MoE
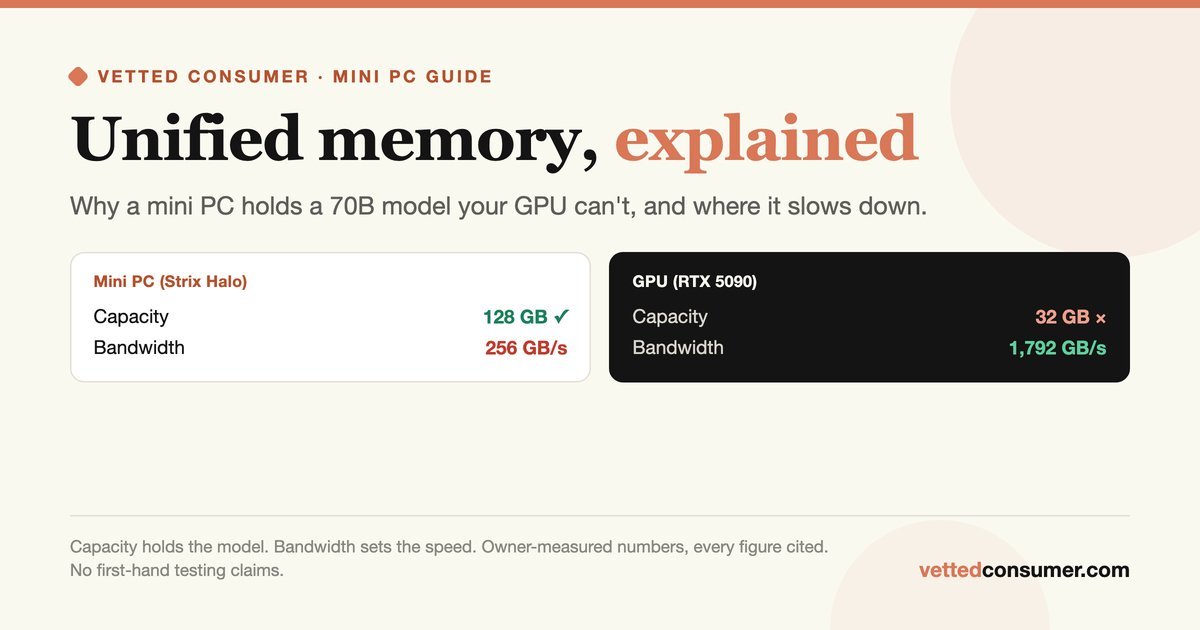
RTX 5090은 못 돌리는 70B 모델, 미니PC는 어떻게 돌릴까
RTX 5090은 못 돌리는 70B 모델을 미니PC가 돌릴 수 있는 이유. 통합 메모리의 용량과 대역폭 트레이드오프, 프롬프트 처리 병목을 다룹니다.
Written by
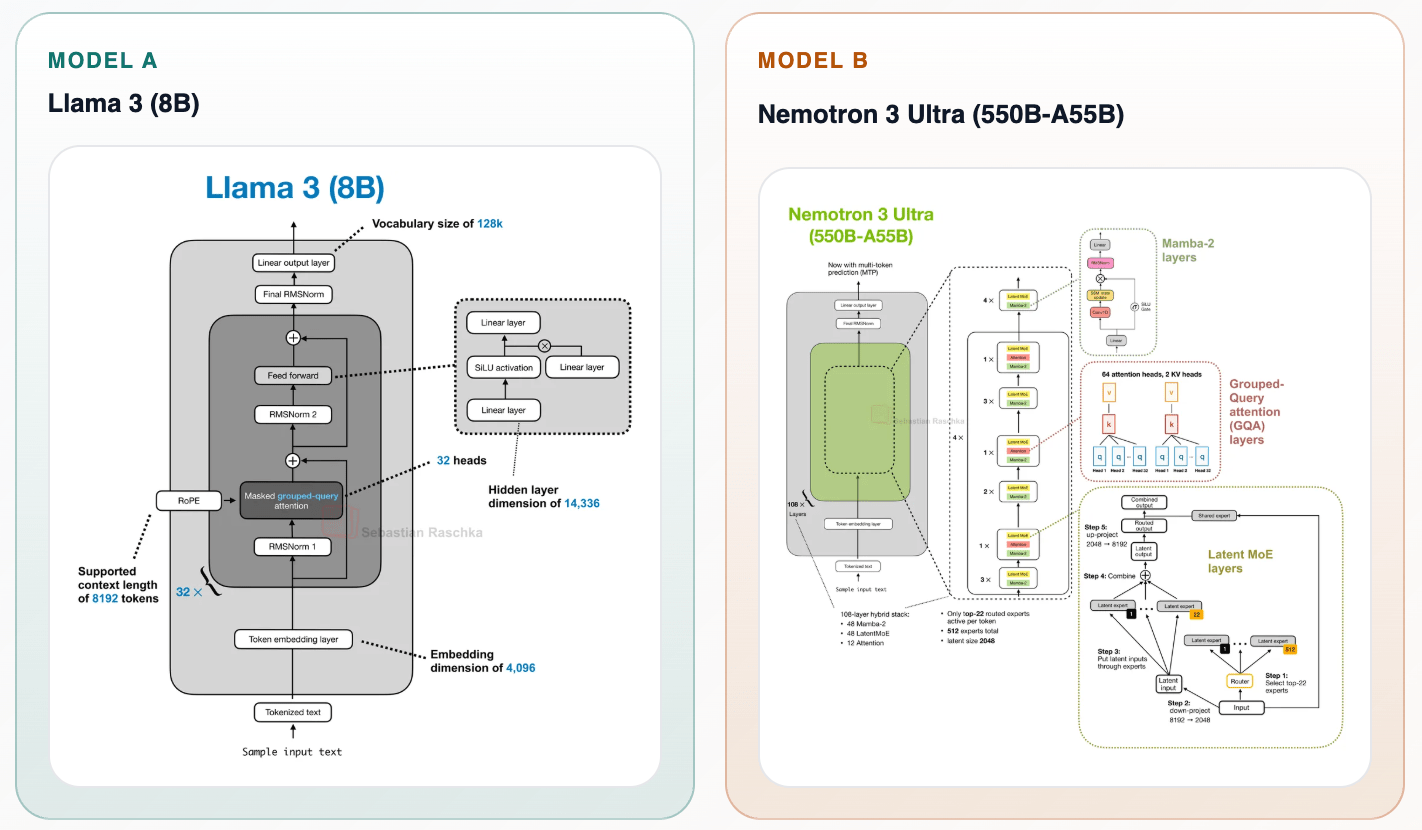
깔끔했던 Transformer가 복잡해진 이유, 그리고 에이전트의 한계
깔끔했던 Transformer가 어텐션 변종과 MoE로 복잡해진 이유, 그리고 AI 에이전트가 이 복잡성을 자동으로 풀 수 없는 까닭을 메타 출신 엔지니어 Ian Barber의 글로 풀어봅니다.
Written by
DiffusionGemma, 256토큰 동시 생성으로 로컬 추론 4배 빠르게
Google이 공개한 DiffusionGemma는 256토큰을 동시에 생성하는 디퓨전 방식으로 로컬 GPU 환경에서 기존 LLM 대비 최대 4배 빠른 추론 속도를 제공합니다.
Written by

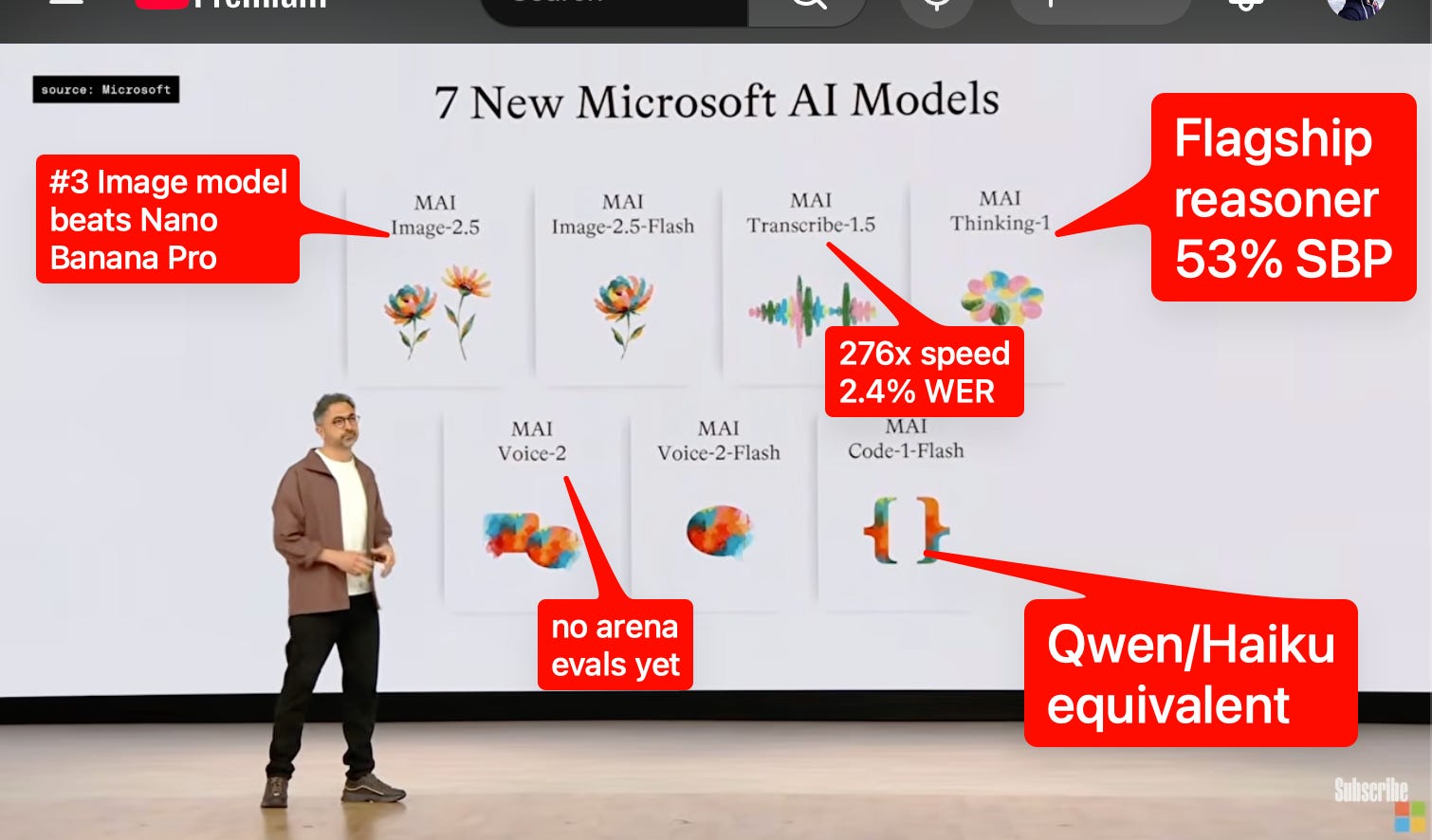
Microsoft MAI-Thinking-1, 증류 없이 만든 35B 추론 모델이 던지는 질문
Microsoft가 Build 2026에서 공개한 첫 자체 추론 모델 MAI-Thinking-1. 타사 증류 없이 35B 활성 파라미터로 대형 모델과 경쟁하는 MoE 구조와 그 의미를 소개합니다.
Written by
전문가 12.5%만 써도 성능 그대로, Ai2의 새로운 MoE 학습법 EMO
Ai2와 UC Berkeley가 발표한 EMO는 문서 경계를 학습 신호로 활용해 전문가들이 도메인별로 특화되게 만드는 MoE 학습 방식입니다. 전문가 12.5%만으로도 성능 손실 3% 이내를 달성했습니다.
Written by

NVIDIA Nemotron 3 Nano Omni, 멀티모달 에이전트 처리량 9배 높인 방법
NVIDIA Nemotron 3 Nano Omni는 텍스트·이미지·영상·오디오를 단일 모델로 처리하는 오픈 멀티모달 모델입니다. 파편화된 에이전트 체인 구조를 통합해 처리량을 최대 9배 높인 방법을 소개합니다.
Written by

Gemma 4가 증명한 것, AI 모델은 이제 하나의 설계로 모든 곳을 커버할 수 없다
Google Gemma 4가 엣지와 서버를 아예 다른 아키텍처로 설계한 이유. 하드웨어 제약이 AI 모델 설계를 어떻게 바꾸고 있는지 분석합니다.
Written by
DeepSeek V4 출시, 1M 컨텍스트를 에이전트가 실제로 쓸 수 있게 만든 방법
DeepSeek V4가 1M 토큰 컨텍스트를 실용적으로 만든 방법. CSA·HCA 하이브리드 어텐션으로 KV 캐시를 90% 줄이고 에이전트 추론 흐름을 개선했습니다.
Written by

21GB로 코딩 에이전트 상위권, Qwen3.6-35B-A3B 오픈소스 공개
알리바바 Qwen 팀이 공개한 Qwen3.6-35B-A3B, MoE 구조로 21GB로 압축해 노트북에서 실행 가능하면서 코딩 에이전트 상위권 성능을 냅니다.
Written by

API 없이 Claude Code 쓴다, LM Studio 헤드리스 CLI와 Gemma 4 실전기
LM Studio 헤드리스 CLI로 Gemma 4를 로컬에서 실행하고 Claude Code와 연결하는 실전기. API 비용 없이 초당 51토큰, 데이터는 기기 밖으로 나가지 않습니다.
Written by