로컬LLM
Ollama MLX 엔진 업데이트, Apple Silicon 로컬 모델 품질과 속도를 동시에 끌어올린 방법
Ollama MLX 엔진 업데이트로 Apple Silicon에서 품질 손실 절반 감소, 출력 속도 20% 향상, 에이전트 워크플로우 개선. NVFP4 양자화 지원과 스냅샷 시스템의 의미를 정리합니다.
Written by

Gemma 4 추론 속도 3배 높인 MTP 드래프터, 작동 원리는
Google이 Gemma 4에 MTP 드래프터를 추가해 품질 손실 없이 최대 3배 추론 속도를 달성했습니다. Speculative Decoding의 작동 원리와 개발자에게 갖는 의미를 설명합니다.
Written by

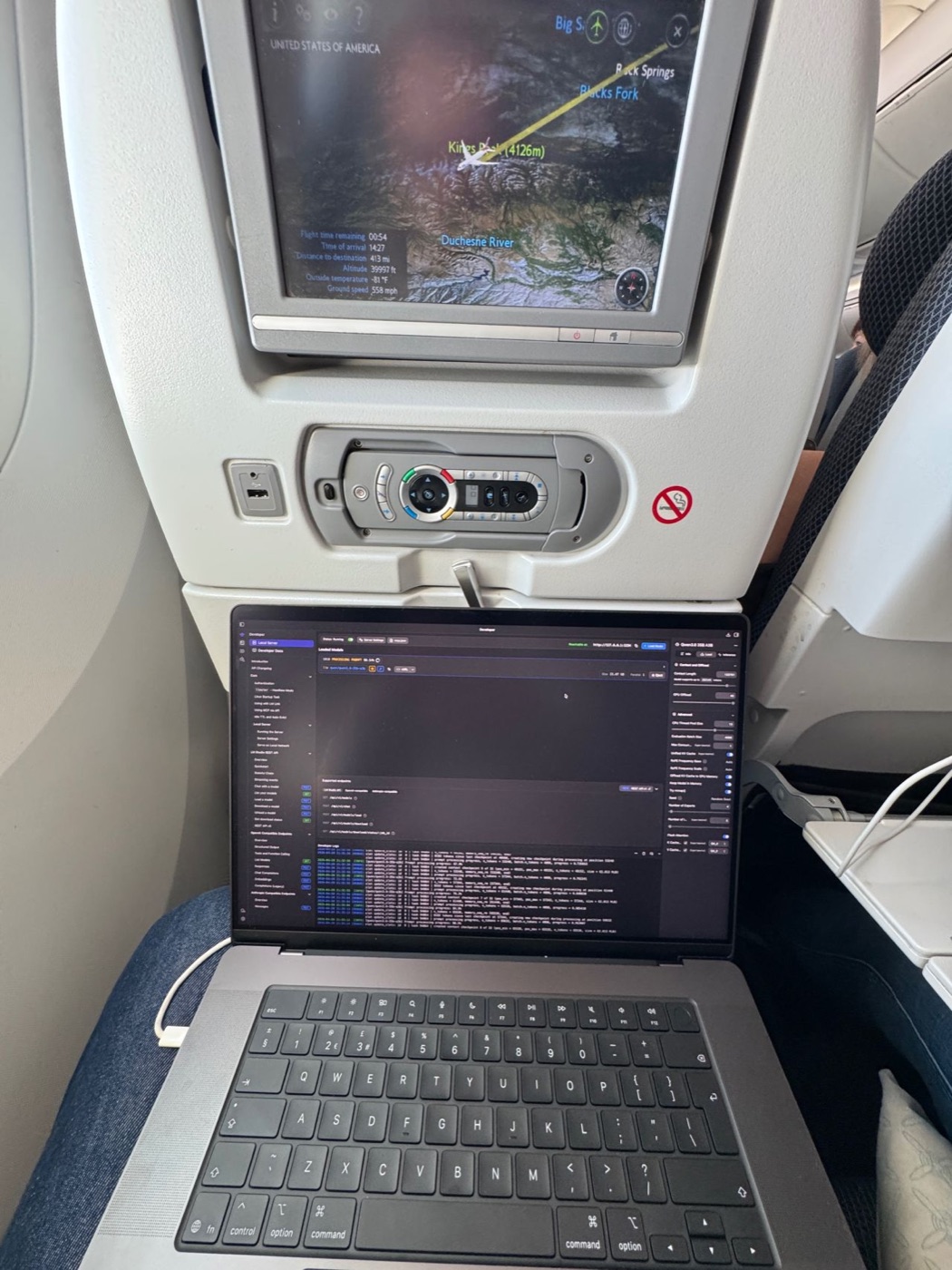
와이파이 없는 10시간, MacBook 하나로 AI 개발을 끝냈다
기내 와이파이 없이 10시간 비행하며 로컬 LLM만으로 실제 개발 작업을 수행한 엔지니어의 실전 후기. 전력·발열·컨텍스트 한계와 케이블 하나로 34W가 사라진 흥미로운 에피소드를 담았습니다.
Written by
21GB로 코딩 에이전트 상위권, Qwen3.6-35B-A3B 오픈소스 공개
알리바바 Qwen 팀이 공개한 Qwen3.6-35B-A3B, MoE 구조로 21GB로 압축해 노트북에서 실행 가능하면서 코딩 에이전트 상위권 성능을 냅니다.
Written by

Gemma 4, 로컬 에이전틱 코딩의 문턱을 넘다, 실험 결과로 확인
Gemma 4가 에이전틱 tool calling 벤치마크 6.6%→86.4%를 달성하며 로컬 에이전틱 코딩이 실용 단계에 진입했습니다. M4 맥북 실험 결과를 소개합니다.
Written by

Ollama 0.19, MLX 탑재로 Mac에서 AI 추론 속도 2배 빨라졌다
Ollama 0.19가 Apple MLX 프레임워크를 탑재해 Mac에서 AI 추론 속도를 최대 2배 향상. NVFP4 지원과 캐시 개선도 포함한 주요 업데이트를 소개합니다.
Written by
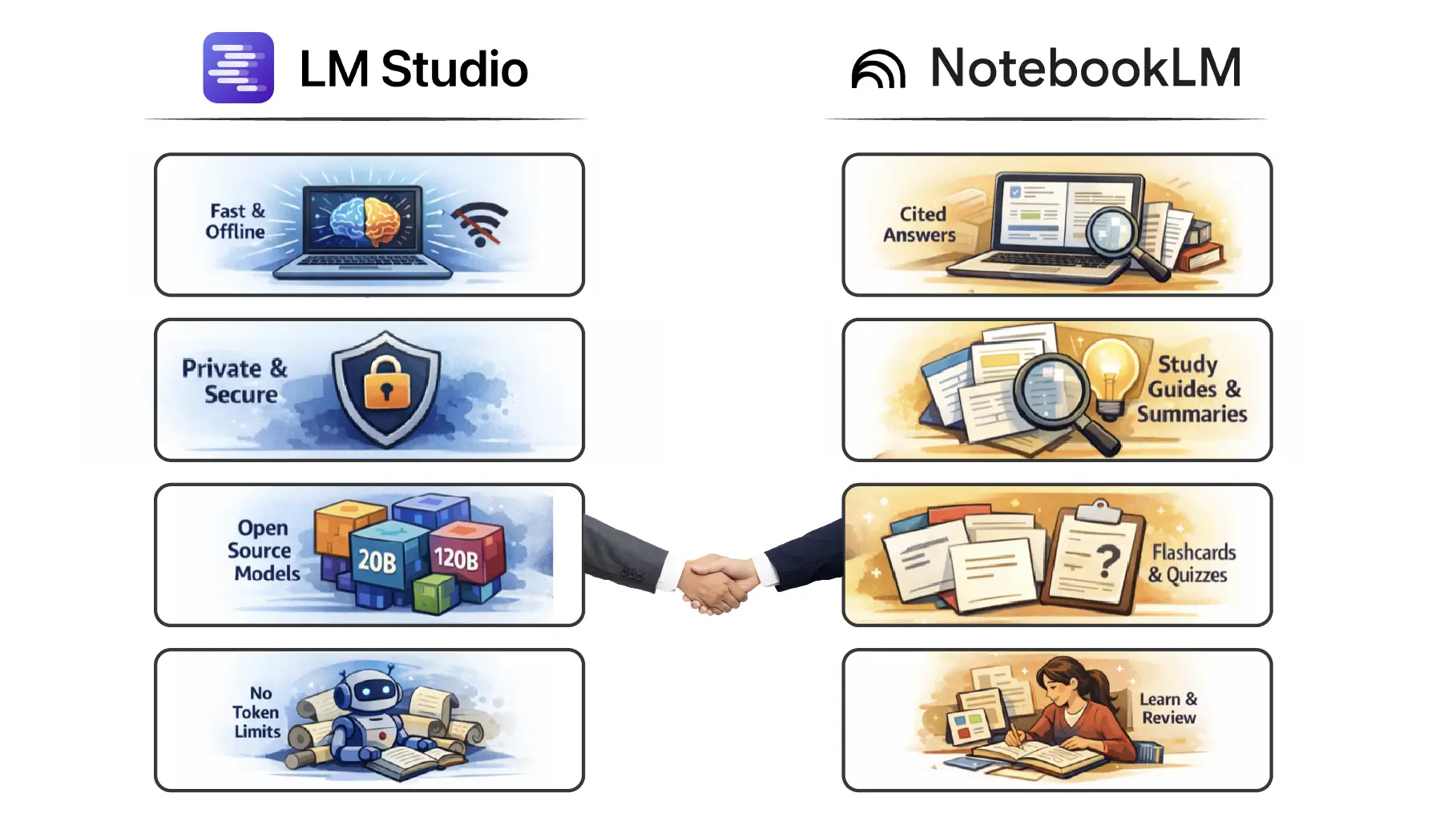
LM Studio → NotebookLM, 무료 AI 도구로 만드는 개인 맞춤 학습 시스템
NotebookLM과 LM Studio를 조합하면 비용 0원으로 AI 튜터와 학습 시스템을 만들 수 있습니다. 완전 무료 AI 학습 파이프라인을 소개합니다.
Written by
Ollama Launch 출시, AI 코딩 도구와 로컬 모델 연결을 한 줄로
Ollama의 새로운 launch 명령어로 Claude Code, Codex 같은 AI 코딩 도구가 로컬/클라우드 모델을 한 줄로 연결하는 방법을 소개합니다.
Written by

구글 EmbeddingGemma로 완전 로컬 AI 문서 검색 시스템 만들기
Google의 새로운 EmbeddingGemma 모델로 인터넷 연결 없이 완전 로컬에서 동작하는 AI 문서 검색 시스템을 구축하는 실용적인 가이드입니다. 프라이버시를 중시하는 개발자와 기업을 위한 단계별 튜토리얼을 제공합니다.
Written by

Ollama GUI 앱 출시: 로컬 AI 모델의 대중화 시대
CLI 전용이었던 Ollama가 GUI 앱을 출시하며 로컬 AI 모델을 누구나 쉽게 사용할 수 있게 되었습니다. 새 앱의 주요 기능과 로컬 AI의 장점, 실제 활용 방법을 소개합니다.
Written by
