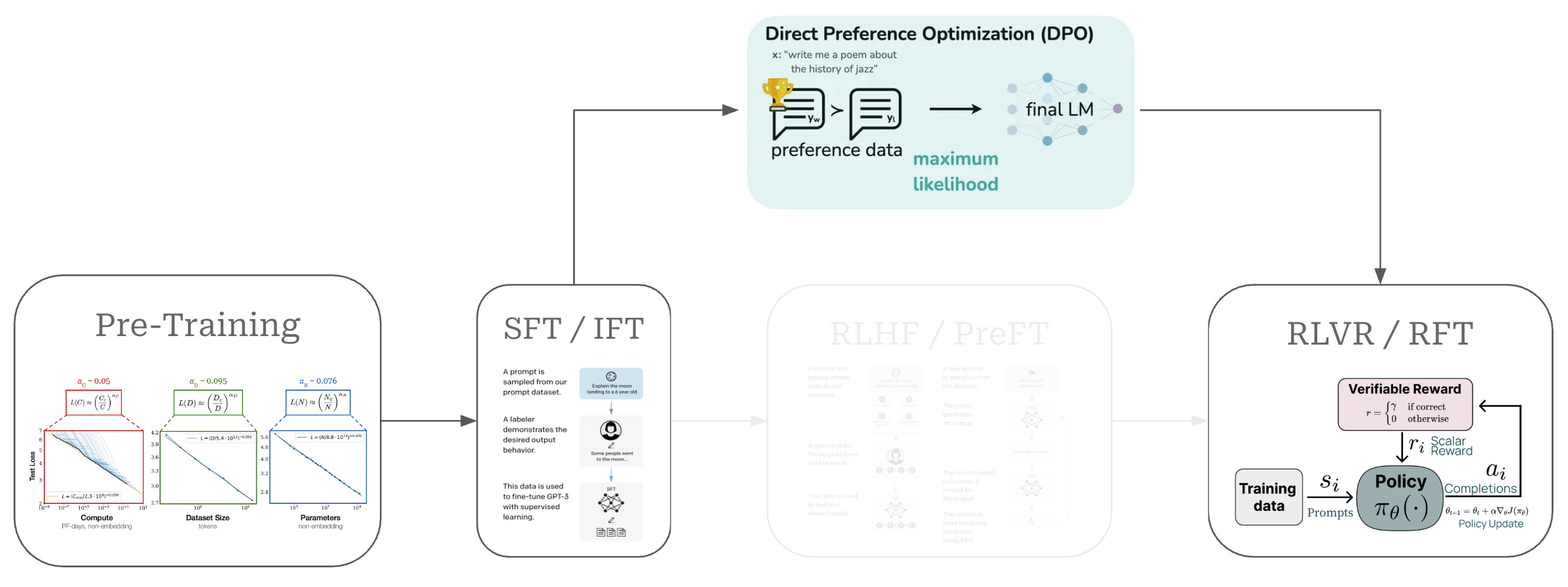
DPO(Direct Preference Optimization)는 기존 RLHF의 복잡한 보상 모델과 강화 학습 없이도 동일한 성능을 달성하는 혁신적인 LLM 정렬 방법으로, 메모리 사용량을 절반으로 줄이고 구현을 대폭 단순화했습니다.
LLM 정렬의 새로운 패러다임
대형 언어 모델(LLM)을 인간의 선호도에 맞게 정렬하는 것은 고품질 AI 시스템 구축의 핵심입니다. ChatGPT와 Claude 같은 성공적인 모델들이 RLHF(Reinforcement Learning from Human Feedback)를 통해 혁신적인 성능을 보여준 이후, LLM 정렬은 AI 연구의 중요한 영역이 되었습니다.
하지만 RLHF는 복잡성이라는 큰 벽에 부딪혔습니다. 별도의 보상 모델 훈련, PPO 같은 강화 학습 알고리즘 사용, 그리고 메모리에 4개의 서로 다른 모델 복사본을 유지해야 하는 등의 문제가 있었습니다. 이런 복잡성은 대형 연구소가 아닌 곳에서는 접근하기 어려운 높은 진입 장벽을 만들었습니다.

DPO의 핵심 아이디어: 중간 단계를 건너뛰는 지름길
DPO를 이해하는 가장 쉬운 방법은 요리에 비유하는 것입니다. 맛있는 요리를 만들기 위해 두 가지 방법이 있다고 생각해보세요:
기존 RLHF 방식: 요리 선생님을 통한 학습
- 요리 선생님 훈련하기: 먼저 맛을 평가할 수 있는 선생님을 별도로 훈련시킵니다
- 요리사 교육하기: 요리사가 음식을 만들면 선생님이 평가하고, 그 평가를 바탕으로 요리사를 다시 교육합니다
- 복잡한 과정: 선생님과 요리사, 두 명을 모두 관리해야 합니다
DPO 방식: 직접 비교 학습
- 직접 비교: 두 개의 요리를 놓고 “어느 것이 더 맛있나요?”라고 직접 묻습니다
- 바로 학습: 선호도 답변을 바탕으로 요리사가 바로 학습합니다
- 단순한 과정: 중간에 별도의 선생님이 필요 없습니다
핵심 통찰: DPO는 “언어 모델 자체가 이미 좋고 나쁨을 판단할 능력을 가지고 있다”는 발견에서 출발했습니다. 마치 요리사가 이미 맛을 알고 있는데, 굳이 별도의 맛 평가사를 두지 않아도 된다는 것과 같습니다.
실제로는 어떻게 작동할까요?
DPO는 간단한 원리로 작동합니다:
- 선호도 데이터 준비: “A 답변이 B 답변보다 좋다”는 식의 비교 데이터를 준비합니다
- 확률 조정: 좋은 답변의 확률은 높이고, 나쁜 답변의 확률은 낮춥니다
- 균형 유지: 원래 모델에서 너무 멀어지지 않도록 적절히 조절합니다
이렇게 하면 복잡한 중간 단계 없이도 RLHF와 똑같은 결과를 얻을 수 있습니다. 마치 목적지까지 가는데 굳이 경유지를 거치지 않고 직항으로 가는 것과 같습니다.
실제 구현: 간단하고 효과적
DPO의 가장 큰 장점 중 하나는 구현의 단순성입니다. HuggingFace의 TRL 라이브러리를 사용하면 몇 줄의 코드로 DPO 훈련을 시작할 수 있습니다:
from trl import DPOConfig, DPOTrainer
# 모델과 데이터 로드
model = load_pretrained_model()
tokenizer = load_tokenizer()
train_dataset = load_preference_dataset() # UltraFeedback 등
# DPO 훈련 설정
training_args = DPOConfig(
output_dir="./dpo_logs/",
learning_rate=5e-7,
beta=0.1 # KL 제약 강도 조절
)
trainer = DPOTrainer(
model=model,
args=training_args,
processing_class=tokenizer,
train_dataset=train_dataset,
)
# 훈련 실행
trainer.train()핵심 하이퍼파라미터
β (베타) 값: DPO에서 가장 중요한 하이퍼파라미터로, 모델이 참조 모델로부터 얼마나 벗어날 수 있는지를 제어합니다. 일반적으로 0.1~0.5 사이의 값을 사용하며, 높은 값일수록 선호도 정렬이 더 적극적으로 이루어집니다.

RLHF 대비 DPO의 실질적 장점
1. 메모리와 계산 비용 절감
- RLHF: 정책 모델, 참조 모델, 보상 모델, 가치 함수 등 4개 모델 필요
- DPO: 정책 모델과 참조 모델 2개만 필요 (50% 메모리 절약)
2. 구현 복잡성 제거
- RLHF: PPO 알고리즘의 복잡한 구현 세부사항들 (클리핑, 가치 함수 업데이트 등)
- DPO: 표준적인 분류 손실 함수로 간단한 gradient descent
3. 훈련 안정성 향상
- RLHF: 강화 학습 특유의 불안정성과 하이퍼파라미터 민감성
- DPO: 지도 학습과 유사한 안정적인 훈련 과정
성능 비교와 실제 활용 사례
최근 연구들에 따르면 DPO는 다양한 작업에서 RLHF와 경쟁력 있는 성능을 보여줍니다:
- HuggingFace 오픈 LLM 리더보드: 상위권 모델들이 DPO 사용
- Mistral 8×7B MoE: SFT 이후 DPO로 성능 향상
- Zephyr 모델: DPO를 통한 증류 방식으로 우수한 결과 달성
하지만 모든 상황에서 DPO가 우월한 것은 아닙니다. 연구에 따르면:
- 제한된 선호도 데이터: DPO가 과적합에 더 취약할 수 있음
- 복잡한 인간 가치 정렬: RLHF가 더 “합리적인” 인간 가치 함수를 학습
- 온라인 vs 오프라인: RLHF의 온라인 학습이 일부 상황에서 더 효과적

언제 DPO를 선택해야 할까?
DPO 추천 상황:
- 제한된 계산 자원과 메모리
- 빠른 프로토타이핑과 실험이 필요한 경우
- 감정 제어, 요약, 대화 등 상대적으로 단순한 작업
- 이진 선호도 데이터가 충분한 경우
RLHF 고려 상황:
- 복잡한 인간 가치 정렬이 중요한 작업
- 다양한 형태의 피드백 (평점, 순위, 수정사항) 활용 가능
- 충분한 계산 자원과 전문성 보유
- 최고 수준의 성능이 절대적으로 중요한 경우
미래 전망: 정렬 연구의 민주화
DPO의 등장은 LLM 정렬 연구를 민주화하는 중요한 전환점입니다. 복잡한 RLHF 구현 없이도 고품질 모델 정렬이 가능해짐에 따라, 더 많은 연구자와 개발자들이 이 영역에 참여할 수 있게 되었습니다.
현재 많은 오픈 소스 모델들이 DPO를 표준 후훈련 방법으로 채택하고 있으며, 일부 연구에서는 DPO와 RLHF를 결합한 하이브리드 접근법도 탐구하고 있습니다. 이는 각 방법의 장점을 살려 더 효과적인 모델 정렬을 달성하려는 시도입니다.
DPO는 복잡성과 성능 사이의 균형을 혁신적으로 해결한 방법론으로, AI 개발의 접근성을 크게 향상시켰습니다. 비록 모든 상황에서 RLHF를 완전히 대체하지는 못하지만, 대부분의 실용적 응용에서 충분히 효과적이면서도 훨씬 간단한 대안을 제공합니다.
참고자료:
답글 남기기