AI 기술은 빠르게 발전하고 있으며, 특히 멀티모달 AI 모델은 우리가 기계와 상호작용하는 방식을 혁신적으로 변화시키고 있습니다. 알리바바 클라우드의 Qwen 팀이 최근 발표한 Qwen2.5 시리즈는 이러한 변화의 최전선에 서 있습니다. 오늘은 Qwen2.5의 두 가지 핵심 모델인 ‘Qwen2.5-Omni’와 ‘Qwen2.5-VL’ 모델에 대해 자세히 알아보겠습니다.
Qwen2.5-Omni: 모든 감각을 가진 AI
 출처: Qwen 공식 블로그
출처: Qwen 공식 블로그
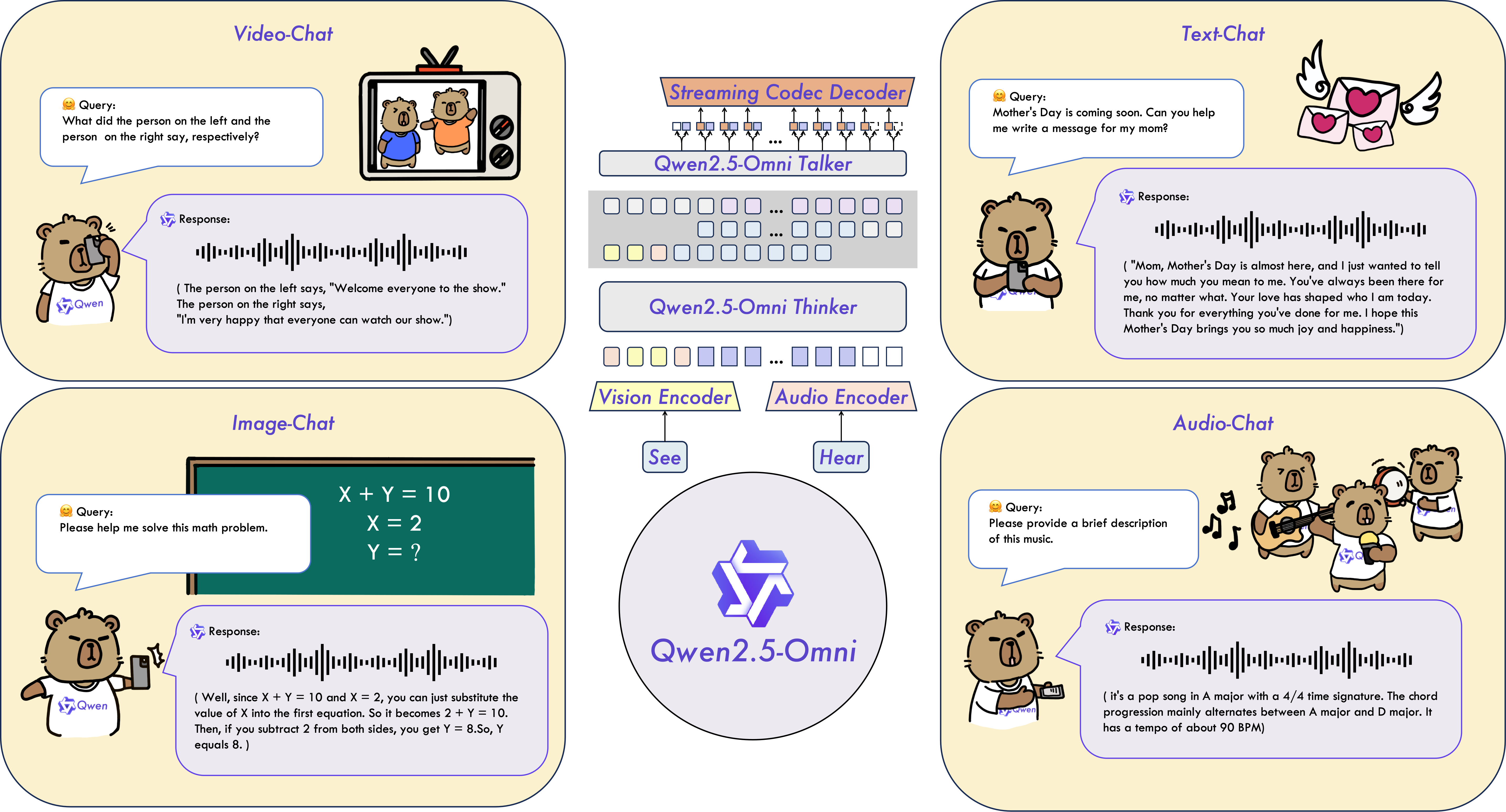
Qwen2.5-Omni는 Qwen 시리즈의 최신 플래그십 엔드투엔드 멀티모달 모델입니다. 이 모델은 텍스트, 이미지, 오디오, 비디오와 같은 다양한 입력을 원활하게 처리할 뿐만 아니라, 텍스트 생성과 자연스러운 음성 합성을 통해 실시간 스트리밍 응답을 제공합니다.
핵심 특징
- Thinker-Talker 아키텍처: Qwen2.5-Omni는 두 부분으로 구성된 혁신적인 아키텍처를 채택했습니다. ‘Thinker’는 다양한 입력을 이해하고 처리하는 뇌와 같은 역할을 담당하며, ‘Talker’는 Thinker가 생성한 정보를 자연스러운 음성으로 변환합니다. 또한 TMRoPE(Time-aligned Multimodal RoPE)라는 새로운 위치 임베딩 기술을 도입하여 비디오 입력의 타임스탬프와 오디오를 동기화합니다.
- 실시간 음성 및 비디오 채팅: 청크 단위 입력과 즉각적인 출력을 지원하는 완전한 실시간 상호작용이 가능합니다.
- 자연스럽고 견고한 음성 생성: 기존의 스트리밍 및 비스트리밍 대안보다 우수한 성능을 보이며, 음성 생성에 있어 탁월한 견고성과 자연스러움을 자랑합니다.
- 모든 모달리티에서 강력한 성능: 유사한 크기의 단일 모달리티 모델과 비교했을 때 모든 모달리티에서 뛰어난 성능을 보입니다. Qwen2.5-Omni는 비슷한 크기의 Qwen2-Audio보다 오디오 기능에서 더 뛰어나고, Qwen2.5-VL-7B와 비슷한 성능을 달성합니다.
- 우수한 엔드투엔드 음성 명령 처리: MMLU 및 GSM8K와 같은 벤치마크에서 입증된 바와 같이, Qwen2.5-Omni는 텍스트 입력만큼 효과적인 엔드투엔드 음성 명령 처리 성능을 보여줍니다.
아키텍처
 출처: Qwen 공식 블로그
출처: Qwen 공식 블로그
Qwen2.5-Omni의 아키텍처는 크게 Thinker와 Talker로 구분됩니다. Thinker는 트랜스포머 디코더로, 오디오 및 이미지를 위한 인코더와 함께 정보 추출을 용이하게 합니다. 반면 Talker는 이중 트랙 자기회귀 트랜스포머 디코더 아키텍처로 설계되었습니다. 학습과 추론 과정에서 Talker는 Thinker로부터 고차원 표현을 직접 받고 Thinker의 모든 역사적 맥락 정보를 공유합니다. 결과적으로 전체 아키텍처는 엔드투엔드 학습과 추론이 가능한 단일 모델로 작동합니다.
성능
Qwen2.5-Omni는 OmniBench와 같은 여러 모달리티 통합이 필요한 작업에서 최첨단 성능을 달성합니다. 또한 단일 모달리티 작업에서도 뛰어난 성과를 보여줍니다.
- 음성 인식: Common Voice 벤치마크에서 뛰어난 성능
- 번역: CoVoST2에서 높은 정확도
- 오디오 이해: MMAU 테스트에서 우수함
- 이미지 추론: MMMU, MMStar 등에서 뛰어난 성능
- 비디오 이해: MVBench 벤치마크에서 높은 점수
- 음성 생성: 자연스러운 음성 생성 능력
 출처: Qwen 공식 블로그
출처: Qwen 공식 블로그
Qwen2.5-VL: 더 스마트하고 가벼워진 비전-언어 모델
 출처: Qwen 공식 블로그
출처: Qwen 공식 블로그
2025년 1월 말에 출시된 Qwen2.5-VL 시리즈는 강화 학습을 통해 최적화되어 Qwen2.5-VL-32B-Instruct라는 이름으로 Apache 2.0 라이선스 하에 오픈소스로 공개되었습니다. 이 모델은 이전 버전인 Qwen2.5-VL 시리즈보다 여러 측면에서 개선되었습니다.
주요 특징
- 인간의 선호도에 더 맞는 응답: 출력 스타일이 조정되어 더 상세하고, 더 나은 형식의 답변을 제공하며, 인간의 선호도에 더 가깝게 조정되었습니다.
- 수학적 추론: 복잡한 수학 문제 해결의 정확도가 크게 향상되었습니다.
- 세밀한 이미지 이해 및 추론: 이미지 파싱, 콘텐츠 인식, 시각적 논리 추론과 같은 작업에서 향상된 정확도와 상세 분석을 제공합니다.
성능
Qwen2.5-VL-32B-Instruct는 비슷한 규모의 최첨단(SoTA) 모델들과 광범위한 벤치마크를 통해 Mistral-Small-3.1-24B 및 Gemma-3-27B-IT와 같은 기준 모델보다 우수하며, 심지어 더 큰 Qwen2-VL-72B-Instruct보다도 성능이 좋습니다. 특히 MMMU, MMMU-Pro, MathVista와 같은 복잡하고 다단계 추론에 중점을 둔 멀티모달 작업에서 상당한 이점을 보여줍니다. 주관적인 사용자 경험 평가를 강조하는 MM-MT-Bench에서는 Qwen2.5-VL-32B-Instruct가 이전 버전인 Qwen2-VL-72B-Instruct보다 상당한 차이로 앞서고 있습니다.
시각적 능력 외에도 Qwen2.5-VL-32B-Instruct는 순수 텍스트 능력에서도 동일한 규모에서 최고 수준의 성능을 달성했습니다.
 출처: Qwen 공식 블로그
출처: Qwen 공식 블로그
Qwen2.5 모델의 의의
Qwen2.5 모델 시리즈는 AI의 발전에 있어 중요한 단계를 나타냅니다. 특히 Qwen2.5-Omni와 같은 모델은 다양한 모달리티를 통합하여 인간의 인지 방식에 더 가까운 AI 시스템의 개발로 한 걸음 더 나아갔습니다. 이는 더 자연스럽고 직관적인 인간-AI 상호작용의 미래를 열어줍니다.
이러한 모델의 개방적인 접근 방식과 Apache 2.0 라이선스 하에 제공되는 접근성은 더 넓은 연구 및 개발 커뮤니티가 이러한 기술을 기반으로 구축하고 개선할 수 있도록 합니다. 이는 AI 발전의 민주화로 이어지며, 더 많은 혁신과 응용 프로그램을 촉진할 수 있습니다.
실제 활용 사례
Qwen2.5 모델은 다음과 같은 다양한 실제 응용 분야에서 활용될 수 있습니다:
- 콘텐츠 제작: 텍스트, 이미지, 오디오를 포함한 멀티모달 콘텐츠 생성
- 가상 비서: 자연스러운 음성 상호작용과 다양한 입력 처리가 가능한 지능형 비서
- 교육: 다양한 형식의 교육 자료를 분석하고 생성하는 지능형 튜터링 시스템
- 접근성: 시각 또는 청각 장애인을 위한 콘텐츠 변환 및 지원
- 고객 서비스: 다중 채널을 통해 사용자 요청을 이해하고 응답하는 지능형 고객 서비스 봇
미래 전망
Qwen 팀은 향후 모델의 음성 명령 처리 능력을 강화하고 오디오-시각적 협력 이해를 개선할 계획입니다. 또한 ‘옴니 모델’을 향해 더 많은 모달리티를 통합하는 것을 목표로 하고 있습니다.
Qwen2.5와 같은 모델의 발전은 AI가 정보를 이해하고 상호작용하는 방식을 계속해서 변화시킬 것입니다. 이러한 진보는 AI 기술이 우리의 일상 생활과 업무에 더욱 원활하게 통합될 수 있는 가능성을 열어줍니다.
결론
Qwen2.5 모델 시리즈는 AI의 미래에 대한 흥미로운 통찰을 제공합니다. 특히 Qwen2.5-Omni는 다양한 모달리티를 통합하는 능력으로 AI가 세상을 인식하고 상호작용하는 방식에 혁명을 일으키고 있습니다. 이러한 발전은 인간과 기계 사이의 의사소통 장벽을 허물고, 더 자연스럽고 직관적인 상호작용을 가능하게 합니다.
이 기술이 발전함에 따라 더 많은 응용 분야와 가능성이 등장할 것이며, AI 기술의 접근성과 활용 가능성이 더욱 커질 것입니다. Qwen2.5와 같은 모델은 우리가 AI와 상호작용하는 방식의 미래를 형성하는 데 중요한 역할을 할 것입니다.
답글 남기기