컨텍스트가 50,000 토큰을 넘는 순간, AI 코딩 에이전트 비용의 절반 이상은 이미 쓴 대화를 ‘다시 읽는 데’ 나갑니다. 대화가 길어질수록 비용이 선형이 아니라 가파르게 치솟는 이유가 여기 있습니다.

exe.dev의 Philip Zeyliger가 자사 코딩 에이전트 Shelley의 실제 대화 250개를 분석해 LLM 에이전트의 비용 구조를 파헤쳤습니다. 캐시 읽기 비용이 대화가 길어질수록 2차 함수처럼 폭증한다는 사실, 그리고 왜 이게 구조적으로 피하기 어려운지를 데이터로 보여줍니다.
출처: Expensively Quadratic: the LLM Agent Cost Curve – exe.dev blog
에이전트는 매번 대화 전체를 다시 보낸다
AI 코딩 에이전트가 작동하는 방식은 단순합니다. 사용자가 입력을 주면, 에이전트는 지금까지의 대화 전체를 LLM에 전송하고 응답을 받습니다. 도구(tool call)가 필요하면 실행하고, 그 결과를 다시 붙여서 또 전송합니다. 이 과정이 루프로 반복되죠.
문제는 여기서 시작됩니다. 대화가 쌓일수록 매 호출마다 읽어야 하는 과거 내용이 늘어나고, 그 비용이 고스란히 누적됩니다.
비용이 2차 함수처럼 증가하는 이유
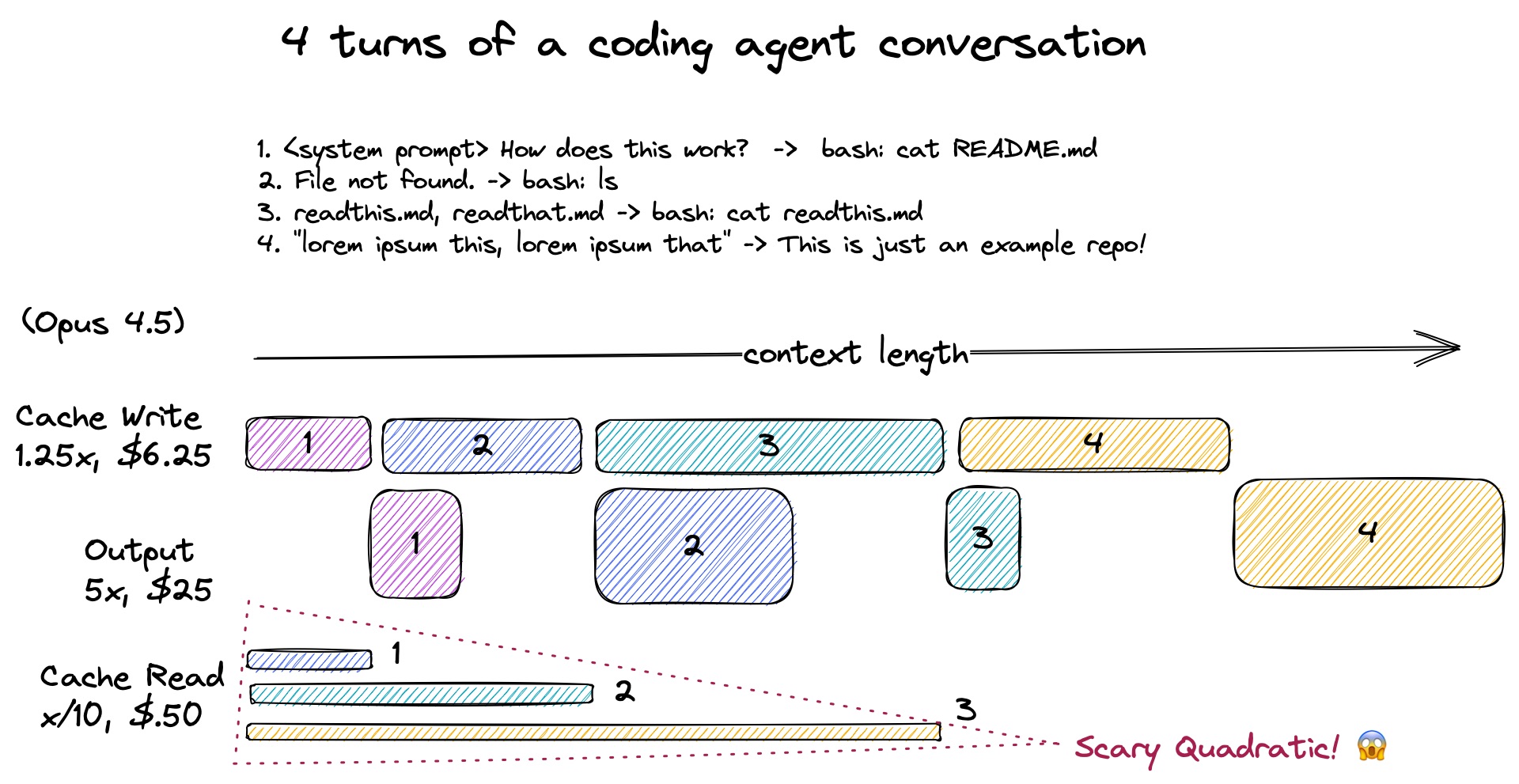
LLM API는 입력 토큰, 캐시 쓰기, 출력 토큰, 캐시 읽기 이렇게 네 가지 항목으로 비용을 청구합니다. 이 중 캐시 읽기가 핵심입니다.
에이전트는 이전 대화 내용을 캐시에 저장해두고, 다음 호출 때 이를 불러옵니다. 캐시 읽기 비용은 일반 입력보다 훨씬 저렴하지만(Anthropic 기준 약 1/10 수준), 호출할 때마다 누적된 전체 컨텍스트를 읽어야 합니다. 10번째 호출은 앞선 9번의 내용 전부를, 100번째 호출은 앞선 99번의 내용 전부를 읽는 식이죠.
결국 총 캐시 읽기 비용은 대략 토큰 수 × 호출 수에 비례합니다. 둘 다 대화가 길어질수록 커지니, 비용은 2차 함수 곡선을 그리며 치솟습니다.
실제 데이터로 보면 얼마나 심각할까
exe.dev 팀이 자사 코딩 에이전트 Shelley의 실제 대화 데이터를 분석한 결과는 꽤 인상적입니다.
한 기능 구현 대화에서 총 비용은 약 12.93달러였는데, 대화가 끝날 무렵 캐시 읽기가 전체 비용의 87%를 차지했습니다. 컨텍스트가 27,500 토큰에 도달하는 시점에 이미 캐시 읽기가 전체 비용의 절반을 넘었고요.
250개 대화를 무작위 샘플링한 분석에서도 패턴은 동일했습니다. 대화가 길수록, 호출 횟수가 많을수록 캐시 읽기 비용이 압도적으로 늘어납니다. 시뮬레이터로 계산해보면, Anthropic Opus 4.5 기준으로 컨텍스트가 15만 토큰, 호출이 400회에 이를 경우 총 비용 약 18달러 중 캐시 읽기가 89%인 16달러를 차지합니다.
이 구조가 만드는 딜레마
흥미로운 건 이 문제에 쉬운 답이 없다는 점입니다. 에이전트가 도구를 자주 호출하며 피드백을 주고받는 것, 즉 잦은 LLM 호출이 에이전트를 올바른 방향으로 이끄는 핵심 메커니즘이기도 하기 때문입니다. 비용을 줄이려고 호출 수를 억지로 줄이면, 에이전트가 잘못된 방향으로 흘러갈 수 있습니다.
exe.dev 팀이 제시하는 방향은 세 가지입니다.
- 서브에이전트 활용: 반복적인 작업을 메인 컨텍스트 바깥으로 분리합니다. Shelley는 코드베이스 검색에 LLM 기반 키워드 검색 도구를 별도로 사용하는데, 이렇게 하면 메인 루프의 컨텍스트를 늘리지 않고도 LLM의 능력을 활용할 수 있습니다.
- 대화 재시작: 컨텍스트를 잃는 것 같아 망설여지지만, 맥락을 다시 세우는 토큰 비용이 긴 대화를 이어가는 비용보다 훨씬 저렴한 경우가 많습니다. 저자는 git 저장소에서 새 작업을 시작할 때마다 자연스럽게 새 대화를 여는 것처럼, 에이전트도 같은 방식으로 접근하면 된다고 말합니다.
- 툴 출력 제한은 역효과: 일부 에이전트는 툴 출력이 일정 크기를 넘으면 잘라내는데, 이는 오히려 같은 파일을 여러 번 호출하게 만들어 비용을 늘립니다. 어차피 읽어야 할 파일이라면 한 번에 통째로 읽는 게 낫습니다.
이 비용 구조는 단순히 “얼마나 쓰나”의 문제가 아니라, 에이전트를 어떻게 설계하고 운용하느냐의 문제와 직결됩니다. 비용 관리, 컨텍스트 관리, 에이전트 오케스트레이션이 결국 같은 문제라는 저자의 질문이 울림 있게 남습니다. 원문에는 대화별 비용 곡선을 직접 탐색할 수 있는 인터랙티브 그래프와 시뮬레이터도 제공되니, 자신의 사용 패턴에 맞춰 직접 계산해보실 수 있습니다.
답글 남기기