대규모 언어 모델(Large Language Models, LLMs)은 현대 AI 기술의 핵심으로 자리 잡았습니다. ChatGPT, Claude, Bard와 같은 서비스부터 기업 내부의 맞춤형 AI 시스템까지, LLM은 우리의 삶과 비즈니스 환경을 빠르게 변화시키고 있습니다. 이러한 모델들의 능력이 발전함에 따라 그 성능을 객관적으로 평가하는 것은 매우 중요한 과제가 되었습니다.
LLM은 문서 작성, 코드 생성, 질문 응답, 번역 등 다양한 작업을 수행할 수 있습니다. 그러나 이러한 다재다능함은 평가를 복잡하게 만드는 요소이기도 합니다. 단일 척도로 LLM의 모든 측면을 측정하는 것은 거의 불가능하기 때문에, 다양한 평가 메트릭과 방법론이 개발되어 왔습니다.
이 글에서는 LLM 평가의 핵심 개념부터 주요 메트릭, 실전 평가 전략까지 포괄적으로 다루겠습니다. 개발자, 연구자, 그리고 AI 도입을 고려하는 비즈니스 리더들이 LLM의 능력을 객관적으로 측정하고 비교할 수 있는 실용적인 지식을 제공하는 것이 이 글의, 목표입니다.
LLM 평가의 기본 개념
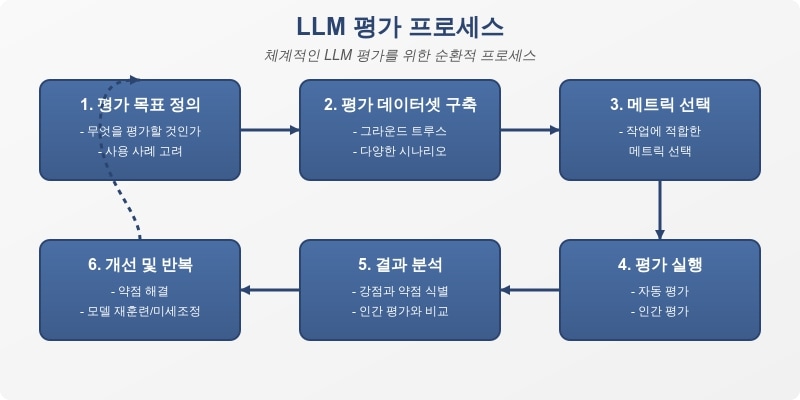
LLM 평가 프로세스
LLM 평가는 체계적인 프로세스를 통해 이루어집니다. 아래 다이어그램은 효과적인 LLM 평가 프로세스의 주요 단계를 보여줍니다.

이 프로세스는 순환적이며, 모델 개발 주기 전반에 걸쳐 지속적으로 반복됩니다. 각 단계는 다음과 같은 중요한 요소를 포함합니다:
- 평가 목표 정의: 명확한 평가 목표와 기준을 설정합니다.
- 평가 데이터셋 구축: 다양한 시나리오와 사용 사례를 포함하는 대표적인 데이터셋을 만듭니다.
- 메트릭 선택: 평가 목표에 적합한 메트릭을 선택하고 필요에 따라 여러 메트릭을 조합합니다.
- 평가 실행: 자동화된 메트릭과 인간 평가를 모두 사용하여 포괄적인 평가를 수행합니다.
- 결과 분석: 모델의 강점과 약점을 분석하고 개선 영역을 식별합니다.
- 개선 및 반복: 분석 결과를 바탕으로 모델을 개선하고 평가 프로세스를 반복합니다.
이 체계적인 접근 방식은 LLM의 성능을 지속적으로 개선하고 사용자 요구를 충족시키는 데 필수적입니다.
평가가 필요한 이유필요한 이유
LLM 평가가 중요한 이유는 다음과 같습니다:
- 성능 측정 및 벤치마킹: 개발 단계에서 모델의 성능을 명확히 측정할 수 있습니다. 다양한 메트릭과 평가 기법을 통해 시스템의 능력을 벤치마킹하고, 다른 버전의 모델과 비교하며 다양한 아키텍처 및 설계 선택의 영향을 이해할 수 있습니다.
- 회귀 방지: 모델이 지속적으로 개발됨에 따라 코드베이스, 모델 매개변수 또는 데이터의 변경으로 인해 의도치 않게 성능이나 정확도가 저하될 수 있습니다. 정기적인 평가는 각 수정이 성능 표준을 향상시키거나 최소한 유지하도록 보장합니다.
- 결과물의 신뢰성 확보: 최종 사용자와 이해관계자들은 LLM 시스템의 출력을 신뢰할 수 있어야 합니다. 체계적인 평가는 모델이 일관되고 신뢰할 수 있는 결과를 제공한다는 확신을 줍니다.
- 개선 방향 설정: 평가 결과는 모델의 강점과 약점을 식별하는 데 도움이 되며, 이는 향후 개발 노력을 집중해야 할 영역을 파악하는 데 중요합니다.
사전 배포 평가 vs 배포 후 평가
LLM 평가는 크게 사전 배포(pre-deployment) 평가와 배포 후(post-deployment) 평가로 나눌 수 있습니다.
사전 배포 평가는 개발 과정에서 모델의 성능과 신뢰성을 평가하는 것에 중점을 둡니다. 이 단계는 시스템이 실제 환경에 적용되기 전 성능을 형성하는 데 중요합니다. 주요 목적은:
- 개발 중인 모델의 다양한 측면을 벤치마킹하고 성능을 측정
- 모델 업데이트가 기존 성능을 저하시키지 않도록 보장(회귀 방지)
- 실제 환경에 배포하기 전 모델의 강점과 약점 식별
배포 후 평가는 실제 사용자 환경에서 모델의 성능을 모니터링하고 평가합니다:
- 실제 사용자 쿼리와 상호작용에 대한 모델의 응답 품질 측정
- 사용자 피드백을 수집하여 모델의 유용성과 효과성 평가
- 새로운 데이터와 사용 사례에 대한 모델의 적응성 모니터링
성공적인 LLM 평가 전략은 두 평가 유형을 모두 포함해야 하며, 이를 통해 개발부터 실제 사용까지 모든 단계에서 모델의 성능을 최적화할 수 있습니다.
그라운드 트루스(Ground Truth) 데이터셋의 중요성

LLM 시스템을 평가하는 첫 번째이자 가장 중요한 단계는 견고한 그라운드 트루스 데이터셋을 만드는 것입니다. 이 데이터셋은 전문 인력이 생성한 질문-답변 쌍으로 구성되며, LLM의 성능을 평가하는 벤치마크 역할을 합니다.
그라운드 트루스 데이터는 다음과 같은 이유로 필수적입니다:
- 참조 포인트 제공: 모델의 출력을 비교할 수 있는 기준점을 제공합니다.
- 다양성 확보: 실제 사용자가 프로덕션 환경에서 물을 가능성이 높은 질문 유형을 대표하며, 다양한 시나리오와 맥락을 포함해야 합니다.
- 도메인 전문성 반영: 비즈니스 도메인과 사용자 행동에 대한 깊은 이해를 가진 인력의 전문성이 필요합니다.
중요한 점은 LLM이 그라운드 트루스 데이터 생성에 도움을 줄 수는 있지만, 단독으로 의존해서는 안 된다는 것입니다. LLM은 사용자 행동을 이해하지 못하고 비즈니스 도메인의 특정 맥락을 파악하지 못하기 때문에, 사람의 검토와 수정이 필요합니다.
훌륭한 그라운드 트루스 데이터셋 예시로는 Hugging Face의 rag-mini-bioasq가 있으며, 이는 지식 베이스에서 쿼리와 관련된 다양한 텍스트 구절을 제공합니다.
다양한 평가 메트릭의 유형과 목적
LLM을 평가하기 위한 메트릭은 다양하며, 각각 모델 성능의 서로 다른 측면을 측정합니다:
- 응답 관련성(Answer Relevancy): 제공된 답변이 주어진 질문에 얼마나 관련이 있는지 측정합니다. 응답이 쿼리를 직접 다루고 유용하고 적절한 정보를 제공하는지 평가합니다.
- 일관성(Coherence): 생성된 텍스트의 논리적 흐름과 명확성을 평가합니다. 응답이 내부적으로 일관되고 전체적으로 의미가 있는지 확인합니다.
- 맥락 관련성(Contextual Relevance): 모델의 출력이 제공된 더 넓은 맥락과 얼마나 잘 일치하는지 측정합니다. 응답이 주변 텍스트나 대화를 적절하게 고려하는지 평가합니다.
- 책임감 메트릭(Responsibility Metrics): 모델 출력의 윤리적이고 적절한 특성을 평가합니다. 여기에는 편향, 유해한 콘텐츠, 그리고 윤리적 기준 준수 여부를 확인하는 것이 포함됩니다.
- RAG 평가 메트릭(RAG Evaluation Metrics): 검색 증강 생성(Retrieval-Augmented Generation) 시스템의 경우, 관련 문서를 검색하고 그 정보를 바탕으로 응답을 생성하는 능력을 평가합니다.
이러한 메트릭을 적절히 조합하여 사용하면 LLM 시스템의 다양한 측면을 포괄적으로 평가할 수 있습니다.
주요 LLM 평가 메트릭 심층 분석
LLM 평가에는 다양한 메트릭이 사용되며, 각각은 모델 성능의 특정 측면을 측정합니다. 여기서는 가장 널리 사용되는 세 가지 카테고리의 메트릭을 심층적으로 살펴보겠습니다.
전통적 메트릭: BLEU, ROUGE
BLEU(Bilingual Evaluation Understudy)와 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)는 자연어 생성 작업의 평가에 가장 널리 사용되는 전통적인 메트릭입니다.
BLEU는 기계 번역을 위해 개발되었지만 다양한 텍스트 생성 작업에 사용됩니다. 이 메트릭은 모델의 번역(가설)과 참조 번역 사이의 n-gram 중첩을 측정합니다.
import evaluate
def evaluate_machine_translation(hypotheses, references):
"""기계 번역을 위한 BLEU 점수 계산"""
bleu_metric = evaluate.load("bleu")
results = bleu_metric.compute(predictions=hypotheses, references=references)
# 주요 BLEU 점수 추출
bleu_score = results["bleu"]
return bleu_score
# 예시 가설(모델 번역)
hypotheses = ["고양이가 매트 위에 앉았다.", "개가 정원에서 놀았다."]
# 예시 참조(정확한 번역, 가설당 여러 개 가능)
references = [["고양이가 매트 위에 앉아 있었다."], ["개가 정원에서 놀고 있었다."]]
bleu_score = evaluate_machine_translation(hypotheses, references)
print(f"BLEU 점수: {bleu_score:.4f}")ROUGE는 주로 요약 작업의 평가에 사용되며, 생성된 요약과 참조 요약 간의 n-gram 중첩과 최장 공통 부분 시퀀스를 비교합니다.
import evaluate
# ROUGE 메트릭 로드
rouge_metric = evaluate.load("rouge")
# 예시 텍스트 및 참조 요약
text = "오늘은 아름다운 날이다. 태양이 빛나고 새들이 노래한다. 나는 공원에서 산책할 것이다."
reference = "오늘은 날씨가 좋다."
# 간단한 함수를 사용하여 요약 생성
def simple_summarizer(text):
"""매우 기본적인 요약기 - 첫 문장만 가져옴"""
try:
sentences = text.split(".")
return sentences[0].strip() + "." if sentences[0].strip() else ""
except:
return "" # 빈 텍스트나 잘못된 형식 처리
# 간단한 함수를 사용하여 요약 생성
prediction = simple_summarizer(text)
print(f"생성된 요약: {prediction}")
print(f"참조 요약: {reference}")
# ROUGE 점수 계산
rouge_results = rouge_metric.compute(predictions=[prediction], references=[reference])
print(f"ROUGE 점수: {rouge_results}")이러한 전통적인 메트릭은 단어나 n-gram 일치를 기반으로 하기 때문에 제한적이며, 의미적 유사성을 완전히 포착하지 못할 수 있습니다.
복잡도 기반 메트릭: Perplexity
Perplexity(복잡도)는 언어 모델이 얼마나 잘 텍스트 시퀀스를 예측하는지 측정하는 기본적이면서도 강력한 메트릭입니다. 간단히 말해, perplexity는 모델이 텍스트를 만났을 때 얼마나 “놀라거나” “혼란스러워하는지”를 수치화합니다. perplexity가 낮을수록 모델이 샘플 텍스트를 더 잘 예측하고 있다는 의미입니다.

Perplexity는 다음과 같이 수학적으로 정의됩니다:
$$
\text{Perplexity}(W) = 2^{-\frac{1}{N} \sum_{i=1}^{N} \log_2 P(w_i|w_1, w_2, …, w_{i-1})}
$$
여기서:
- $W$는 테스트 시퀀스 $(w_1, w_2, …, w_N)$
- $N$은 시퀀스의 단어 수
- $P(w_i|w_1, w_2, …, w_{i-1})$는 이전 단어들이 주어졌을 때 단어 $w_i$의 조건부 확률
Python으로 간단한 n-gram 언어 모델과 perplexity 계산을 구현해 보겠습니다:
import numpy as np
from collections import Counter, defaultdict
class NgramLanguageModel:
def __init__(self, n=2):
self.n = n
self.context_counts = defaultdict(Counter)
self.context_totals = defaultdict(int)
def train(self, corpus):
"""코퍼스에서 언어 모델 학습"""
# 시작 및 종료 토큰 추가
tokens = ['<s>'] * (self.n - 1) + corpus + ['</s>']
# n-gram 계산
for i in range(len(tokens) - self.n + 1):
context = tuple(tokens[i:i+self.n-1])
word = tokens[i+self.n-1]
self.context_counts[context][word] += 1
self.context_totals[context] += 1
def probability(self, word, context):
"""단어와 컨텍스트가 주어졌을 때 확률 계산"""
if self.context_totals[context] == 0:
return 1e-10 # 보지 못한 컨텍스트에 대한 스무딩
return (self.context_counts[context][word] + 1) / (self.context_totals[context] + len(self.context_counts))
def perplexity(self, test_sequence):
"""테스트 시퀀스의 perplexity 계산"""
N = len(test_sequence) + 1 # 종료 토큰을 위해 +1
log_prob = 0.0
tokens = ['<s>'] * (self.n - 1) + test_sequence + ['</s>']
for i in range(len(tokens) - self.n + 1):
context = tuple(tokens[i:i+self.n-1])
word = tokens[i+self.n-1]
prob = self.probability(word, context)
log_prob += np.log2(prob)
return 2 ** (-log_prob / N)
# 테스트
def tokenize(text):
"""공백으로 분리하는 간단한 토큰화"""
return text.lower().split()
# 예시 사용
corpus = tokenize("고양이가 매트 위에 앉았다 개가 고양이를 쫓았다 고양이가 도망갔다")
test = tokenize("고양이가 매트 위에 앉았다")
model = NgramLanguageModel(n=2)
model.train(corpus)
print(f"테스트 시퀀스의 perplexity: {model.perplexity(test):.2f}")Perplexity의 주요 장점은 다음과 같습니다:
- 해석 가능성: 예측 작업의 평균 분기 요인으로 명확한 해석이 가능합니다.
- 모델 불가지론적: 시퀀스에 확률을 할당하는 모든 확률적 언어 모델에 적용할 수 있습니다.
- 인간 주석 불필요: 다른 많은 평가 메트릭과 달리 인간이 주석을 단 참조 텍스트가 필요하지 않습니다.
그러나 한계점도 있습니다:
- 어휘 의존성: 같은 어휘를 사용하는 모델 간에만 perplexity 점수를 직접 비교할 수 있습니다.
- 인간 판단과의 불일치: 낮은 perplexity가 항상 인간 평가에서 더 나은 품질로 해석되지는 않습니다.
- 의미 이해 부족: 모델은 실제 이해 없이 n-gram을 암기함으로써 낮은 perplexity를 달성할 수 있습니다.
주요 LLM 평가 메트릭 비교
다양한 LLM 평가 메트릭을 쉽게 비교할 수 있도록 아래 표에 주요 특징을 정리했습니다.
| 메트릭 | 측정 내용 | 장점 | 단점 | 적합한 태스크 | 계산 복잡도 | 인간 평가와의 상관관계 |
|---|---|---|---|---|---|---|
| BLEU | N-gram 일치 기반 정밀도 | 빠르고 해석 가능, 널리 사용됨 | 문맥과 의미 이해 부족, 위치에 무관 | 기계 번역, 텍스트 생성 | 낮음 | 중간 |
| ROUGE | 참조 텍스트의 N-gram 포함 비율(재현율) | 텍스트 생성 품질 측정에 효과적 | 유창성과 문법 평가 부족 | 텍스트 요약, 생성 | 낮음 | 중간 |
| Perplexity | 모델이 텍스트 시퀀스를 예측하는 정확도 | 계산이 빠르고 참조 필요 없음 | 같은 어휘 모델간에만 비교 가능, 인간 판단과 불일치 | 언어 모델링, 생성 품질 | 중간 | 낮음-중간 |
| BERTScore | 문맥적 임베딩 기반 의미적 유사성 | 의미적 이해 포착, 유의어 처리 | 계산 비용 높음, 언어 모델 품질에 의존 | 생성 품질, 번역, 요약 | 높음 | 높음 |
| METEOR | 단어 매칭(동의어, 어간 매칭 포함) | 유연한 매칭, 의미적 유사성 고려 | 계산 복잡도 높음 | 기계 번역 | 중간 | 중간-높음 |
| SQuAD | 정답 텍스트 추출 성능 | QA 태스크 평가에 특화 | 추출적 QA에만 적합 | 질문 응답 | 중간 | 높음 |
| BLEURT | 학습된 신경망 기반 품질 측정 | 맥락 이해 및 인간 선호도 학습 | 학습 데이터와 계산 자원 필요 | 번역, 요약, 생성 | 매우 높음 | 매우 높음 |
| LLM-as-Judge | 다른 LLM이 결과물 평가 | 복잡한 측면 평가 가능, 맞춤형 기준 | 높은 비용, 평가 LLM의 편향 가능성 | 다양한 생성 태스크 | 매우 높음 | 매우 높음 |
이 표를 통해 다양한 메트릭의 특성을 비교하여 특정 평가 상황에 가장 적합한 메트릭을 선택하는 데 도움이 될 수 있습니다. 실제 평가에서는 여러 메트릭을 함께 사용하는 것이 더 포괄적인 결과를 얻는 데 도움이 됩니다.
의미론적 메트릭: BERTScore
전통적인 n-gram 기반 메트릭(BLEU, ROUGE)이 의미적 유사성을 완전히 포착하지 못하는 한계를 극복하기 위해, BERTScore와 같은 의미론적 메트릭이 개발되었습니다.

BERTScore는 BERT와 같은 사전 훈련된 언어 모델의 문맥적 임베딩을 사용하여 후보 텍스트와 참조 텍스트 간의 유사성 점수를 계산하는 신경망 평가 메트릭입니다. 이 방법의 핵심 단계는 다음과 같습니다:
- 토큰화: 후보(생성된) 텍스트와 참조 텍스트를 사용 중인 사전 훈련 모델의 토크나이저를 사용하여 토큰화합니다.
- 문맥적 임베딩: 각 토큰은 사전 훈련된 문맥 모델을 사용하여 임베딩됩니다. 이 임베딩은 정적 단어 표현이 아닌 문맥에서의 단어 의미를 포착합니다.
- 코사인 유사도 계산: 후보 텍스트의 각 토큰에 대해, BERTScore는 참조 텍스트의 모든 토큰과의 코사인 유사도를 계산하여 유사도 행렬을 생성합니다.
- 탐욕적 매칭:
- 정밀도(Precision): 각 후보 토큰은 가장 유사한 참조 토큰과 매칭됩니다.
- 재현율(Recall): 각 참조 토큰은 가장 유사한 후보 토큰과 매칭됩니다.
- 점수 집계:
- 정밀도는 각 후보 토큰에 대한 최대 유사도 점수의 평균으로 계산됩니다.
- 재현율은 각 참조 토큰에 대한 최대 유사도 점수의 평균으로 계산됩니다.
- F1 점수는 정밀도와 재현율의 조화 평균으로 계산됩니다.
Python에서 BERTScore를 사용하는 방법은 다음과 같습니다:
import bert_score
# 참조 및 후보 텍스트 정의
references = ["고양이가 매트 위에 앉았다.", "고양이가 바닥 덮개 위에서 쉬었다."]
candidates = ["한 고양이가 매트 위에 앉아 있었다.", "고양이가 매트 위에 있었다."]
# BERTScore 계산
P, R, F1 = bert_score.score(
candidates,
references,
lang="ko",
model_type="bert-base-multilingual-cased",
verbose=True
)
# 결과 출력
for i, (p, r, f) in enumerate(zip(P, R, F1)):
print(f"예시 {i+1}:")
print(f" 정밀도: {p.item():.4f}")
print(f" 재현율: {r.item():.4f}")
print(f" F1: {f.item():.4f}")
print()BERTScore의 주요 장점은 다음과 같습니다:
- 의미적 유사성 포착: 어휘적 중복을 넘어 의미적 유사성을 포착합니다.
- 인간 판단과의 상관관계: 다른 n-gram 기반 메트릭보다 인간 판단과 더 높은 상관관계를 보입니다.
- 다양한 작업 및 도메인 적용 가능: 번역, 요약, 대화 시스템 등 다양한 작업에서 잘 작동합니다.
- 자연스러운 동의어 및 의역 처리: 같은 의미를 전달하는 다른 표현을 인식할 수 있습니다.
그러나 한계점도 있습니다:
- 계산 비용: n-gram 메트릭보다 계산적으로 더 많은 리소스가 필요합니다.
- 기본 임베딩 품질에 의존: 성능은 사용된 기본 임베딩의 품질에 따라 달라집니다.
- 구조적 또는 논리적 일관성 포착 부족: 텍스트의 전체적인 구조나 논리를 항상 포착하지는 못할 수 있습니다.
Hugging Face Evaluate 라이브러리 활용 가이드

Hugging Face Evaluate 라이브러리는 자연어 처리(NLP) 모델의 평가를 쉽게 할 수 있는 다양한 도구를 제공합니다. 이 섹션에서는 이 라이브러리를 활용하여 LLM을 평가하는 방법을 단계별로 알아보겠습니다.
라이브러리 소개 및 설치
Hugging Face Evaluate 라이브러리는 세 가지 주요 범주의 평가 도구를 제공합니다:
- 메트릭(Metrics): 모델의 예측을 그라운드 트루스 레이블과 비교하여 성능을 측정합니다. 예: accuracy, F1-score, BLEU, ROUGE 등.
- 비교(Comparisons): 두 모델을 비교하는 데 도움이 됩니다.
- 측정(Measurements): 데이터셋 자체의 속성을 조사합니다(텍스트 복잡성, 레이블 분포 등).
설치 방법:
pip install evaluate
pip install rouge_score # 텍스트 생성 메트릭에 필요
pip install evaluate[visualization] # 시각화 기능을 위한 선택적 종속성기본 사용법 및 주요 기능
평가 모듈을 사용하려면 이름으로 로드합니다:
import evaluate
# 정확도 메트릭 로드
accuracy_metric = evaluate.load("accuracy")
print("정확도 메트릭이 로드되었습니다.")
# 직접 계산 예시
references = [0, 1, 0, 1] # 정답
predictions = [1, 0, 0, 1] # 모델의 예측
result = accuracy_metric.compute(references=references, predictions=predictions)
print(f"직접 계산 결과: {result}")대규모 데이터셋의 경우, 배치 처리가 메모리 효율적입니다:
# 증분 평가(배치 단위) 예시
accuracy_metric = evaluate.load("accuracy")
# 샘플 배치
references_batch1 = [0, 1]
predictions_batch1 = [1, 0]
references_batch2 = [0, 1]
predictions_batch2 = [0, 1]
# 배치 단위로 추가
accuracy_metric.add_batch(references=references_batch1, predictions=predictions_batch1)
accuracy_metric.add_batch(references=references_batch2, predictions=predictions_batch2)
# 최종 정확도 계산
final_result = accuracy_metric.compute()
print(f"증분 계산 결과: {final_result}")
# 여러 메트릭 결합
clf_metrics = evaluate.combine(["accuracy", "f1", "precision", "recall"])
# 샘플 데이터
predictions = [0, 1, 0]
references = [0, 1, 1] # 주의: 마지막 예측은 잘못됨
# 모든 메트릭 한번에 계산
results = clf_metrics.compute(predictions=predictions, references=references)
print(f"결합된 메트릭 결과: {results}")다양한 NLP 작업별 평가 예시
LLM은 다양한 NLP 작업을 수행할 수 있으며, 각 작업에 맞는 평가 방법이 필요합니다. Hugging Face Evaluate는 여러 표준 메트릭을 제공합니다.
1. 기계 번역 (BLEU)
import evaluate
def evaluate_machine_translation(hypotheses, references):
"""기계 번역을 위한 BLEU 점수 계산"""
bleu_metric = evaluate.load("bleu")
results = bleu_metric.compute(predictions=hypotheses, references=references)
# 주요 BLEU 점수 추출
bleu_score = results["bleu"]
return bleu_score
# 예시 가설(모델 번역)
hypotheses = ["고양이가 매트 위에 앉았다.", "개가 정원에서 놀았다."]
# 예시 참조(정확한 번역, 가설당 여러 개 가능)
references = [["고양이가 매트 위에 앉아 있었다."], ["개가 정원에서 놀고 있었다."]]
bleu_score = evaluate_machine_translation(hypotheses, references)
print(f"BLEU 점수: {bleu_score:.4f}")2. 개체명 인식(NER – seqeval 사용)
import evaluate
# seqeval 메트릭 로드
try:
seqeval_metric = evaluate.load("seqeval")
# 예시 레이블(IOB 형식 사용)
true_labels = [['O', 'B-PER', 'I-PER', 'O'], ['B-LOC', 'I-LOC', 'O']]
predicted_labels = [['O', 'B-PER', 'I-PER', 'O'], ['B-LOC', 'I-LOC', 'O']] # 완벽한 예측 예시
results = seqeval_metric.compute(predictions=predicted_labels, references=true_labels)
print("Seqeval 결과(개체 유형별):")
for key, value in results.items():
if isinstance(value, dict):
print(f" {key}: 정밀도={value['precision']:.2f}, 재현율={value['recall']:.2f}, F1={value['f1']:.2f}, 개수={value['number']}")
else:
print(f" {key}: {value:.4f}")
except ModuleNotFoundError:
print("Seqeval 메트릭이 설치되지 않았습니다. 실행: pip install seqeval")3. 텍스트 요약 (ROUGE)
import evaluate
# 매우 기본적인 요약기 - 단순히 첫 문장을 가져옴
def simple_summarizer(text):
try:
sentences = text.split(".")
return sentences[0].strip() + "." if sentences[0].strip() else ""
except:
return "" # 빈 텍스트나 잘못된 형식 처리
# ROUGE 메트릭 로드
rouge_metric = evaluate.load("rouge")
# 예시 텍스트 및 참조 요약
text = "오늘은 아름다운 날이다. 태양이 빛나고 새들이 노래한다. 나는 공원에서 산책할 것이다."
reference = "오늘은 날씨가 좋다."
# 간단한 함수를 사용하여 요약 생성
prediction = simple_summarizer(text)
print(f"생성된 요약: {prediction}")
print(f"참조 요약: {reference}")
# ROUGE 점수 계산
rouge_results = rouge_metric.compute(predictions=[prediction], references=[reference])
print(f"ROUGE 점수: {rouge_results}")4. 질문 응답 (SQuAD)
import evaluate
# SQuAD 메트릭 로드
squad_metric = evaluate.load("squad")
# SQuAD용 예시 예측 및 참조 형식
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
print(f"SQuAD 결과: {results}")결과 시각화 및 저장 방법
평가 결과를 시각화하는 것은 여러 모델 간의 성능을 비교하는 데 도움이 됩니다. 레이더 플롯은 이를 위한 효과적인 방법입니다:
import evaluate
import matplotlib.pyplot as plt
from evaluate.visualization import radar_plot
# 여러 모델의 다양한 메트릭에 대한 샘플 데이터
# 낮은.지연 시간이 더 좋으므로 반전시킬 수 있습니다.
data = [
{"accuracy": 0.99, "precision": 0.80, "f1": 0.95, "latency_inv": 1/33.6},
{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_inv": 1/11.2},
{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_inv": 1/87.6},
{"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_inv": 1/101.6}
]
model_names = ["모델 A", "모델 B", "모델 C", "모델 D"]
# 레이더 플롯 생성
try:
plot = radar_plot(data=data, model_names=model_names)
# 파일로 저장 (선택 사항)
# plot.savefig("model_comparison_radar.png")
plt.close() # 표시/저장 후 플롯 창 닫기
except ImportError:
print("시각화를 위해 matplotlib이 필요합니다. 실행: pip install matplotlib")
except Exception as e:
print(f"플롯을 생성할 수 없습니다: {e}")평가 결과를 저장하는 것은 기록 보관이나 나중에 분석하기 위해 중요합니다:
import evaluate
from pathlib import Path
import json
# 평가 수행
accuracy_metric = evaluate.load("accuracy")
result = accuracy_metric.compute(references=[0, 1, 0, 1], predictions=[1, 0, 0, 1])
print(f"저장할 결과: {result}")
# 하이퍼파라미터 또는 기타 메타데이터 정의
hyperparams = {"model_name": "my_custom_model", "learning_rate": 0.001}
run_details = {"experiment_id": "run_42"}
# 결과 및 메타데이터 결합
save_data = {**result, **hyperparams, **run_details}
# 저장 디렉토리 및 파일 이름 정의
save_dir = Path("./evaluation_results")
save_dir.mkdir(exist_ok=True) # 디렉토리가 없으면 생성
# JSON으로 수동 저장
manual_save_path = save_dir / "manual_results.json"
with open(manual_save_path, 'w') as f:
json.dump(save_data, f, indent=4)
print(f"결과가 다음 위치에 수동으로 저장되었습니다: {manual_save_path}")실전 LLM 평가 전략
목적에 맞는 메트릭 선택 방법
평가할 LLM과 작업에 적합한 메트릭을 선택하는 것은 중요한 결정입니다. 메트릭 선택 시 고려해야 할 요소는 다음과 같습니다:
- 작업 유형: 평가하려는 작업의 특성을 고려하세요.
- 분류: Accuracy, F1, Precision, Recall
- 번역/생성: BLEU, ROUGE, BERTScore
- 개체명 인식: Seqeval(F1)
- 질문 응답: SQuAD, Exact Match
- 언어 모델링: Perplexity
- 데이터셋: 특정 벤치마크(GLUE, SQuAD 등)에는 관련 메트릭이 있을 수 있습니다.
- 목표: 성능의 어떤 측면이 가장 중요한가요?
- 정확도: 전반적인 정확성(균형 잡힌 클래스에 적합)
- 정밀도/재현율/F1: 불균형 클래스나 거짓 양성/음성의 비용이 다를 때 중요
- BLEU/ROUGE: 텍스트 생성의 유창성 및 내용 중복
- Perplexity: 언어 모델이 샘플을 예측하는 정도(낮을수록 좋음)
- 해석 가능성: 메트릭이 얼마나 이해하기 쉬운가요?
- 계산 비용: 평가가 얼마나 계산 집약적인가요?
다중 메트릭 접근법
단일 메트릭은 LLM의 성능을 완전히 포착하지 못하는 경우가 많습니다. 다중 메트릭 접근법의 이점:
- 포괄적인 평가: 다양한 각도에서 모델 성능을 평가할 수 있습니다.
- 강점과 약점 식별: 서로 다른 메트릭은 다양한 성능 측면을 강조할 수 있습니다.
- 모델 선택에 도움: 특정 요구 사항에 따라 가중치를 부여할 수 있습니다.
다중 메트릭 평가 구현:
import evaluate
# 다양한 메트릭 로드
metrics = {
"accuracy": evaluate.load("accuracy"),
"f1": evaluate.load("f1"),
"precision": evaluate.load("precision"),
"recall": evaluate.load("recall")
}
# 샘플 데이터
predictions = [0, 1, 0, 1, 0]
references = [0, 1, 0, 0, 1] # 두 개의 오류 포함
# 종합 결과 사전 생성
results = {}
for metric_name, metric in metrics.items():
results[metric_name] = metric.compute(predictions=predictions, references=references)
print("다중 메트릭 평가 결과:")
for metric_name, value in results.items():
print(f" {metric_name}: {value}")또는 evaluate.combine 함수를 사용하여 더 간단히 구현할 수 있습니다:
# 또는 combine 함수 사용
combined_metrics = evaluate.combine(["accuracy", "f1", "precision", "recall"])
combined_results = combined_metrics.compute(predictions=predictions, references=references)
print(f"결합된 결과: {combined_results}")평가 데이터셋 구축 전략
효과적인 평가 데이터셋 구축을 위한 전략:
- 대표성: 데이터셋은 실제 사용 사례와 사용자 쿼리의 다양성을 반영해야 합니다.
- 균형: 다양한 주제, 질문 유형, 난이도 수준을 포함해야 합니다.
- 편향 방지: 다양한 인구통계학적 그룹과 관점을 포함하고 특정 집단에 대한 편향을 방지하세요.
- 어려운 사례 포함: 모서리 사례, 복잡한 쿼리, 오해의 소지가 있는 질문을 포함하여 모델의 한계를 테스트하세요.
- 도메인 전문성 활용: 도메인 전문가들이 데이터셋 구축에 참여하게 하여 품질과 관련성을 보장하세요.
- 정기적 업데이트: 사용자 피드백, 새로운 사용 사례, 시간 경과에 따른 변화를 반영하여 데이터셋을 업데이트하세요.
- 누적 평가: 모델을 지속적으로 개선하면서 이전 버전에서 발견된 약점을 새 데이터셋에 통합하세요.
인기 있는 LLM 평가 데이터셋 예시
다음은 LLM 평가에 널리 사용되는 몇 가지 공개 데이터셋입니다:
| 데이터셋 | 설명 | 태스크 | 특징 |
|---|---|---|---|
| MMLU (Massive Multitask Language Understanding) | 다양한 학문 분야의 지식을 평가하는 57개 주제의 문제 모음 | 지식 평가, 다중 선택 QA | 고등 교육 수준의 전문 지식 평가 |
| BIG-bench | 200개 이상의 다양한 작업을 포함하는 벤치마크 | 다양한 추론 능력, 언어 이해 | 포괄적인 능력 평가, 작업별 세부 분석 가능 |
| HELM (Holistic Evaluation of Language Models) | 다양한 태스크와 메트릭을 포함하는 종합 벤치마크 | 다양한 언어 작업 | 공정성, 견고성, 정확성 등 종합 평가 |
| TruthfulQA | 모델이 얼마나 진실되고 정확한 정보를 제공하는지 평가 | 사실 검증, QA | 거짓 정보와 오해의 소지가 있는 질문 포함 |
| HumanEval | 프로그래밍 문제를 통해 코드 생성 능력 평가 | 코드 생성 | 함수 설명을 기반으로 코드 구현 테스트 |
| GSM8K | 초등학교 수준의 수학 문제 모음 | 수학적 추론 | 단계적 추론 능력 평가 |
이러한 데이터셋을 활용하면 다양한 각도에서 LLM의 성능을 평가할 수 있습니다. 자체 평가 데이터셋을 구축할 때도 이러한 공개 데이터셋의 구조와 접근 방식을 참고하면 도움이 됩니다.
LLM-as-a-Judge 등 최신 평가 방법론

“LLM-as-a-Judge” 접근법은 강력한 LLM을 평가자로 활용하여 다른 모델의 출력을 평가하는 혁신적인 방법입니다:
- 원리: 더 강력한 LLM을 사용하여 다른 언어 모델의 출력을 평가합니다.
- 구현:
- 평가할 모델을 사용하여 텍스트 생성
- 평가 기준과 함께 이 텍스트를 “심사” LLM에 제공
- 심사 LLM이 생성된 텍스트에 점수를 매기거나 순위를 매김
- 장점:
- 일관성, 사실성, 관련성과 같은 측면을 평가할 수 있음
- 인간 판단과 더 잘 일치함
- 특정 평가 기준에 맞게 맞춤화 가능
- 구현 예시:
def llm_as_judge(generated_text, reference_text=None, criteria="일관성과 유창성"):
"""LLM을 사용하여 생성된 텍스트 평가"""
# 이것은 간단한 예시입니다 - 실제로는 실제 LLM API를 호출할 것입니다
if reference_text:
prompt = f"""
다음 생성된 텍스트를 {criteria}에 기반하여 평가해 주세요.
참조 텍스트: {reference_text}
생성된 텍스트: {generated_text}
1-10점으로 점수를 매기고 이유를 제공해 주세요.
"""
else:
prompt = f"""
다음 생성된 텍스트를 {criteria}에 기반하여 평가해 주세요.
생성된 텍스트: {generated_text}
1-10점으로 점수를 매기고 이유를 제공해 주세요.
"""
# 실제 구현에서는 LLM API를 호출할 것입니다
# response = llm_api.generate(prompt)
# return parse_score(response)
# 시연 목적으로만 사용:
import random
score = random.uniform(1, 10)
return score
# 예시 사용
gen_text = "인공지능은 빠르게 발전하고 있으며, 우리 일상생활의 여러 측면에 영향을 미치고 있습니다."
reference = "AI 기술은 급속도로 성장하고 있으며 일상 생활에 많은 변화를 가져오고 있습니다."
score = llm_as_judge(gen_text, reference)
print(f"LLM 심사 점수: {score:.2f}/10")이 방법은 perplexity와 같은 전통적 메트릭의 한계를 보완하여 텍스트 품질에 대한 인간과 유사한 판단을 여러 차원에서 제공합니다.
LLM 평가의 한계 및 향후 전망
현재 평가 방법론의 한계점
현재 LLM 평가 방법에는 여러 한계가 있습니다:
- 작업 특정성 부족: 많은 메트릭은 특정 작업이나 목표에 맞게 조정되지 않았습니다.
- 명시적-암시적 격차: 대부분의 메트릭은 명시적으로 요청된 내용만 평가하고, LLM의 암시적인 추론 능력은 평가하지 않습니다.
- 편향성 문제: 평가 데이터셋과 메트릭 자체에 편향이 있을 수 있으며, 이는 불공정한 결과로 이어질 수 있습니다.
- 인간 판단과의 불일치: 많은 자동 메트릭은 LLM 출력의 질에 대한 인간의 판단과 완전히 일치하지 않습니다.
- 문맥 고려 부족: 대부분의 메트릭은 더 넓은 대화 또는 문서 맥락에서 응답의 적절성을 완전히 포착하지 못합니다.
- 진화하는 모델 아키텍처: 모델 아키텍처가 발전함에 따라 기존 평가 방법은 더 이상 적합하지 않을 수 있습니다.
- 멀티모달 능력 평가: 텍스트 외에도 이미지, 오디오, 비디오를 처리하는 LLM의 능력을 평가하는 것은 추가적인 복잡성을 가집니다.
인간의 판단과의 상관관계
이상적으로, 자동화된 LLM 평가 메트릭은 인간의 판단과 높은 상관관계를 가져야 합니다. 현재 상황:
- 전통적 메트릭의 상관관계: BLEU, ROUGE와 같은 n-gram 기반 메트릭은 인간 판단과 중간 정도의 상관관계를 보입니다.
- 의미적 메트릭의 개선: BERTScore와 같은 임베딩 기반 메트릭은, 언어의 의미적 측면을 더 잘 포착하기 때문에 일반적으로 더 나은 상관관계를 보입니다.
- 맥락에 따른 변동: 상관관계는 작업, 도메인, 언어에 따라 크게 달라질 수 있습니다.
- LLM-as-a-Judge: 이 새로운 접근법은 인간의 평가와 더 높은 일치도를 보이는 것으로 나타났지만, 매우 계산 집약적입니다.
인간 평가를 자동 메트릭과 더 잘 일치시키기 위한 전략:
- 다중 메트릭 조합: 다양한 메트릭을 조합하여 인간의 평가와 더 잘 상관되는 메타 점수를 만듭니다.
- 보정된 메트릭: 인간 판단 데이터로 메트릭을 보정하여 상관관계를 개선합니다.
- 작업별 가중치: 작업 유형에 따라 다른 메트릭에 다른 가중치를 부여합니다.
- 인간의 피드백 통합: 인간의 피드백을 평가 루프에 통합하여 시간이 지남에 따라 메트릭을 개선합니다.
향후 연구 방향 및 발전 가능성
LLM 평가 분야는 빠르게 발전하고 있으며, 몇 가지 유망한 연구 방향이 있습니다:
- 학습된 평가 메트릭: BLEURT와 같은 학습된 메트릭은 인간 판단에 맞게 훈련되어 더 나은 상관관계를 보입니다. 이 접근법의 확장 및 개선이 예상됩니다.
- 자기 평가: LLM이 자신의 출력을 평가하고 개선하는 자기 평가 메커니즘.
- 멀티모달 평가: 텍스트뿐만 아니라 이미지, 오디오, 비디오와 같은 다양한 모달리티를 평가하는 방법.
- 도구 사용 평가: LLM이 외부 도구를 효과적으로 사용하는 능력을 평가하는 메트릭.
- 장기 대화 평가: 여러 턴에 걸친 대화에서 LLM의 일관성, 코히어런스, 유용성을 평가하는 메트릭.
- 평가를 위한 합성 데이터: 훈련 및 평가 목적으로 합성 데이터를 사용하여 다양한 시나리오 포괄.
- 실시간 적응형 평가: 사용자 상호작용 중 실시간으로 조정되는 메트릭과 평가 방법.
- 윤리적 행동 평가: LLM의 안전성, 윤리적 일관성, 편향을 평가하는 구조화된 방법.
실무자를 위한 권장사항
LLM 시스템을 평가하는 실무자를 위한 실용적인 권장 사항:
- 다중 메트릭 사용: 단일 메트릭에 의존하지 마십시오. 다양한 측면을 측정하는 메트릭 스위트를 사용하세요.
- 도메인별 평가: 특정 사용 사례와 도메인에 맞게 평가를 조정하고, 대표적인 쿼리 세트를 포함하세요.
- 정기적인 벤치마킹: 다양한 퍼스펙티브를 제공하기 위해 업계 표준 벤치마크와 자체 맞춤형 테스트를 모두 사용하세요.
- 자동 + 인간 평가: 자동 메트릭으로 먼저 평가한 다음, 인간 평가자를 사용하여 중요한 하위 집합이나 경계 사례를 평가하세요.
- 지속적인 평가: 모델 개발 주기 전반에 걸쳐 평가를 빌드하고, 회귀 테스트를 수행하며, 평가 데이터셋을 지속적으로 업데이트하세요.
- 적응형 평가: 사용자 피드백과 모델 성능을 기반으로 평가 기준을 발전시키세요.
- 투명한 보고: 강점과 약점을 포함한 모델 성능에 대한 종합적인 보고서를 생성하세요.
- 문서화된 평가 프로세스: 반복 가능하고 일관된 평가를 위해 평가 과정과 메트릭을 문서화하세요.
LLM 평가 체크리스트
다음 체크리스트는 LLM 평가를 계획하고 실행할 때 고려해야 할 주요 항목을 제공합니다:
평가 준비
- 명확한 평가 목표와 평가할 모델의 능력 정의
- 대표적인 사용 사례와 시나리오 식별
- 평가 데이터셋 준비 (그라운드 트루스 포함)
- 도메인 전문가 및 이해관계자 참여
메트릭 선택
- 작업 유형에 적합한 자동 메트릭 선택
- 정량적 및 정성적 메트릭의 균형 확보
- 필요한 계산 리소스 고려
- 인간 평가 요소 계획 (필요한 경우)
평가 실행
- 베이스라인 성능 측정
- 다양한 입력 유형 및 난이도 수준에서 모델 테스트
- 극단적인 사례 및 예외 상황 포함
- 일관성 및 신뢰성 검증
결과 분석
- 모델의 강점과 약점 식별
- 사용 사례별 성능 세분화
- 기대치와 결과 비교
- 성능 패턴 및 추세 식별
보고 및 후속 조치
- 포괄적인 평가 보고서 작성
- 성능 개선을 위한 권장 사항 개발
- 평가 프로세스 개선을 위한 피드백 수집
- 향후 평가를 위한 계획 및 일정 수립
이 체크리스트는 LLM 평가 과정을 체계화하고 중요한 단계를 놓치지 않도록 도와줍니다. 특정 상황에 맞게 조정하여 사용하세요.
결론
LLM 평가는 복잡하고 다면적인 과제입니다. 단일 메트릭이나 평가 방법으로 이러한 복잡한 시스템의 모든 측면을 포착할 수는 없습니다. 그러나 이 글에서 소개한 체계적인 접근법과 다양한 메트릭을 결합함으로써, LLM의 성능을 더 포괄적으로 이해하고 측정할 수 있습니다.
주요 핵심 사항:
- 평가 목표 정의: 평가하려는 것이 무엇인지 명확히 하고, 그에 맞는 메트릭을 선택하세요.
- 다양한 메트릭 활용: 단일 메트릭에 의존하기보다는 다양한 메트릭을 결합하여 LLM 성능의 여러 측면을 평가하세요.
- 그라운드 트루스 중요성: 고품질의 그라운드 트루스 데이터셋은 효과적인 평가의 기반입니다.
- 자동화와 인간 평가의 균형: 자동화된 메트릭과 인간 평가의 균형을 맞추어 종합적인 성능 그림을 그립니다.
- 평가의 지속적 발전: 모델과 사용 사례가 발전함에 따라 평가 방법론도 발전시키세요.
결국, LLM 평가의 목표는 모델의 진정한 능력을 이해하고, 강점과 약점을 식별하며, 개선 영역을 강조하는 것입니다. 세심하게 설계된 평가 전략은 더 강력하고 신뢰할 수 있으며 사용자 중심적인 AI 시스템으로 이어질 것입니다.
참고자료:
답글 남기기