AI 에이전트가 여러분의 요청을 받아 코드를 작성하고, 파일을 수정하고, 결과를 보고하는 과정, 겉으로는 단순해 보이지만 그 내부에선 무슨 일이 일어날까요? OpenAI가 자사 코딩 에이전트 Codex CLI의 핵심 작동 원리인 “agent loop”를 상세히 공개했습니다. AI 에이전트를 만들거나 이해하려는 개발자들에게 실무적 인사이트를 제공하는 흔치 않은 사례입니다.

OpenAI가 Codex CLI의 내부 구조와 설계 철학을 공개한 기술 블로그 시리즈의 첫 번째 글입니다. AI 에이전트의 핵심인 “agent loop”가 어떻게 작동하고, 실무에서 어떤 과제를 해결해야 하는지 GitHub 오픈소스 코드와 함께 설명합니다.
출처: Unrolling the Codex agent loop – OpenAI
Agent Loop, 3단계의 반복
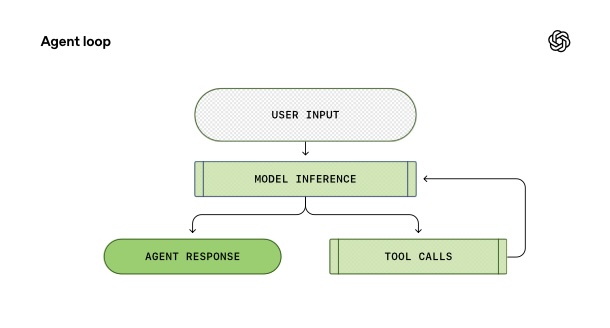
모든 AI 에이전트의 심장부엔 “agent loop”라는 메커니즘이 있습니다. 작동 방식은 생각보다 단순합니다.
먼저 사용자가 요청을 보내면, 에이전트는 이를 모델이 이해할 수 있는 형태의 프롬프트로 변환합니다. 이 프롬프트를 모델에 보내 추론(inference)을 실행하죠. 모델은 텍스트를 토큰(token)이라는 숫자 시퀀스로 바꾼 뒤 새로운 토큰들을 생성하고, 이를 다시 텍스트로 변환해 응답을 만들어냅니다. 우리가 보는 스트리밍 출력이 바로 이 토큰들이 실시간으로 번역되는 과정입니다.
여기서 모델은 두 가지 중 하나를 선택합니다. (1) 바로 최종 답변을 내놓거나, (2) 도구 호출(tool call)을 요청하는 거죠. 예를 들어 “ls 명령어를 실행해서 결과를 알려줘”라고 요청할 수 있습니다. 에이전트는 이 도구를 실행하고 그 결과를 다시 프롬프트에 추가한 뒤 모델을 재호출합니다.
이 과정은 모델이 더 이상 도구를 호출하지 않고 사용자에게 보낼 최종 메시지를 내놓을 때까지 반복됩니다. 예를 들어 사용자가 “architecture.md 파일을 만들어줘”라고 요청했다면, 에이전트는 여러 번 도구를 호출해 파일을 생성하고, 마지막엔 “파일을 추가했습니다”라고 답변하죠. 이 답변이 나오는 순간 에이전트의 한 턴(turn)이 끝나고, 사용자가 다음 요청을 할 차례가 됩니다.
끝없이 증가하는 프롬프트, 어떻게 관리할까?
Agent loop의 작동 방식을 이해하면 한 가지 문제가 보입니다. 대화가 길어질수록 프롬프트도 계속 커진다는 겁니다. 새로운 턴을 시작할 때마다 이전 대화 내역을 모두 포함해야 하니까요.
매 요청마다 전체 대화 내역을 전송해야 하니, 네트워크로 전송하는 JSON 데이터 양은 대화가 길어질수록 기하급수적으로 늘어납니다. 하지만 진짜 병목은 따로 있습니다. 바로 모델 샘플링(계산) 비용이죠. 네트워크 전송보다 훨씬 더 많은 비용이 드니까요.
OpenAI는 prompt caching으로 이 문제를 해결했습니다. 새 프롬프트가 이전 프롬프트의 정확한 prefix(접두사)가 되도록 설계하면, 모델은 이미 계산한 부분을 재사용할 수 있습니다. 결과적으로 새로 추가된 부분만 계산하면 되니, 샘플링 비용이 linear하게 유지되는 거죠.
그래서 Codex 팀은 캐시 적중률을 극대화하는 데 집요합니다. 예를 들어 초기 MCP 도구 구현에선 도구 목록을 일관된 순서로 나열하지 않아서 캐시 미스를 유발하는 버그가 있었어요. 대화 중간에 설정을 바꿔야 할 땐 기존 메시지를 수정하는 대신 새 메시지를 추가하는 방식으로 캐시를 보존합니다.
또 다른 과제는 컨텍스트 윈도우(context window) 관리입니다. 모델이 한 번에 처리할 수 있는 토큰 수엔 한계가 있으니까요. Codex는 토큰 수가 일정 임계값을 넘으면 자동으로 대화를 압축(compact)합니다. Responses API의 /responses/compact 엔드포인트를 사용해 이전 대화를 더 작은 형태로 요약하면서도, 모델이 맥락을 잃지 않도록 암호화된 latent understanding을 보존하죠.
왜 OpenAI는 이 정보를 공개했을까?
흥미로운 건 OpenAI가 단순히 개념만 설명하는 게 아니라 GitHub 저장소(https://github.com/openai/codex)의 실제 코드와 Pull Request까지 링크했다는 점입니다. “여기 설계 결정이 왜 이뤄졌는지 궁금하면 이슈와 PR을 보세요”라고 직접 안내할 정도죠.
특히 주목할 만한 건 Zero Data Retention(ZDR) 고객 지원 이야기입니다. Codex는 stateless 방식(이전 응답 ID를 저장하지 않음)을 택했는데, 이게 ZDR 고객에겐 필수적이기 때문입니다. 데이터를 저장하지 않으면서도 암호화된 추론 메시지를 재사용할 수 있도록 설계한 거죠.
이런 상세한 공개는 AI 에이전트를 만드는 개발자들에게 실용적인 가이드가 됩니다. prompt caching을 고려한 프롬프트 구조 설계, 컨텍스트 윈도우 관리 전략, 그리고 성능과 프라이버시 사이의 균형 잡기까지, OpenAI가 실제로 부딪힌 문제와 해결책을 배울 수 있으니까요.
OpenAI는 이것이 시리즈의 첫 번째 글이라고 밝혔습니다. 앞으로 CLI 아키텍처, 도구 사용 구현, 샌드박싱 모델 등을 다룰 예정이라고 하니, AI 에이전트 개발에 관심 있다면 주목할 만합니다.
참고자료:
- GitHub – openai/codex – Codex CLI 오픈소스 저장소
답글 남기기