GPT부터 Claude, Llama까지, 요즘 쓰이는 거의 모든 LLM은 같은 방식으로 작동합니다. 2017년 “Attention Is All You Need” 논문에서 소개된 Transformer 아키텍처를 기반으로, 단어를 하나씩 순차적으로 생성하죠. 이 방식은 검증됐고 안정적이지만, 효율성이나 성능 면에서 한계도 분명합니다.
긴 문서를 처리할 때 메모리가 기하급수적으로 늘어나고, 한 번에 한 단어씩만 생성할 수 있어 느립니다. 연구자들은 이런 문제를 해결하려고 다양한 대안을 실험 중입니다.

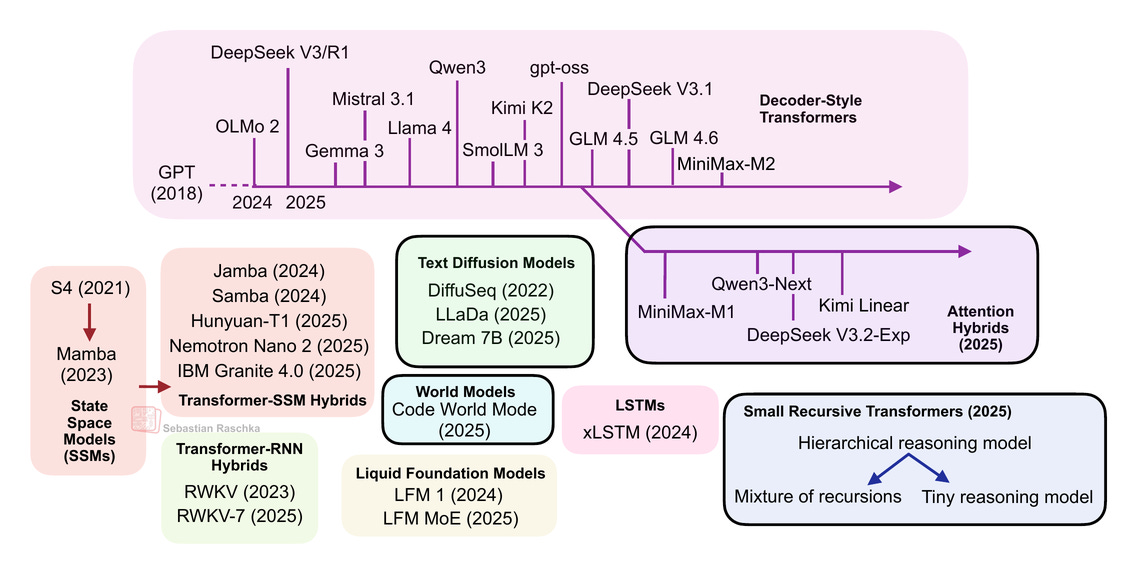
AI 연구자 Sebastian Raschka가 최근 발표한 글에서 표준 LLM을 넘어서는 5가지 대안 아키텍처를 정리했습니다. 각각의 장단점과 실제 적용 사례를 살펴보겠습니다.
출처: Beyond Standard LLMs – Sebastian Raschka
1. Linear Attention 하이브리드: 메모리 문제 해결하기
대표 모델: Qwen3-Next, Kimi Linear
표준 Transformer의 가장 큰 문제는 Attention 메커니즘이 입력 길이의 제곱에 비례해 계산량이 늘어난다는 점입니다. 1,000개 토큰을 처리할 때와 2,000개를 처리할 때 필요한 계산량이 4배 차이 나죠.
Linear Attention은 이 문제를 해결합니다. 전통적인 Attention처럼 모든 단어가 서로를 “바라보는” 대신, RNN처럼 순차적으로 고정 크기 메모리를 업데이트합니다. Qwen3-Next는 Gated DeltaNet이라는 메커니즘을 사용해 토큰을 하나씩 처리하면서 상태를 갱신합니다.
흥미로운 점은 이들 모델이 Linear Attention “만” 쓰지 않는다는 겁니다. Qwen3-Next와 Kimi Linear는 3:1 비율로 Linear Attention과 전통적인 Full Attention을 섞어 씁니다. 효율성은 챙기되 장거리 맥락 이해 능력은 유지하는 전략이죠.
장점: KV 캐시 75% 감소, 디코딩 속도 최대 6배 향상
단점: 전역 컨텍스트 모델링 능력은 여전히 Full Attention에 미치지 못함
2. Text Diffusion 모델: 이미지 생성 기술을 텍스트로
대표 모델: LLaDA, Google Gemini Diffusion
Stable Diffusion 같은 이미지 생성 모델의 작동 방식을 텍스트에 적용한 접근법입니다. 표준 LLM이 단어를 순차적으로 생성하는 반면, Diffusion 모델은 모든 위치를 동시에 처리합니다.
처음엔 모든 위치가 [MASK] 토큰으로 채워져 있고, 여러 번의 “디노이징” 단계를 거치며 점차 실제 단어로 바뀝니다. 마치 흐릿한 이미지가 점점 선명해지는 것처럼요. 2,000개 단어를 생성할 때, 순차적으로 2,000번 생성하는 대신 20-60번의 디노이징 단계만으로 처리할 수 있어 이론적으로는 훨씬 빠릅니다.
하지만 실제로는 트레이드오프가 있습니다. 디노이징 단계를 적게 쓰면 빠르지만 품질이 떨어지고, 많이 쓰면 품질은 좋지만 표준 LLM만큼 느려집니다. 또한 도구를 사용하거나 중간 결과를 확인하는 “체인” 방식 추론이 어렵다는 한계도 있습니다.
장점: 병렬 생성으로 속도 향상 가능
단점: 스트리밍 불가, 도구 사용 제한적, 아직 SOTA 수준 미달
3. Code World Model: 코드 실행을 시뮬레이션하는 AI
대표 모델: Code World Model (CWM)
일반 코드 LLM(예: Qwen3-Coder)은 코드 패턴을 학습해 그럴듯한 코드를 생성합니다. 하지만 CWM은 한 단계 더 나아갑니다. 코드가 실제로 “실행되면 어떻게 될지”를 예측하도록 학습됩니다.
예를 들어 변수에 값을 할당하는 코드를 보면, 실행 후 그 변수가 어떤 값을 가질지 예측합니다. 일종의 내부 시뮬레이터를 갖춘 셈이죠. 이런 “세계 모델” 접근은 원래 로보틱스와 강화학습 분야에서 쓰이던 개념인데, 최근 코드 도메인에 처음 적용됐습니다.
32B 파라미터 규모로 gpt-oss-20b(중간 추론 수준)와 대등한 성능을 보이며, 테스트 타임 스케일링을 적용하면 gpt-oss-120b(높은 추론 수준)보다 나은 결과도 냅니다. 코드를 단순히 텍스트로 보지 않고 “실행 가능한 논리”로 이해한다는 점에서 흥미로운 방향입니다.
장점: 코드 이해 능력 향상, 검증 가능한 중간 상태
단점: 실행 트레이스 포함으로 학습 복잡도 증가, 추론 시 지연 시간
4. 작은 재귀적 Transformer: 퍼즐 풀기 전문가
대표 모델: Hierarchical Reasoning Model (HRM), Tiny Recursive Model (TRM)
LLM은 크면 클수록 좋다는 통념에 반기를 드는 모델들입니다. TRM은 겨우 700만 개 파라미터로 ARC 챌린지에서 상위권을 차지했습니다. 비결은 “재귀적 개선”입니다.
한 번의 계산으로 답을 내는 대신, 자신의 답을 반복적으로 다듬어갑니다. 각 단계에서 잠재 추론 상태(일종의 “생각”)를 업데이트하고, 그걸 바탕으로 답을 조금씩 개선하죠. 마치 초안을 여러 번 고쳐 쓰는 것과 비슷합니다.
흥미롭게도, 레이어를 줄일수록(4개→2개) 성능이 올라갔고, 심지어 Attention을 제거하고 순수 MLP로만 구성해도 잘 작동했습니다. 물론 이는 스도쿠나 미로 찾기 같은 고정된 크기의 격자 문제에만 해당합니다.
현재로선 범용 LLM이라기보단 특수 목적 추론 모듈에 가깝습니다. 하지만 H100 4개로 이틀, 500달러 미만으로 학습할 수 있다는 점이 고무적입니다. 대규모 데이터센터 없이도 의미 있는 연구가 가능하다는 증거니까요.
장점: 매우 작은 크기, 퍼즐 문제에서 뛰어난 성능
단점: 특수 목적 모델, 아직 텍스트/코드 작업에는 미적용
5. 그 외: State Space Model과 xLSTM
Raschka의 글은 Mamba 같은 State Space Model이나 xLSTM도 언급하지만, 이들은 별도의 깊은 다이빙이 필요한 주제입니다. State Space Model은 RNN의 효율성과 Transformer의 병렬성을 결합하려는 시도이며, Linear Attention과도 연결점이 있습니다.
표준 LLM은 여전히 왕
이런 대안들이 흥미롭긴 하지만, Raschka는 명확히 말합니다. 지금 새 프로젝트를 시작한다면 여전히 표준 Transformer 기반 LLM을 선택하겠다고요.
이유는 간단합니다. 검증됐고, 툴링이 성숙했으며, 스케일링 법칙을 알고 있고, 무엇보다 현재 최고 성능(SOTA)을 보여주니까요. 대안 아키텍처들은 대부분 효율성을 위해 약간의 정확도를 희생합니다.
하지만 긴 컨텍스트 작업이나 온디바이스 배포처럼 효율성이 핵심인 경우라면? 그때는 Linear Attention 하이브리드나 작은 Diffusion 모델이 실용적 선택지가 될 수 있습니다. 그리고 특정 도메인(코딩, 퍼즐 등)에선 전문화된 모델이 범용 LLM보다 효율적일 수 있죠.
AI 연구는 계속 진화합니다. 표준 레시피만 따르는 게 아니라 근본적으로 다른 접근을 시도하는 연구자들 덕분에, 우리는 언젠가 지금보다 훨씬 빠르고 똑똑한 AI를 만날 수 있을 겁니다.
참고자료:
답글 남기기