대규모 언어 모델(LLM)의 활용이 빠르게 확산되면서, 실제 서비스 환경에서 이러한 모델들을 효율적으로 운영하는 것이 중요한 과제로 떠오르고 있습니다. 아무리 뛰어난 성능의 GPU를 사용하더라도 기존 방식으로는 놀랍도록 느린 추론 속도에 직면하게 되는 경우가 많았죠. 이런 문제를 해결하기 위해 UC Berkeley에서 개발한 vLLM은 PagedAttention이라는 혁신적인 기술로 LLM 서빙의 패러다임을 바꾸고 있습니다.

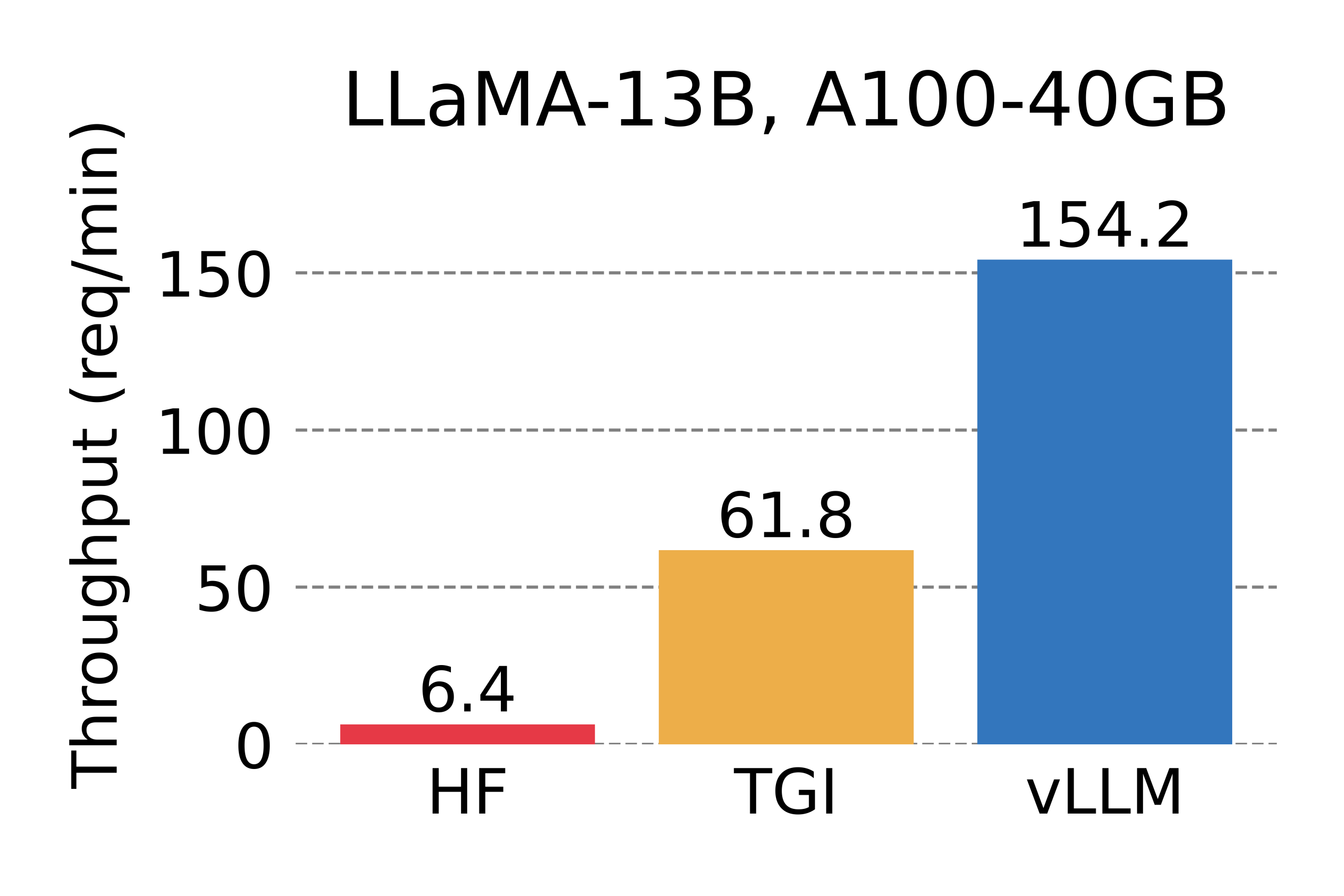
vLLM의 성능 벤치마크 결과 – A100 GPU에서 측정된 처리량 비교
LLM 서빙의 현실적 문제: 메모리 병목현상
LLM을 실제 서비스에 적용할 때 가장 큰 걸림돌은 바로 메모리 효율성입니다. 기존의 LLM 추론 과정에서는 모든 입력 토큰들이 어텐션(attention) 키와 값 텐서를 생성하고, 이들이 다음 토큰을 생성하기 위해 GPU 메모리에 저장되어야 합니다. 이렇게 캐시된 키-값 텐서들을 KV 캐시라고 부르는데, 이것이 바로 성능 병목의 주범입니다.
KV 캐시의 문제점은 다음과 같습니다:
크기가 매우 큽니다. LLaMA-13B 모델의 경우 단일 시퀀스당 최대 1.7GB까지 차지할 수 있습니다. 동적이고 예측 불가능합니다. 시퀀스 길이에 따라 크기가 달라지며, 실제 길이를 미리 알 수 없어 메모리 관리가 어렵습니다. 이로 인해 기존 시스템들은 메모리 단편화와 과도한 예약으로 인해 전체 메모리의 60-80%를 낭비하고 있었습니다.
PagedAttention: 운영체제에서 영감을 얻은 해결책
vLLM의 핵심 기술인 PagedAttention은 운영체제의 가상 메모리와 페이징 개념에서 영감을 얻었습니다. 기존의 어텐션 알고리즘과 달리, PagedAttention은 연속적인 키와 값을 비연속적인 메모리 공간에 저장할 수 있게 해줍니다.
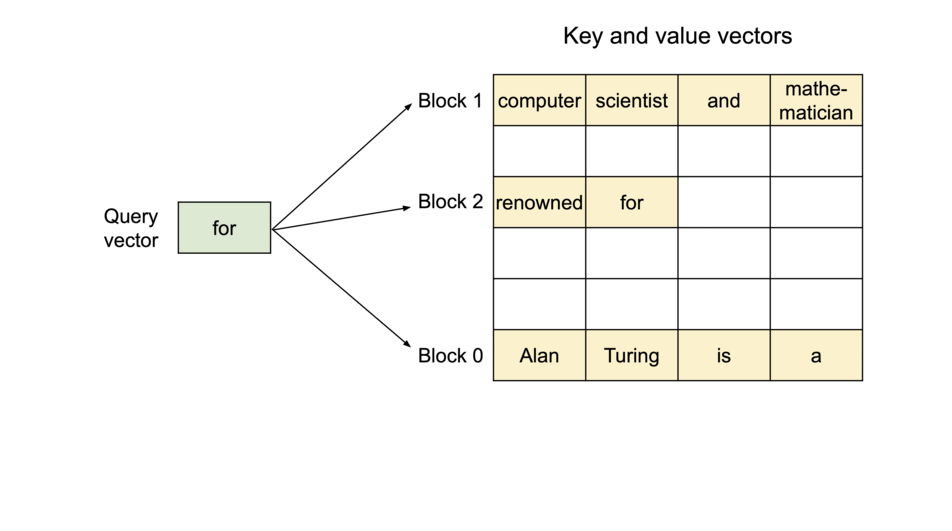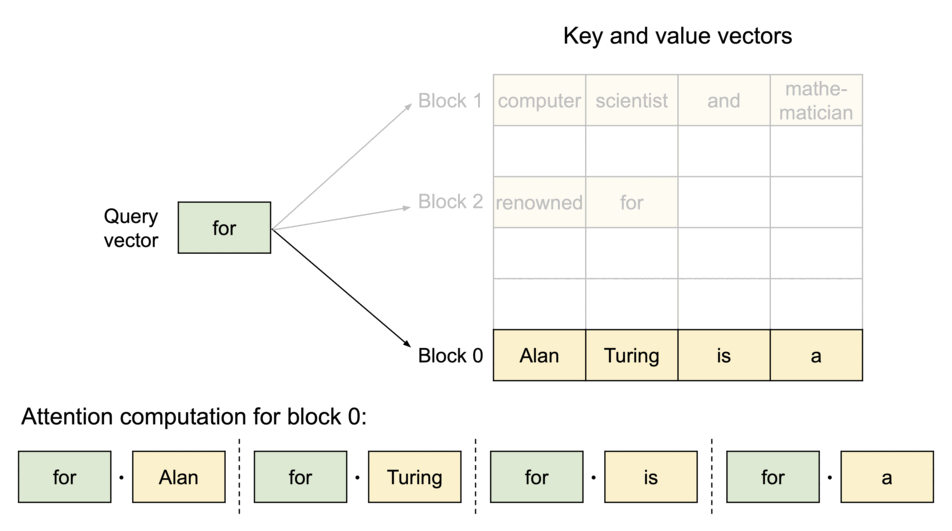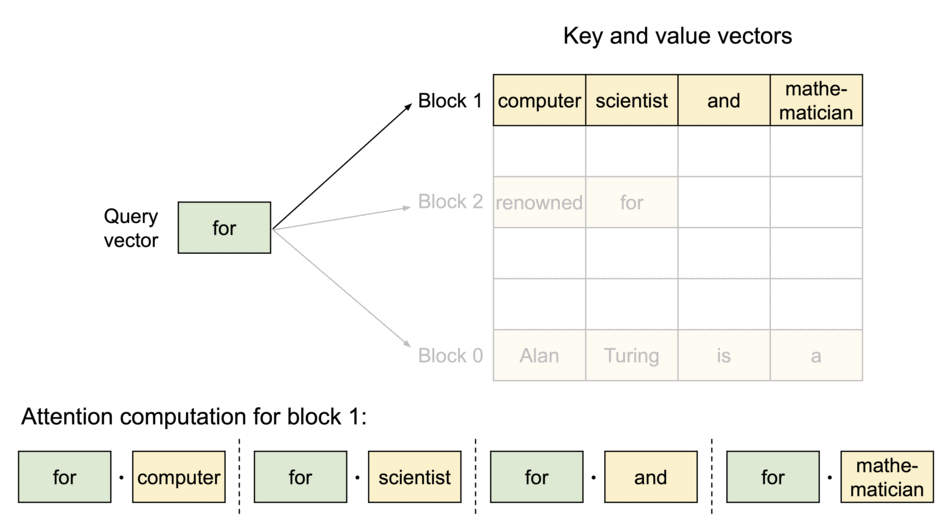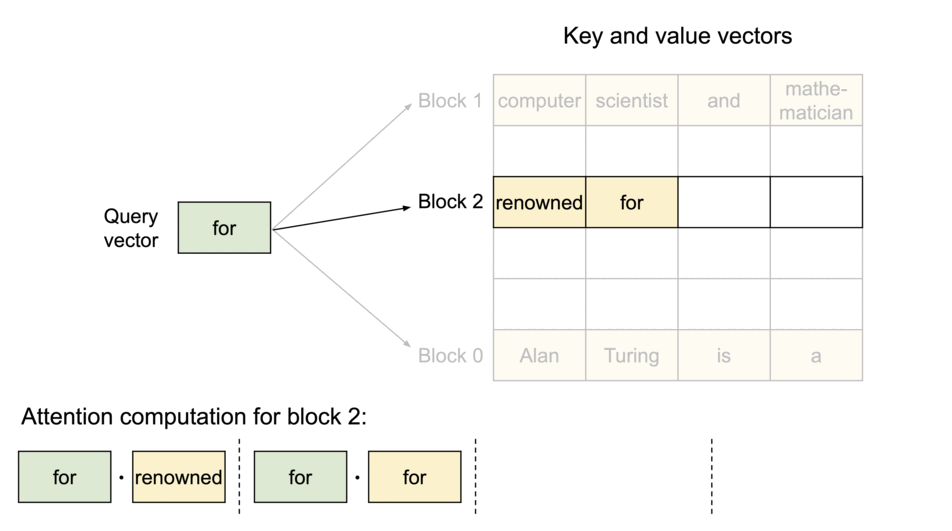
PagedAttention의 동작 원리: KV 캐시가 블록 단위로 분할되어 비연속적인 메모리 공간에 저장됩니다
작동 원리
PagedAttention은 각 시퀀스의 KV 캐시를 고정된 수의 토큰을 포함하는 블록들로 분할합니다. 어텐션 계산 중에는 PagedAttention 커널이 이러한 블록들을 효율적으로 식별하고 가져옵니다.
운영체제의 가상 메모리와 유사하게:
- 블록은 페이지 역할을 합니다
- 토큰은 바이트 역할을 합니다
- 시퀀스는 프로세스 역할을 합니다
시퀀스의 연속적인 논리 블록들이 블록 테이블을 통해 비연속적인 물리 블록들로 매핑되며, 새로운 토큰이 생성될 때마다 필요에 따라 물리 블록들이 할당됩니다.
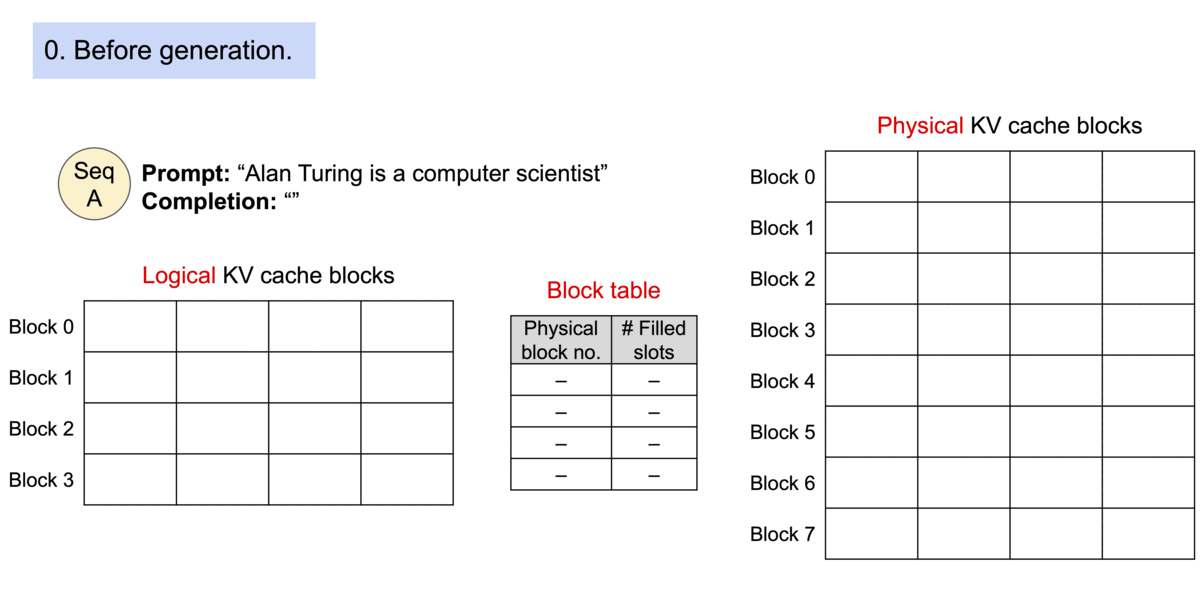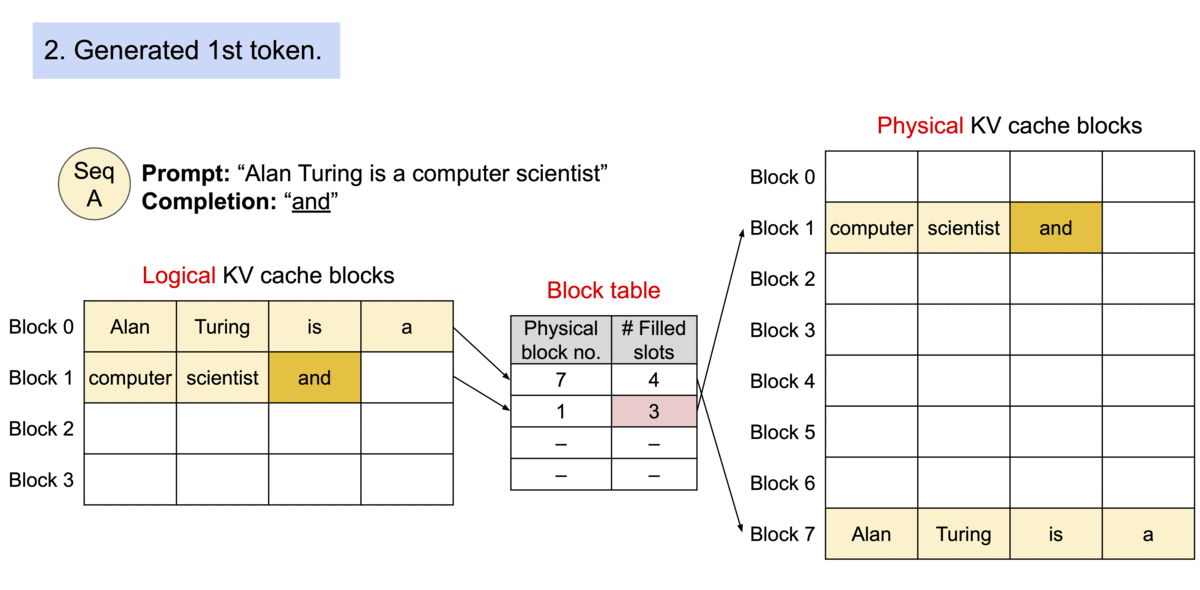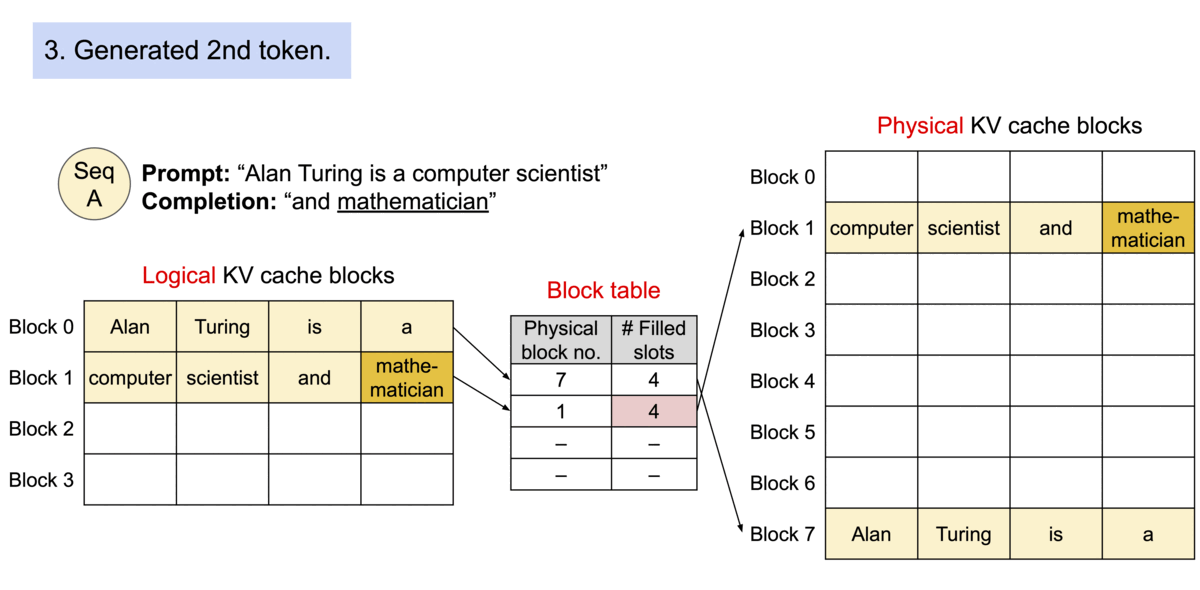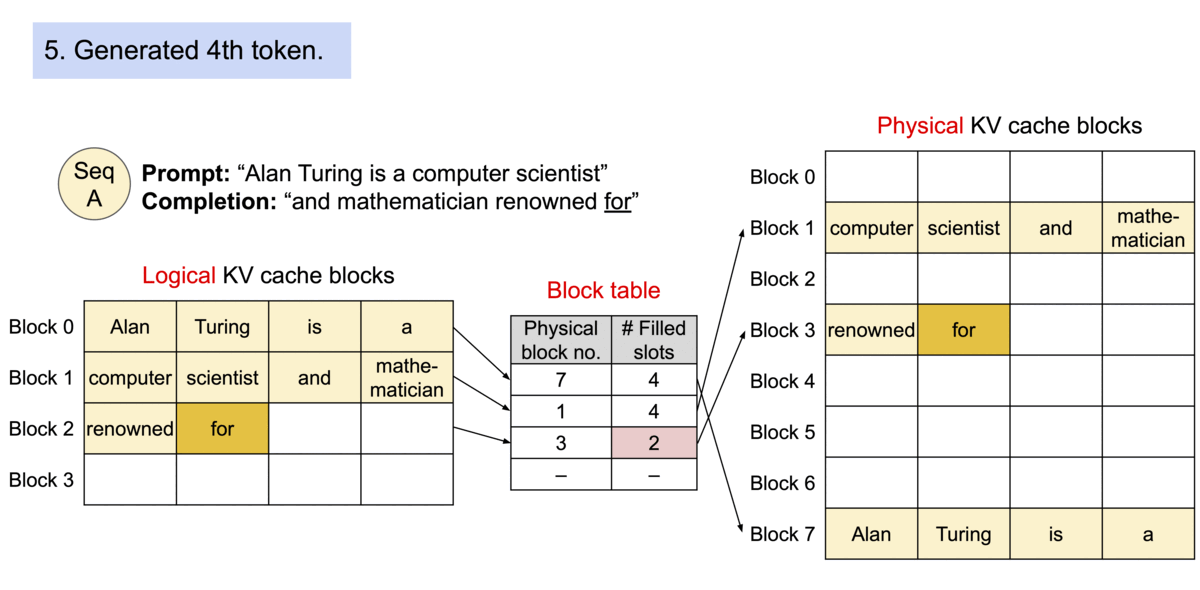
PagedAttention을 사용한 요청 생성 과정의 예시
메모리 효율성의 비약적 향상
PagedAttention에서는 메모리 낭비가 시퀀스의 마지막 블록에서만 발생합니다. 실제로는 4% 미만의 미미한 낭비만 있을 뿐, 거의 최적에 가까운 메모리 사용률을 달성합니다. 이러한 메모리 효율성의 향상으로 시스템은 더 많은 시퀀스를 배치 처리할 수 있게 되어 GPU 활용도가 증가하고 처리량이 크게 향상됩니다.
실제 성능: 검증된 놀라운 결과
vLLM의 성능은 실제 벤치마크를 통해 입증되었습니다. HuggingFace Transformers(HF)와 HuggingFace Text Generation Inference(TGI)와 비교한 결과:
- HuggingFace Transformers 대비 최대 24배 높은 처리량
- HuggingFace TGI 대비 최대 3.5배 높은 처리량

A10G GPU에서의 성능 비교 – 각 요청당 하나의 출력 완성을 요구하는 경우
특히 병렬 샘플링과 같은 복잡한 샘플링 알고리즘에서는 메모리 사용량을 최대 55%까지 줄여 처리량을 2.2배까지 향상시킬 수 있습니다.
실제 서비스에서의 검증: LMSYS Chatbot Arena
vLLM의 진정한 가치는 실제 프로덕션 환경에서 입증되었습니다. LMSYS의 Chatbot Arena에서는 2023년 4월부터 vLLM을 도입하여 수백만 사용자에게 Vicuna, Koala, LLaMA 등의 모델을 서비스하고 있습니다.
도입 결과:
- 일평균 30,000건, 최대 60,000건의 요청 처리
- GPU 사용량 50% 절감으로 운영비용 대폭 감소
- 기존 HF 백엔드 대비 30배 높은 처리량 달성
vLLM 시작하기: 설치부터 실행까지
시스템 요구사항
vLLM을 사용하기 위한 기본 요구사항은 다음과 같습니다:
- 운영체제: Linux
- Python: 3.9 ~ 3.12
- GPU: Compute capability 7.0 이상 (V100, T4, RTX20xx, A100, L4, H100 등)
설치 방법
가장 간단한 설치 방법은 pip을 사용하는 것입니다:
# 새로운 conda 환경 생성 (권장)
conda create -n myenv python=3.12 -y
conda activate myenv
# CUDA 12.1용 vLLM 설치
pip install vllm만약 CUDA 11.8을 사용하는 경우:
export VLLM_VERSION=0.6.1.post1
export PYTHON_VERSION=310
pip install https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux1_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118기본 사용법
1. 오프라인 추론
Python 스크립트에서 vLLM을 직접 사용하는 방법:
from vllm import LLM
# 샘플 프롬프트
prompts = ["Hello, my name is", "The capital of France is"]
# LLM 생성
llm = LLM(model="lmsys/vicuna-7b-v1.3")
# 텍스트 생성
outputs = llm.generate(prompts)2. 온라인 서빙
OpenAI API와 호환되는 서버를 시작하는 방법:
python -m vllm.entrypoints.openai.api_server --model lmsys/vicuna-7b-v1.3서버 쿼리 예시:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "lmsys/vicuna-7b-v1.3",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'메모리 공유: 효율성의 또 다른 차원
PagedAttention의 또 다른 강점은 효율적인 메모리 공유입니다. 병렬 샘플링처럼 동일한 프롬프트에서 여러 출력 시퀀스를 생성하는 경우, 프롬프트에 대한 계산과 메모리를 출력 시퀀스들 간에 공유할 수 있습니다.

병렬 샘플링에서의 메모리 공유 예시
PagedAttention은 블록 테이블을 통해 자연스럽게 메모리 공유를 가능하게 합니다. 운영체제에서 프로세스들이 물리 페이지를 공유하는 것처럼, PagedAttention에서는 서로 다른 시퀀스들이 논리 블록을 같은 물리 블록으로 매핑하여 블록을 공유할 수 있습니다.
안전한 공유를 보장하기 위해 PagedAttention은 물리 블록의 참조 카운트를 추적하고 Copy-on-Write 메커니즘을 구현합니다.
LLM 생태계에 미치는 영향
vLLM의 등장은 단순히 성능 향상을 넘어 LLM 생태계 전반에 중요한 변화를 가져오고 있습니다:
접근성 향상: 제한된 자원을 가진 소규모 팀이나 스타트업도 고성능 LLM 서비스를 구축할 수 있게 되었습니다. LMSYS처럼 대학 연구실 수준의 GPU 자원으로도 수백만 사용자에게 서비스를 제공할 수 있다는 것이 이를 증명합니다.
비용 효율성: GPU 사용량을 절반으로 줄이면서도 더 높은 성능을 달성할 수 있어, LLM 서비스의 경제성이 크게 향상되었습니다.
기술 민주화: 복잡한 최적화 없이도 뛰어난 성능을 얻을 수 있어, 더 많은 개발자들이 LLM 기반 애플리케이션을 개발할 수 있게 되었습니다.
vLLM은 현재도 활발히 개발되고 있으며, 더 많은 모델 지원과 기능 개선이 지속적으로 이루어지고 있습니다. PagedAttention이라는 혁신적인 접근법을 통해 LLM 서빙의 새로운 표준을 제시한 vLLM은 앞으로도 AI 서비스 개발의 핵심 도구로 자리잡을 것으로 기대됩니다.
참고자료:
답글 남기기