같은 과제, 50번 시도하면 3,547 QPS. 600번 시도하면 21,500 QPS. 중국 AI 기업 Z.ai가 새 모델 GLM-5.1로 실험한 결과입니다. 단순히 시간을 더 준 게 아니라, 더 오래 작업할수록 더 좋아지는 모델을 만들었다는 주장입니다.

출처: GLM-5.1: Towards Long-Horizon Tasks – Z.ai
Z.ai가 코딩·에이전트 특화 플래그십 모델 GLM-5.1을 MIT 라이선스 오픈소스로 공개했습니다. SWE-Bench Pro에서 최고 성능을 달성했지만, 이 모델의 진짜 차별점은 벤치마크 숫자보다 “얼마나 오래, 유용하게 작동하는가”에 있습니다.
“더 오래 줄수록 더 좋아진다”는 증명
기존 AI 모델들은 긴 작업에서 공통된 패턴을 보였습니다. 초반에 빠르게 성능을 올리다가 익숙한 방법이 소진되면 정체됩니다. 시간을 더 줘도 별 소용이 없었죠.
Z.ai는 이를 직접 실험으로 검증했습니다. 벡터 데이터베이스를 최적화하는 오픈소스 과제에서, 기존 50턴 제한 방식으로 낸 최고 기록은 3,547 QPS(초당 쿼리 처리량)였습니다. GLM-5.1에게 600번 이상 반복할 수 있는 환경을 주자 결과는 21,500 QPS, 약 6배로 뛰었습니다.
더 주목할 부분은 성장 방식입니다. 성능 그래프가 계단형으로 움직였습니다. 한 전략 안에서 점진적으로 조금씩 올리다가, 어느 순간 한계를 인식하고 구조적으로 다른 접근으로 전환하면서 성능이 확 뛰는 패턴이 반복됐습니다. 600번의 실험 동안 이런 큰 전환이 여섯 차례 일어났고, 각각은 모델이 스스로 벤치마크 로그를 분석한 뒤 병목을 찾아 시작한 것이었습니다.
숫자 없는 과제에서도 멈추지 않는다
QPS나 속도처럼 수치로 측정되는 과제라면 모델이 방향을 잡기 쉽습니다. Z.ai는 여기서 한 걸음 더 나아갔습니다.
GLM-5.1에게 “브라우저에서 돌아가는 리눅스 스타일 데스크톱 환경을 만들어라”는 지시를 내렸습니다. 시작 코드도, 디자인 목업도, 중간 피드백도 없었습니다. 기존 모델들은 대개 기본 레이아웃을 만든 뒤 “완료”를 선언했습니다. GLM-5.1은 달랐습니다. 매 실행 후 자신의 결과물을 검토하고, 부족한 부분을 스스로 찾아 계속 작업했습니다. 8시간 뒤에는 파일 브라우저, 터미널, 텍스트 에디터, 계산기, 게임까지 갖춘 완성도 있는 데스크톱 환경이 나왔습니다.
실제로 써보니
개발자 Simon Willison이 모델을 직접 써보고 흥미로운 행동을 발견했습니다. 펠리컨 SVG를 그려달라는 요청에 GLM-5.1이 지시 없이도 CSS 애니메이션을 스스로 추가했습니다. 애니메이션이 깨졌다고 알려주자, 모델은 SVG 좌표계와 CSS transform의 충돌을 정확히 짚어내 스스로 수정했습니다.
오픈소스로 공개
GLM-5.1은 754B 파라미터 규모로, HuggingFace에서 MIT 라이선스로 공개되어 있습니다. vLLM, SGLang 등 주요 추론 프레임워크를 지원하며, Claude Code·Cline·Roo Code 같은 코딩 에이전트와도 바로 연동됩니다.
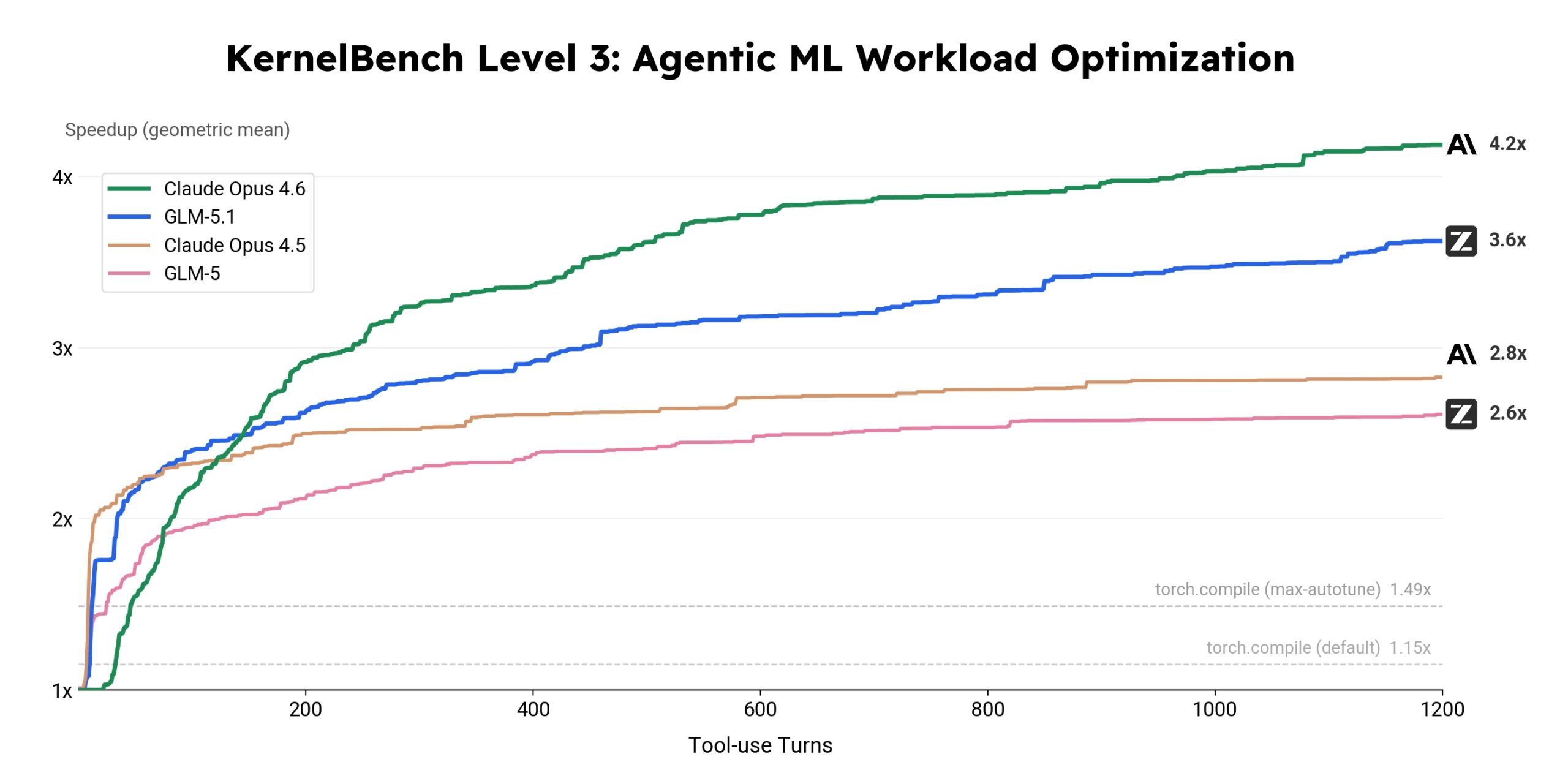
KernelBench 장기 최적화 실험에서는 Claude Opus 4.6(4.2×)이 GLM-5.1(3.6×)보다 높은 결과를 냈고, 일부 추론 벤치마크에서도 격차가 있습니다. Z.ai 스스로 로컬 최적값에 갇히는 문제, 수천 턴 실행 기록의 일관성 유지, 수치 없는 과제에서의 자기 평가를 아직 열린 과제로 꼽습니다. GLM-5.1은 그 방향의 첫 번째 시도입니다. 세 가지 시나리오의 상세한 결과와 전체 벤치마크 비교는 원문에서 확인할 수 있습니다.
참고자료:
- GLM-5.1 테스트 후기 – Simon Willison
- GLM-5.1 모델 가중치 – HuggingFace
답글 남기기