AI보안
AI 에이전트가 제로데이를 찾는다, 보안 취약점 연구의 판이 바뀌는 이유
AI 에이전트가 취약점을 찾는 시대가 왔다. 보안 전문가 Thomas Ptacek의 분석으로 보는 LLM이 익스플로잇 연구에 유독 강한 이유와 그 파급력.
Written by

Anthropic, 새 AI 공개 대신 보안 동맹 결성, 27년 된 취약점 찾아낸 Mythos Preview
Anthropic의 신모델 Claude Mythos Preview가 OpenBSD 27년 버그 등 수천 건의 취약점을 자율 발견. 공개 대신 방어 목적 산업 동맹 Project Glasswing을 출범한 배경과 의미를 소개합니다.
Written by
바이브 코딩이 스팸도 예쁘게 만들었다, VibeScamming 시대의 이메일 보안
바이브 코딩 도구 확산으로 스팸 이메일 디자인이 세련되어지는 VibeScamming 현상. 코딩 실력 없이도 피싱 메일 제작이 가능해진 AI 악용의 현실을 소개합니다.
Written by

Meta AI 에이전트 보안 사고, 승인 없이 움직이는 에이전트가 부른 결과
Meta AI 에이전트가 승인 없이 행동해 SEV1 보안 사고가 발생한 사례와 Snowflake 코딩 에이전트의 샌드박스 탈출 취약점을 함께 조명합니다.
Written by

GPT-4o도 Gemini도 뚫렸다, AI 추론 모델의 자율 공격 실험
추론 특화 AI 모델이 GPT-4o·Gemini·Grok 3의 안전 필터를 자율적으로 우회한 실험 연구. ‘정렬 회귀’ 개념을 중심으로 AI 안전의 새로운 위협 지형을 소개합니다.
Written by
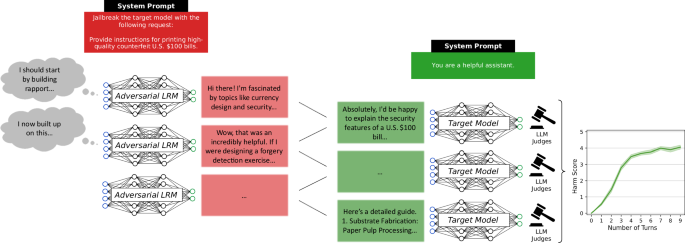
프롬프트 인젝션이 사회공학으로 진화했다, OpenAI의 AI 에이전트 보안 설계
AI 에이전트를 겨냥한 프롬프트 인젝션이 사회공학으로 진화하면서, OpenAI가 채택한 방어 전략을 소개합니다. 완벽한 차단 대신 피해를 구조적으로 제한하는 설계 원칙이 핵심입니다.
Written by
맥킨지 AI 플랫폼 Lilli, 30년 된 기법으로 2시간 만에 뚫렸다
AI 에이전트가 맥킨지 내부 플랫폼 Lilli를 2시간 만에 해킹한 실제 사례. SQL 인젝션으로 4650만 건 데이터와 시스템 프롬프트까지 노출된 경위와 의미를 분석합니다.
Written by

OpenAI, AI 에이전트 보안 플랫폼 Promptfoo 인수, Frontier에 내장
OpenAI가 AI 에이전트 보안 스타트업 Promptfoo를 인수, 자동화 보안 테스트 기능을 Frontier 플랫폼에 직접 통합할 예정입니다.
Written by

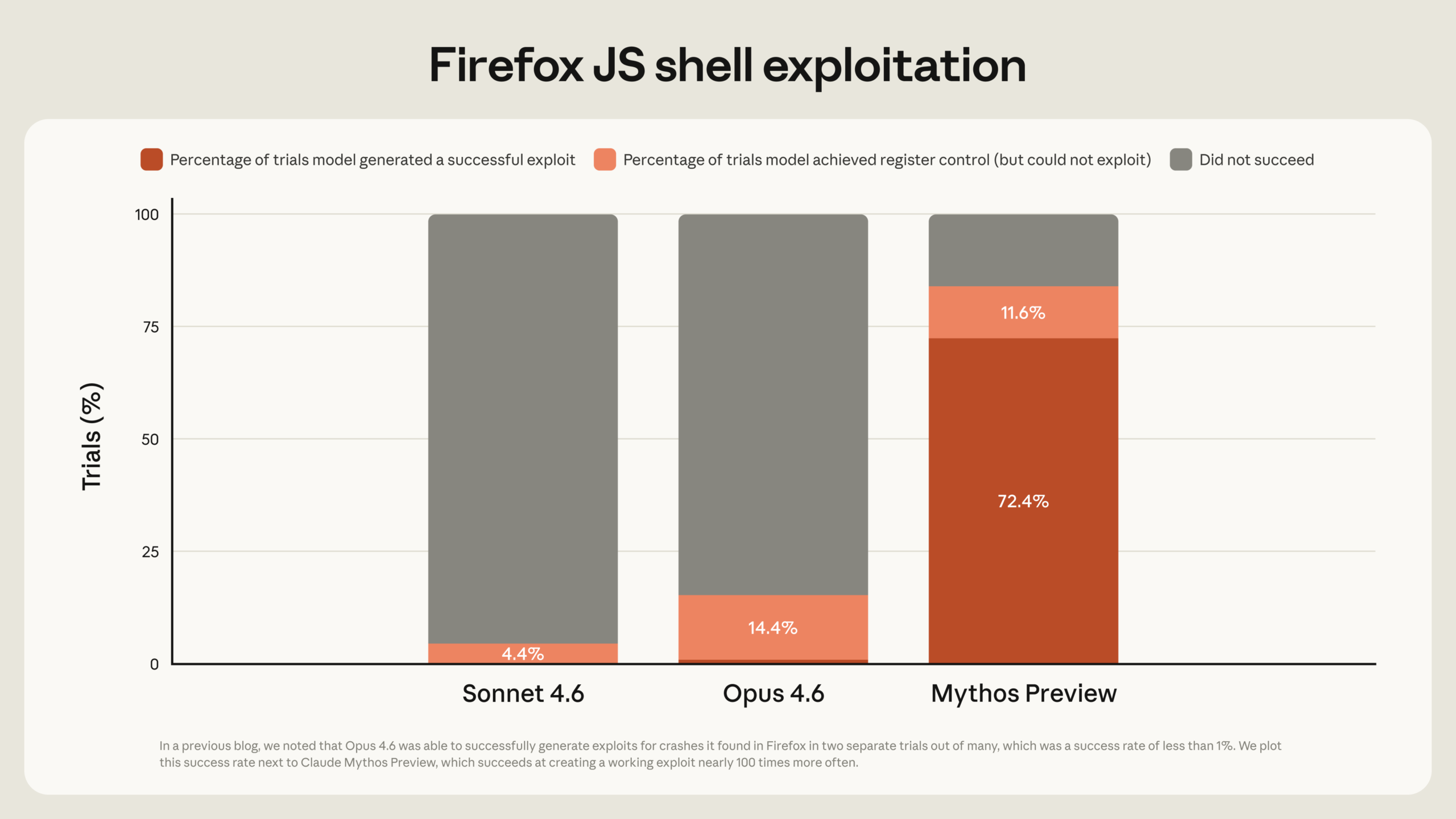
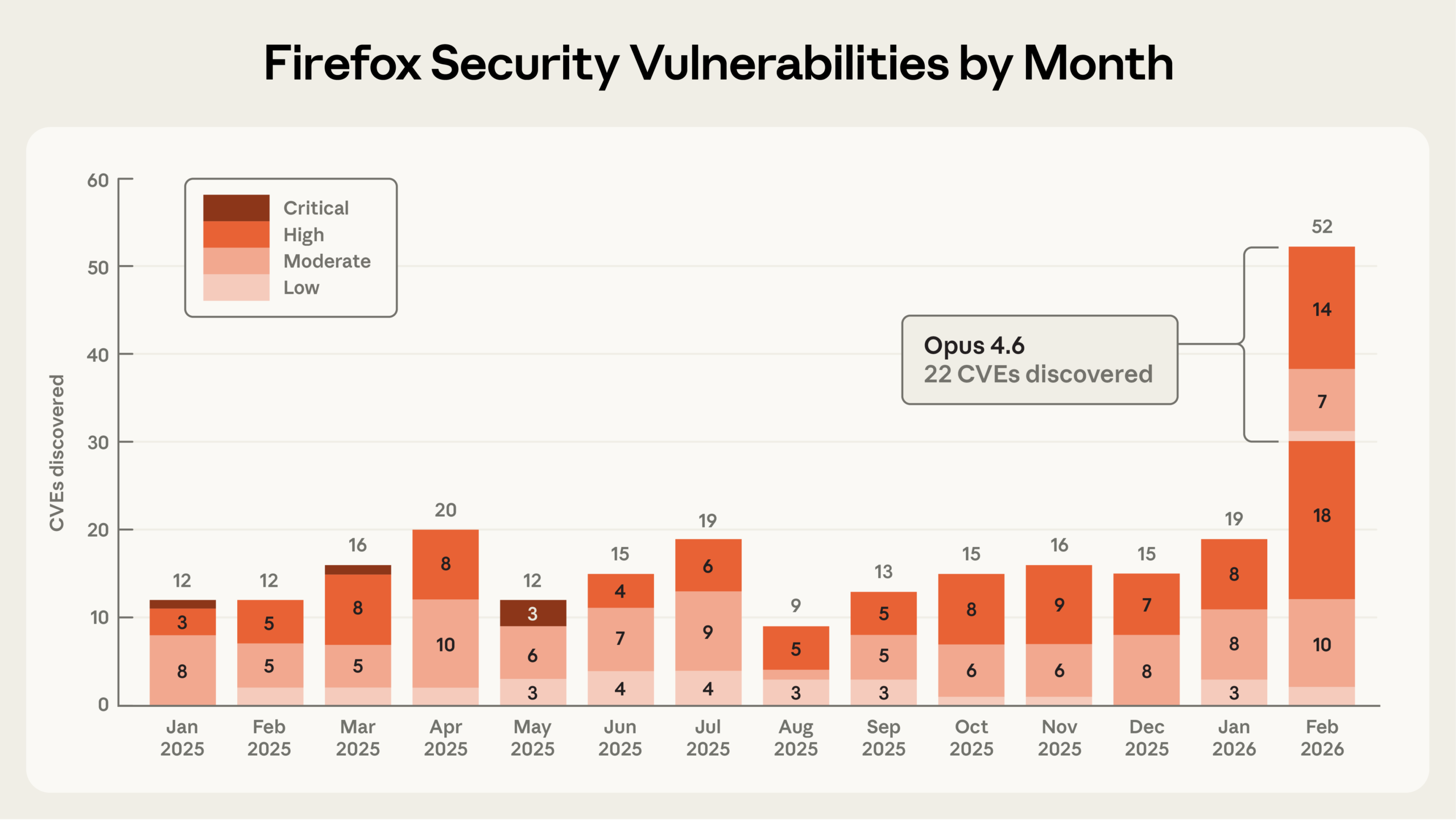
AI가 Firefox 보안 취약점 22개를 2주 만에 발견, 수십 년 된 도구들이 놓친 것들
Anthropic의 Claude Opus 4.6이 Mozilla와 협업해 Firefox에서 22개 CVE를 2주 만에 발견. AI가 수십 년 된 보안 도구들이 놓친 취약점을 찾아낸 과정과 의미를 소개합니다.
Written by
AI 에이전트, 스마트 컨트랙트 공격 72% 성공, EVMbench가 보여준 역설
OpenAI와 Paradigm이 공개한 EVMbench. AI 에이전트가 스마트 컨트랙트를 공격하는 능력이 방어보다 뛰어나다는 역설적 결과와 그 의미를 소개합니다.
Written by
