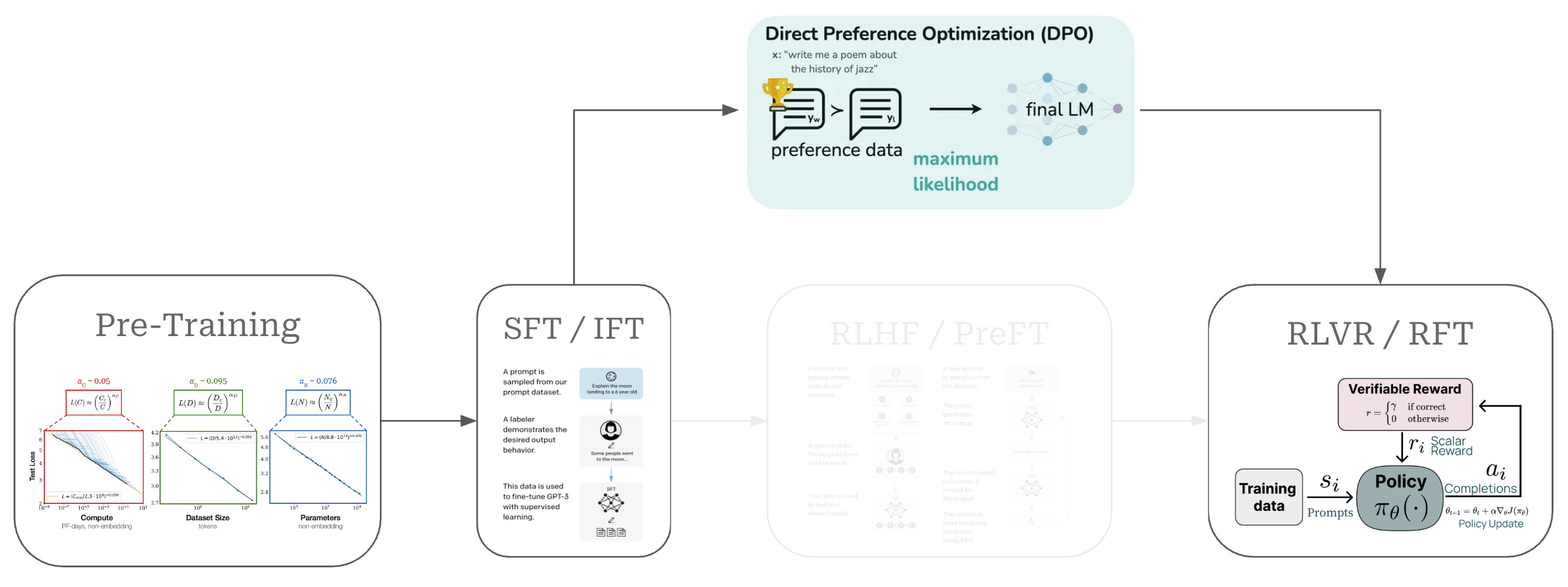
DPO
텍스트 디제너레이션, LLM 요청 3%가 시스템 전체를 42% 느리게 만드는 원리
LLM 요청의 3%에서 발생하는 텍스트 디제너레이션이 GPU 배치 전체 처리 시간을 42% 늘리는 구조적 원인과, DPO로 발생률을 최대 87% 줄인 실험 결과를 소개합니다.
Written by

DPO: RLHF를 대체하는 혁신적인 LLM 정렬 기법 – 복잡성을 제거하고 효율성을 높이다
DPO(Direct Preference Optimization)는 기존 RLHF의 복잡성을 제거하면서도 동일한 성능을 달성하는 혁신적인 LLM 정렬 기법입니다. 별도의 보상 모델과 강화 학습 없이도 인간 선호도에 맞는 고품질 언어 모델을 훈련할 수 있어, AI 개발의 접근성을 크게 향상시켰습니다.
Written by