 모델들은 국제 수학 올림피아드에서 금메달 수준의 성능을 보여주면서도, 추론 비용을 이전 모델 대비 70% 절감하는 데 성공했습니다.
출처: DeepSeek-V3.2 Release – DeepSeek
Sparse Attention이 가져온 비용 혁명
DeepSeek V3.2의 핵심은 ‘DeepSeek Sparse Attention(DSA)’이라는 새로운 아키텍처입니다. 기존 AI 모델은 긴 문서를 처리할 때 문서 길이가 두 배가 되면 계산량이 네 배로 증가하는 문제가 있었어요. DSA는 “lightning indexer”라는 기술로 입력된 맥락 중 실제로 필요한 부분만 골라내고 나머지는 무시합니다.
결과는 놀랍습니다. 128,000 토큰(약 300페이지 분량의 책)을 처리하는 비용이 이전 모델에서는 100만 토큰당 2.40달러였는데, V3.2에서는 0.70달러로 떨어졌죠. 긴 문서나 대규모 코드베이스를 분석해야 하는 개발자나 연구자에게는 실질적인 비용 절감 효과가 큽니다.
올림피아드 금메달, 그리고 GPT-5와의 경쟁
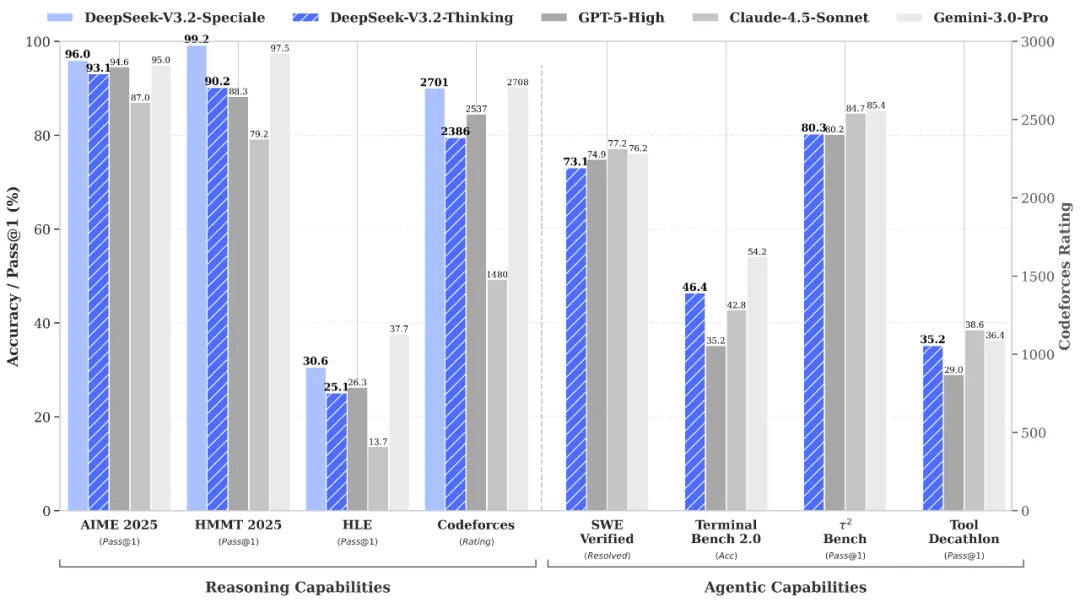
DeepSeek-V3.2-Speciale은 2025 국제 수학 올림피아드(IMO)에서 42점 만점에 35점을 받아 금메달 수준에 도달했습니다. 국제 정보 올림피아드(IOI)에서는 600점 만점에 492점으로 전체 10위를 기록했고요. ICPC 월드 파이널에서는 12개 문제 중 10개를 해결해 2위에 올랐습니다. 이 모든 테스트는 인터넷 접속이나 외부 도구 없이 진행됐어요.
AIME 2025(미국 수학 경시대회)에서 V3.2-Speciale은 96.0% 통과율을 보였는데, 이는 GPT-5-High의 94.6%를 넘어선 수치입니다. 실제 소프트웨어 버그를 수정하는 SWE-Verified 벤치마크에서는 73.1%를 기록해 GPT-5-High의 74.9%와 근소한 차이를 보였고, 복잡한 코딩 워크플로우를 측정하는 Terminal Bench 2.0에서는 46.4%로 GPT-5-High의 35.2%를 크게 앞섰습니다.
일상 용도로 최적화된 표준 V3.2 모델도 AIME에서 93.1%를 기록하며 프론티어 모델에 근접한 성능을 보여줬어요.
도구를 쓰면서 생각을 이어가는 AI
DeepSeek V3.2가 도입한 “thinking in tool-use”는 실용적 AI 에이전트로 가는 중요한 진전입니다. 기존 AI 모델들은 외부 도구(코드 실행, 웹 검색, 파일 조작 등)를 호출할 때마다 추론 맥락을 잃어버리고 처음부터 다시 생각해야 했어요.
V3.2는 여러 번의 도구 호출을 거치면서도 추론 과정을 유지합니다. 예를 들어 항저우에서 출발하는 3일짜리 여행을 계획한다고 해볼까요. 호텔 가격, 식당 평점, 관광지 비용이 숙소 선택에 따라 달라지는 복잡한 제약 조건이 있을 때, 모델은 여러 검색과 계산을 거치면서도 전체 맥락을 놓치지 않고 최적의 일정을 짜냅니다.
DeepSeek은 이를 위해 1,800개 이상의 작업 환경과 85,000개의 복잡한 지시를 포함한 합성 데이터셋을 만들었습니다. 실제 웹 검색 API, 코딩 환경, Jupyter 노트북을 사용해 훈련했기 때문에 처음 보는 도구와 환경에도 잘 대응합니다.
오픈소스 전략이 흔드는 AI 시장
DeepSeek의 가장 파괴적인 선택은 이 모든 것을 MIT 라이선스로 공개한 겁니다. OpenAI나 Anthropic이 가장 강력한 모델을 유료 API로만 제공하는 것과 대조적이죠. 누구나 685B 파라미터 모델의 전체 가중치, 학습 코드, 문서를 Hugging Face에서 다운로드해 수정하고 배포할 수 있습니다.
기업 입장에서는 매력적인 제안이에요. 프론티어급 성능을 대폭 낮은 비용에, 원하는 대로 배포할 수 있으니까요. DeepSeek는 OpenAI 호환 포맷으로 메시지를 인코딩하는 파이썬 스크립트까지 제공해 다른 서비스에서 마이그레이션하기도 쉽게 만들었습니다.
다만 DeepSeek의 중국 배경은 데이터 주권과 규제 불확실성을 불러옵니다. 독일 데이터 보호 당국은 6월 DeepSeek의 독일 사용자 데이터 중국 전송이 EU 규정 위반이라며 애플과 구글에 앱 차단을 요청했어요. 이탈리아는 2월 DeepSeek 앱을 차단했고, 미국 의회도 정부 기기에서 사용 금지를 추진 중입니다.
미중 AI 경쟁의 새로운 국면
이번 출시는 AI 경쟁의 전제를 바꿉니다. 미국의 첨단 칩 수출 규제에도 불구하고 DeepSeek는 계속 프론티어 모델을 만들어내고 있어요. V3 모델은 약 2,000개의 구형 Nvidia H800 칩(현재는 수출 금지)으로 학습했다고 알려졌지만, V3.2를 무엇으로 학습했는지는 공개하지 않았습니다. DeepSeek는 화웨이와 캠브리콘의 중국산 칩으로도 모델이 작동한다고 밝힌 바 있죠.
DeepSeek의 기술 보고서는 포스트 트레이닝(사전 학습 이후 추가 훈련) 투자가 이제 사전 학습 비용의 10% 이상을 차지한다고 밝혔습니다. 추론 능력 향상에 상당한 자원을 투입한 거예요. 하지만 “세계 지식의 폭”에서는 여전히 주요 상용 모델에 뒤처진다고 인정하며, 사전 학습 컴퓨팅을 확대해 이를 보완할 계획이라고 했습니다.
DeepSeek-V3.2-Speciale은 12월 15일까지 임시 API로 제공되며, 이후 표준 모델에 기능이 통합됩니다. Speciale은 깊은 추론 전용으로 설계돼 도구 호출을 지원하지 않아요.
질문은 더 이상 “중국 AI가 실리콘밸리와 경쟁할 수 있는가”가 아닙니다. “미국 기업들이 중국 경쟁자가 비슷한 기술을 무료로 배포할 때 어떻게 리드를 유지할 것인가”죠.
참고자료:
- DeepSeek just dropped two insanely powerful AI models that rival GPT-5 and they’re totally free – VentureBeat
- DeepSeek-V3.2 – Simon Willison’s Weblog
- DeepSeek-V3.2 Technical Report – Hugging Face
- DeepSeek-V3.2 Model Page – Hugging Face
답글 남기기