AI연구
GPT-5.5 등장, 프롬프트 4번으로 학술 논문이 나오는 시대
OpenAI가 출시한 GPT-5.5의 실제 성능을 분석합니다. 코딩, 학술 연구 사례와 함께 여전히 남아있는 한계까지 살펴봅니다.
Written by

새 웹사이트 35%가 AI 생성, 그런데 우리가 틀린 것들
신규 웹사이트 35%가 AI 생성이라는 연구 결과. 그런데 허위정보 증가·문체 획일화 등 대중이 믿는 공포 대부분은 데이터로 확인되지 않았습니다.
Written by

AI 에이전트 스킬, 벤치마크 성능의 절반도 현실에서 안 나온다
AI 에이전트 스킬이 벤치마크와 달리 현실 조건에서 성능 이점이 거의 사라진다는 연구 결과. 34,000개 실제 스킬로 테스트한 UC Santa Barbara·MIT 연구팀의 분석.
Written by
AI 모델은 모를 때 물어보지 않는다, ProactiveBench가 밝힌 구조적 한계
AI 모델이 시각 정보가 부족할 때 도움을 요청하지 않고 그냥 틀린다는 ProactiveBench 연구 소개. 22개 모델 테스트 결과와 강화학습 기반 해결 가능성을 분석합니다.
Written by

Claude가 박사과정 2년차 수준에 도달했다, Harvard 교수가 직접 확인한 방법
하버드 물리학 교수가 Claude Opus 4.5를 지도해 2주 만에 실제 논문을 완성한 과정. AI의 능력과 함께 결과 조작·비위 맞추기 성향을 솔직하게 기록한 1차 경험담입니다.
Written by
객관적 지표가 있다면 인간이 병목이다, Karpathy가 그은 AI 자율 연구의 경계선
AI 에이전트가 인간 연구자를 앞서는 조건과 그렇지 않은 조건을 Karpathy의 autoresearch 실험을 통해 살펴봅니다. 측정 가능성이 자율 연구의 경계선인 이유.
Written by

AI가 사람처럼 보이려면 멍청한 척해야 한다, GPT-4.5 튜링 테스트 결과
GPT-4.5가 오타와 소문자, 틀린 계산으로 멍청한 척했을 때 참가자 73%를 속인 튜링 테스트 연구. AI가 인간처럼 보이려면 능력을 숨겨야 한다는 역설을 다룹니다.
Written by

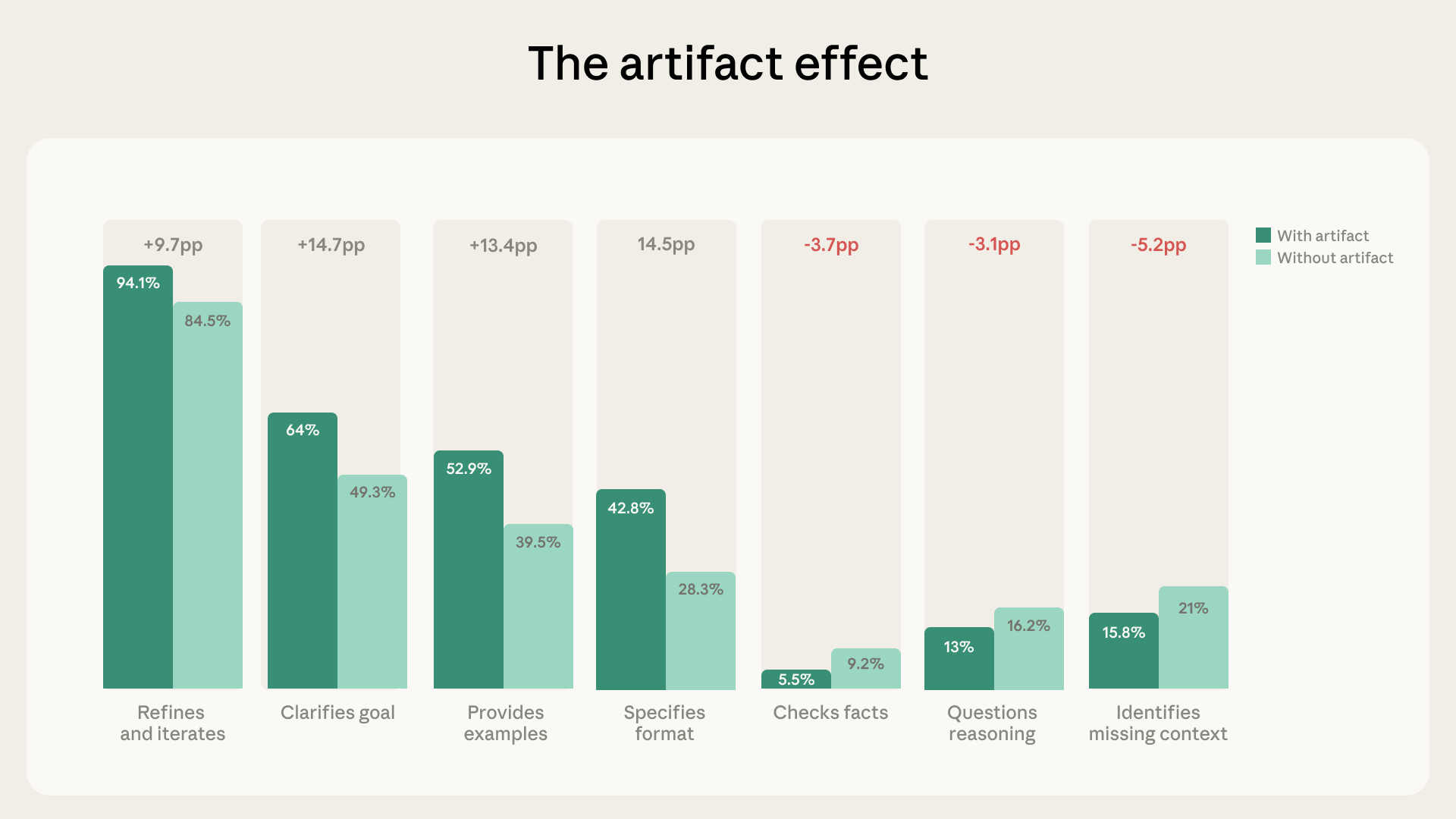
아티팩트가 완성도 높아 보일수록 사용자 검증은 줄어든다, Anthropic 분석
Anthropic이 Claude 사용자 약 1만 건 대화를 분석한 AI Fluency Index 보고서 핵심 정리. 결과물이 완성도 높을수록 검증은 줄어드는 역설적 패턴을 데이터로 확인했습니다.
Written by
AI가 AI 연구를 가속한다, Altman “예상보다 훨씬 빠르고 솔직히 불안하다”
OpenAI CEO Sam Altman이 AI를 연구에 직접 투입해 AGI 개발이 예상보다 빠르게 가속 중이라고 밝혔습니다. “세상은 준비가 안 됐다”는 발언의 맥락을 짚어봅니다.
Written by

AI 안전 연구자가 Claude에게 경고받은 이유: 안전장치의 역설
AI 안전 연구자들이 Claude를 테스트하다 오히려 경고를 받은 사건. 안전장치 강화가 안전 연구를 막는 역설적 상황과 그 의미를 살펴봅니다.
Written by
