LLM 서빙
GPU 1,192개를 213개로: 알리바바가 증명한 82% 절감의 비밀
알리바바 클라우드의 Aegaeon GPU 풀링 시스템이 AI 모델 서빙에 필요한 GPU를 82% 절감한 방법. 토큰 레벨 가상화로 1,192개 GPU 작업을 213개로 처리한 실제 검증 사례와 AI 인프라 비용 절감 전략을 소개합니다.
Written by

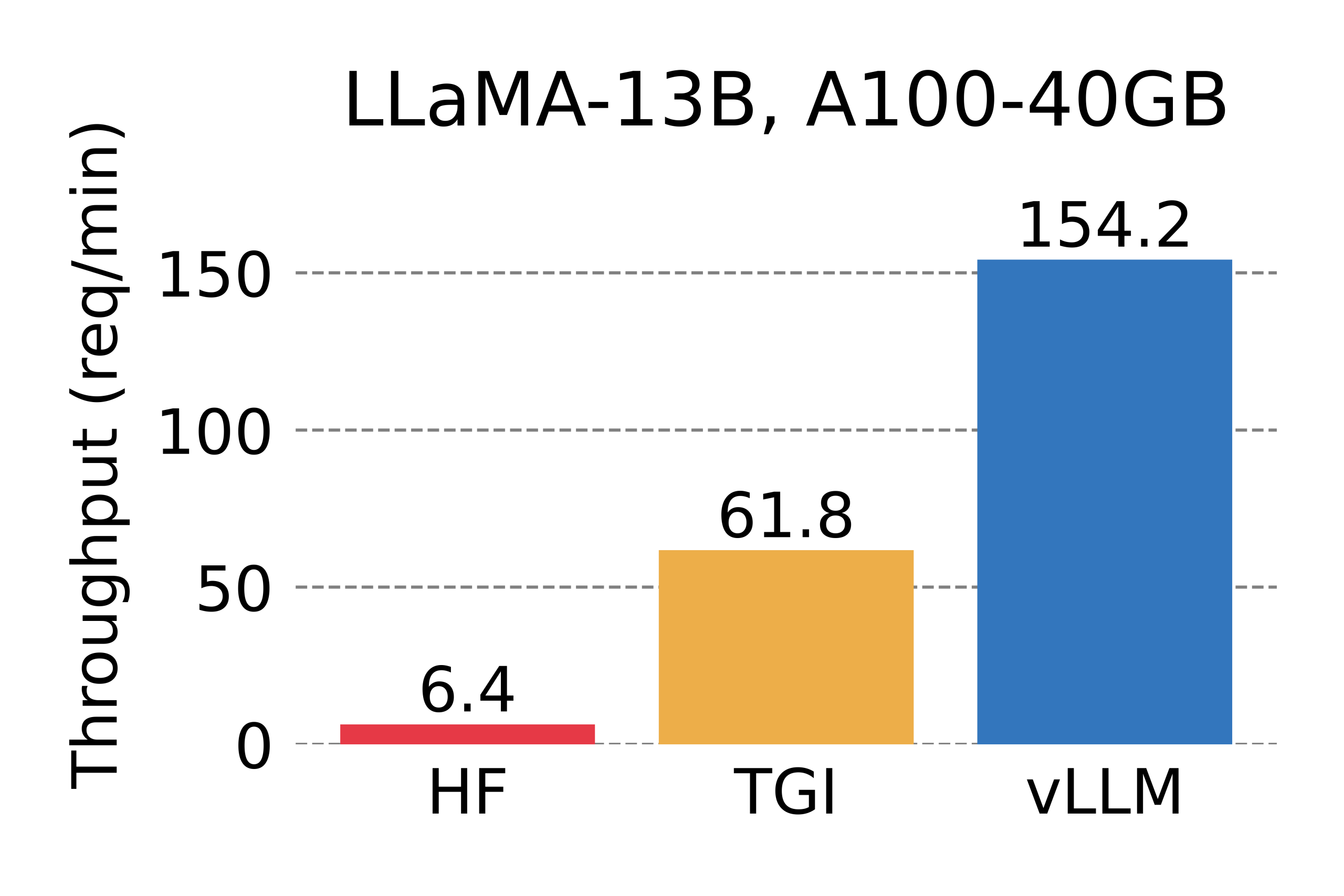
vLLM: PagedAttention으로 LLM 서빙 성능을 24배 향상시킨 혁신 기술
UC Berkeley에서 개발한 vLLM의 PagedAttention 기술이 어떻게 LLM 서빙 성능을 24배 향상시켰는지, 그리고 실제 프로덕션 환경에서의 적용 사례와 설치부터 사용까지의 실용적인 가이드를 제공합니다.
Written by