LLM 평가
HELMET: 장문맥 AI 모델의 능력을 정확하게 측정하는 새로운 벤치마크
프린스턴 대학 연구팀이 개발한 HELMET 벤치마크를 통해 장문맥 언어 모델(LCLMs)의 능력을 정확하게 평가하는 방법과 최신 모델들의 장단점에 대해 알아봅니다.
Written by

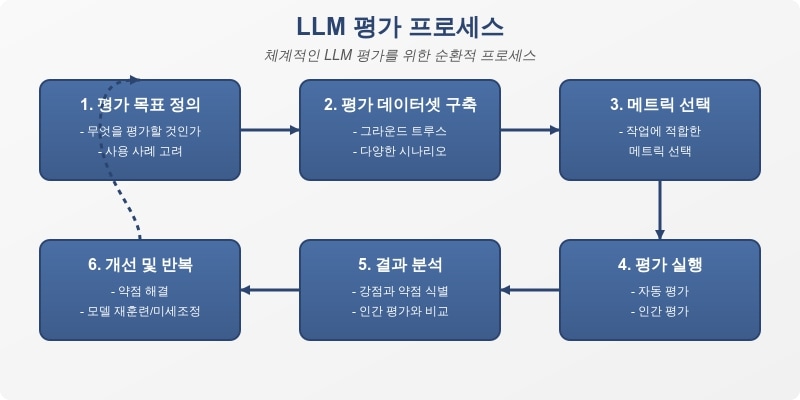
LLM 평가의 모든 것: 메트릭, 방법론, 그리고 실전 가이드
대규모 언어 모델(LLM)의 성능을 객관적으로 평가하는 방법을 알아봅니다. 전통적인 메트릭부터 최신 의미론적 평가 방법까지, LLM 평가의 모든 것을 포괄적으로 다루는 실용적인 가이드입니다.
Written by