AI한계
모두가 같은 AI 쓰면 생기는 일, AI 수렴 현상 실증 데이터
AI를 쓸수록 콘텐츠가 비슷해지는 AI 수렴 현상. 영국 의회 속기록, Basic B*** Effect 연구 등 실증 데이터로 살펴봅니다.
Written by

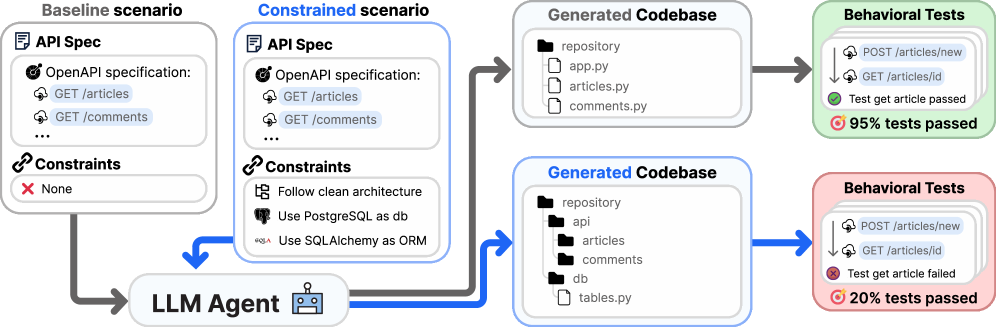
코딩 에이전트, 논문으로 확인된 구조적 한계
코딩 에이전트는 구조적 제약이 쌓일수록 성능이 급격히 떨어집니다. George Hotz의 6개월 실험과 Constraint Decay 논문이 말하는 에이전트의 실제 한계.
Written by
AI 모델, 복잡한 차트 앞에서 성능 절반 이상 추락, RealChart2Code 벤치마크 결과
RealChart2Code 벤치마크 연구 결과, 최상위 AI 모델도 복잡한 차트 앞에서 성능이 절반 이하로 떨어지는 ‘복잡도 갭’이 확인됐습니다.
Written by

AI 코딩 에이전트의 진짜 문제, 기계적 공감 능력이 없다
AI 코딩 에이전트가 겉으로는 작동하지만 시스템의 결을 거스르는 이유를 “기계적 공감” 개념으로 설명합니다. 개발자라면 공감할 구체적인 사례와 함께.
Written by

테런스 타오가 본 AI 수학의 함정, 아이디어는 넘치고 검증은 더 어렵다
필즈상 수학자 테런스 타오가 AI의 아이디어 생성 비용 0화와 검증 병목 문제를 자동차-도시 비유로 설명한 통찰. AI와 수학의 공존 인프라를 모색합니다.
Written by

AI는 전문가 시험은 통과하는데, 유치원생 문제는 왜 못 풀까
전문가 시험은 통과하지만 유아 문제는 못 푸는 AI. verbalization bottleneck이 만드는 기본기 실패를 분석합니다.
Written by

Anthropic, Claude 실패율 분석 후 AI 생산성 예측 절반으로 하향
Anthropic이 Claude 사용 데이터 100만 건 분석 결과, 복잡한 작업일수록 실패율이 높다는 것을 발견하고 AI 생산성 예측을 절반으로 하향 조정했습니다.
Written by

유명 수학자 Joel Hamkins, LLM은 수학 연구에 ‘전혀 도움 안 돼’
노트르담 대학교 논리학 교수 Joel Hamkins가 LLM의 수학 연구 활용에 대해 ‘전혀 도움 안 돼’라고 직설적으로 평가. 벤치마크와 실용성 간극을 드러냅니다.
Written by
LLM 시대의 끝? 거대 AI 기업들이 월드 모델에 투자하는 이유
GPT와 Claude로 대표되는 거대 언어 모델이 텍스트 이해의 한계에 부딪히면서 AI 업계가 물리 세계를 이해하고 시뮬레이션하는 World Models로 대전환을 시작했다. Meta의 AssetGen, Google의 Gemini Robotics, Nvidia의 Omniverse 등 주요 기업들의 구체적 사례와 함께 이 기술이 로보틱스, 자율주행, VR 등 산업 전반에 미칠 영향을 살펴본다.
Written by

벡터 임베딩의 숨겨진 한계: 왜 최신 AI도 ‘사과 좋아하는 사람 찾기’에 실패할까?
Google DeepMind 연구를 바탕으로 벡터 임베딩 모델의 수학적 한계와 실무적 해결책을 쉽게 설명한 기술 인사이트
Written by
