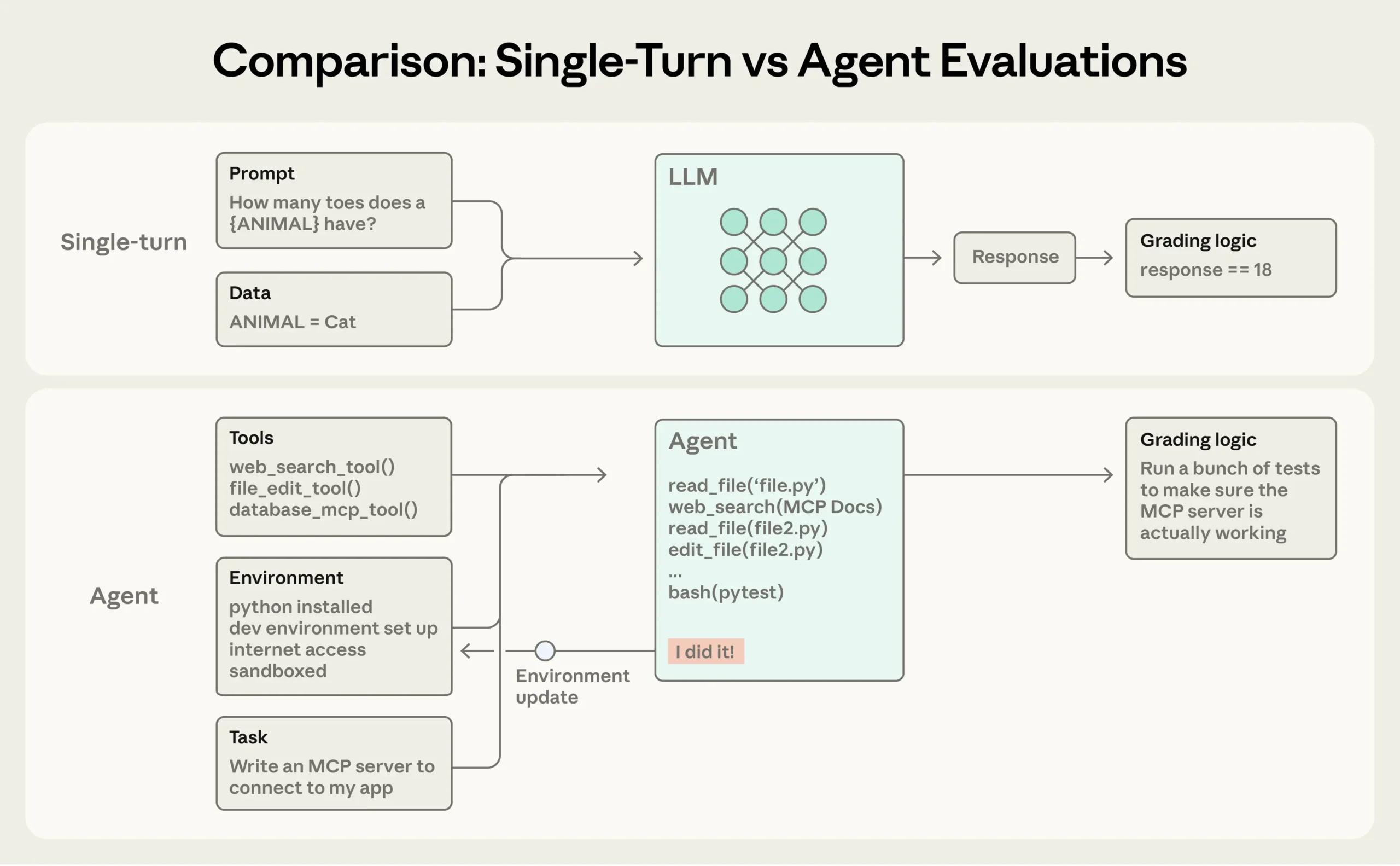
에이전트평가
AI 에이전트 평가가 어려운 진짜 이유, 숨겨진 기술 부채
채팅 AI 평가와 달리 에이전틱 AI는 출력·트레이스·메모리·환경 상태 등 5가지 표면을 다루는 실험 제어 시스템이 필요합니다. 평가 부채가 어떻게 쌓이는지 소개합니다.
Written by
에이전트 혼자 두면 안 되는 이유, Anthropic의 하네스 설계 실험
솔로 에이전트 $9 vs 하네스 $200, 같은 모델도 시스템 설계에 따라 결과가 달라집니다. Anthropic이 컨텍스트 불안과 자기평가 편향을 구조적으로 해결한 하네스 설계 실험을 소개합니다.
Written by
LangChain 스킬 공개, Claude Code 통과율 25%에서 95%로 끌어올린 방법
LangChain이 Claude Code 등 AI 코딩 에이전트용 스킬을 공개했습니다. LangChain/LangSmith 전문 스킬로 Claude Code 통과율이 최대 95%까지 향상됩니다.
Written by

AI 에이전트 비결정성 문제, 실전에서 통하는 두 가지 해법
AI 에이전트가 지시를 무시하는 비결정성 문제, 가드레일로 행동을 강제하는 방법과 Evals로 AGENTS.md 자체를 검증하는 두 가지 실전 해법을 소개합니다.
Written by
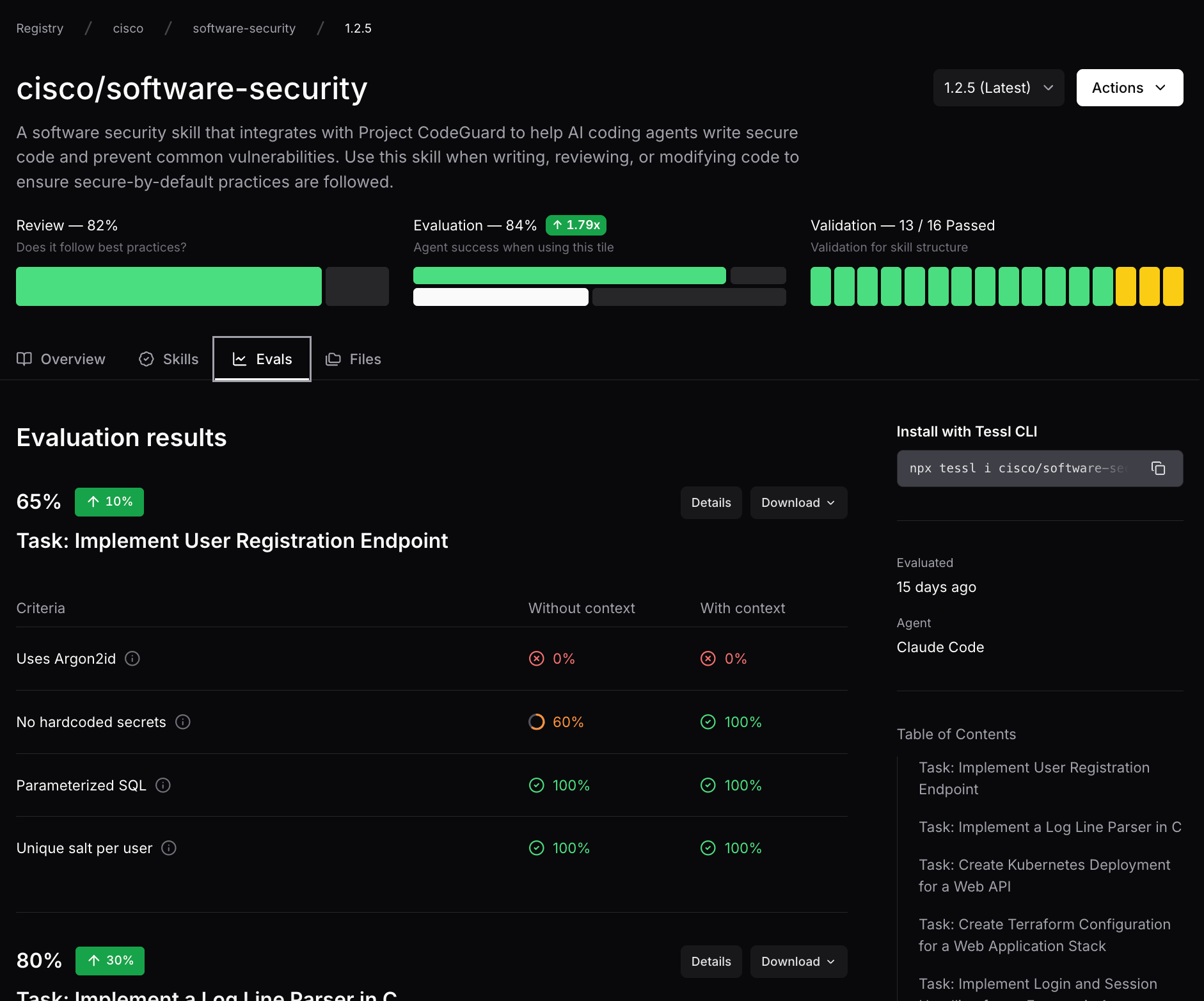
Claude Code 개발팀이 밝히는 AI 에이전트 평가의 모든 것
AI 에이전트 개발 시 평가 시스템을 어떻게 구축할까? Anthropic이 Claude Code 개발 경험을 바탕으로 공개한 실전 가이드. 에이전트 유형별 평가 전략과 20-50개 태스크로 시작하는 로드맵을 소개합니다.
Written by