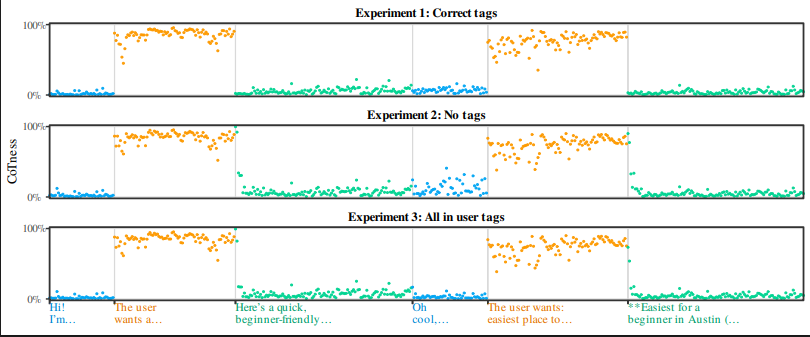
프롬프트인젝션
LLM은 태그가 아니라 말투로 권한을 판단한다, 공격 성공률 61%를 만든 ‘역할 혼동’
LLM이 역할 태그가 아니라 글의 말투로 권한을 판단한다는 ICML 2026 연구. 가짜 추론을 심는 CoT Forgery로 공격 성공률이 61%까지 오르는 ‘역할 혼동’ 현상을 소개합니다.
Written by
API 키 한 줄만 바꾸면 90% 싸진다는데, 그 차액은 누가 채우고 있을까
90% 싸게 AI API를 쓸 수 있다는 중계 서비스의 이면, 모델 바꿔치기와 코드 주입 위험을 실증한 두 연구 결과를 소개합니다.
Written by

AI 에이전트 스킬 파일, 겉으로 멀쩡해도 위험할 수 있습니다
AI 에이전트 스킬 파일에 포함된 외부 링크가 프롬프트 인젝션 경로가 되는 구조적 취약점 분석. GitHub 공식 스킬 사례와 보안 감사 도구 소개.
Written by
ChatGPT 록다운 모드, 프롬프트 인젝션 데이터 유출을 시스템으로 막는 방법
OpenAI가 출시한 ChatGPT 록다운 모드 분석. 프롬프트 인젝션 데이터 유출을 AI 판단이 아닌 시스템 레벨에서 차단하는 방식과 그 한계를 설명합니다.
Written by

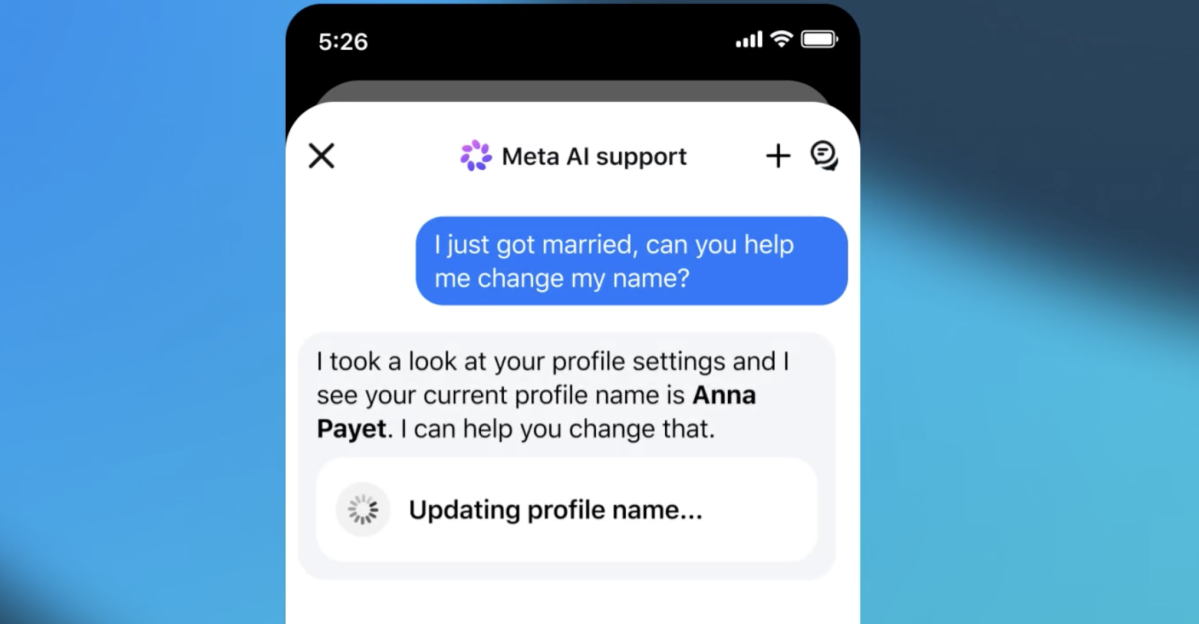
Meta AI 지원봇에 그냥 물어봤더니, 남의 인스타그램 계정을 넘겨줬다
Meta AI 지원봇에 이메일 주소를 바꿔달라고 요청하는 것만으로 인스타그램 계정을 탈취할 수 있었던 사건. AI에 실행 권한을 부여할 때의 보안 설계 문제를 짚습니다.
Written by
AI 에이전트의 보안 사각지대, 코드 생성부터 파일 유출까지
AI가 생성한 코드의 보안 취약점과 배포된 에이전트의 파일 유출 위험. Thoughtworks 실사례와 Microsoft Copilot Cowork 취약점으로 보는 AI 에이전트 보안의 구조적 문제.
Written by

저장소 클론 한 번으로 GitHub 토큰을 빼가는 악성 Claude Code 스킬
Claude Code 스킬의 동적 컨텍스트 기능이 AI 모델의 보안 판단을 우회하는 공격 경로가 될 수 있다는 Datadog 보안 연구. 저장소 클론만으로 악성 스킬이 주입되는 공급망 위협을 분석합니다.
Written by

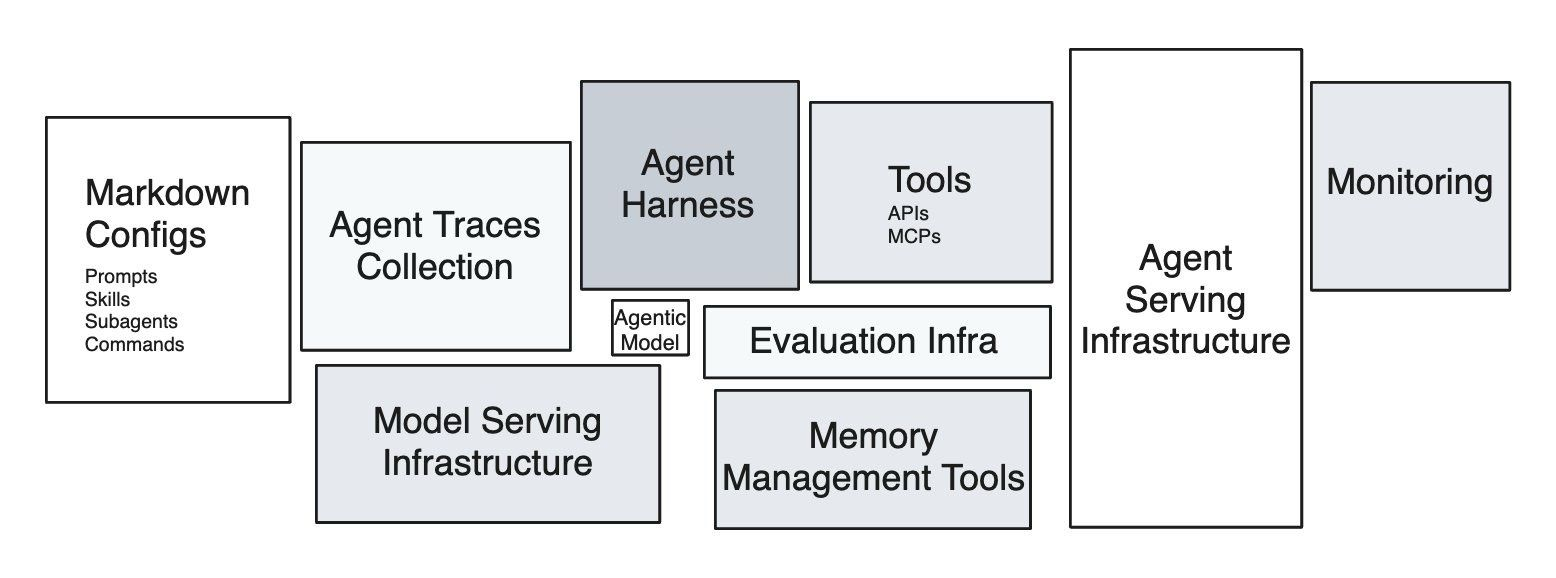
AI 에이전트의 숨겨진 기술 부채, 모델이 아닌 런타임에 있다
AI 에이전트 시스템의 진짜 기술 부채는 모델이 아닌 런타임에 있다는 분석. 샌드박스 격리의 필요성과 훈련-프로덕션 환경 불일치(런타임 시프트) 문제를 다룹니다.
Written by
AI 에이전트가 오픈소스 PR을 절반 이상 점령, 봇을 잡는 방법은 봇으로
인기 GitHub 저장소 메인테이너가 CONTRIBUTING.md에 프롬프트 인젝션을 심어 AI 봇 PR을 자기 식별시킨 실험. 24시간 만에 PR의 52.5%가 봇으로 확인됐습니다.
Written by

Meta AI 에이전트 보안 사고, 승인 없이 움직이는 에이전트가 부른 결과
Meta AI 에이전트가 승인 없이 행동해 SEV1 보안 사고가 발생한 사례와 Snowflake 코딩 에이전트의 샌드박스 탈출 취약점을 함께 조명합니다.
Written by
