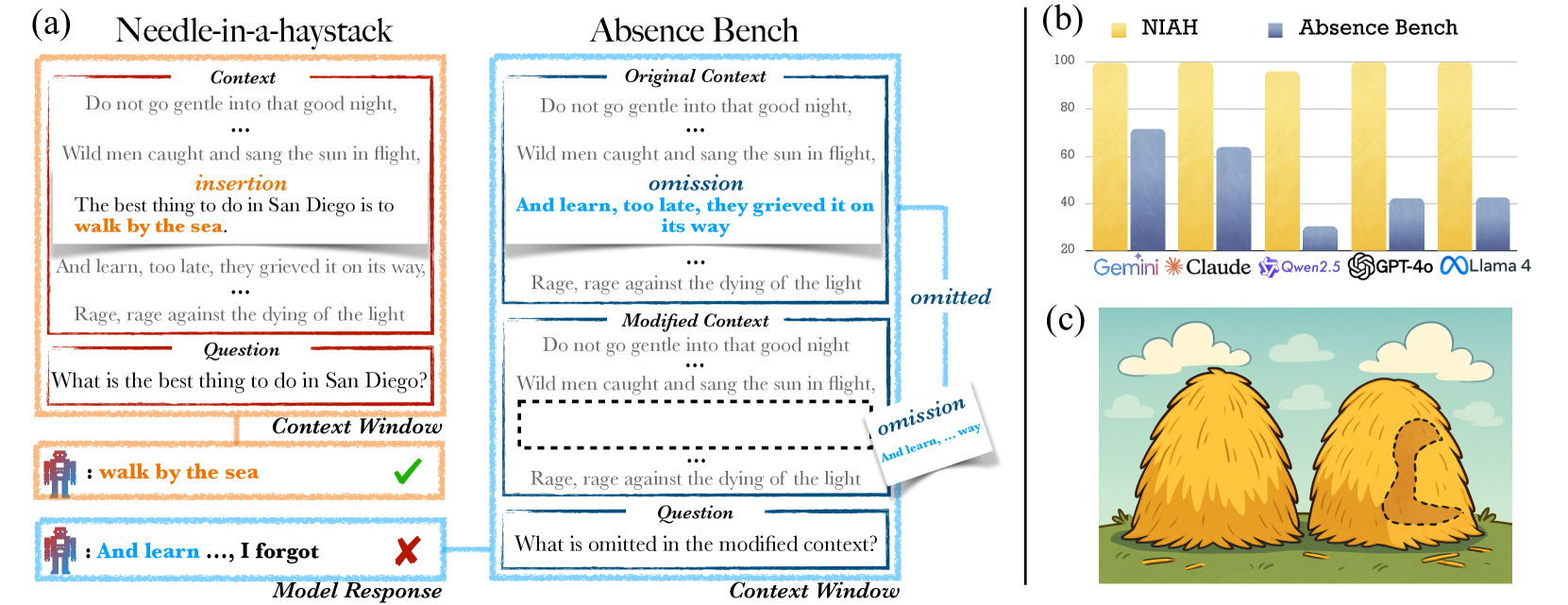
최근 대형 언어모델(LLM)들은 방대한 텍스트에서 특정 정보를 찾아내는 능력에서 놀라운 성과를 보여주고 있습니다. 특히 ‘바늘을 건초더미에서 찾기(Needle in a Haystack, NIAH)’ 테스트에서는 수백만 토큰의 긴 텍스트 속에서도 숨겨진 정보를 정확히 찾아내며 인간을 뛰어넘는 성능을 보였습니다. 그런데 만약 정보를 찾는 것이 아니라, 빠진 정보를 찾는다면 어떨까요?

시카고 대학과 스탠포드 대학의 연구진이 발표한 “AbsenceBench” 연구는 AI의 예상치 못한 약점을 드러냈습니다. 정보를 찾는 데는 뛰어난 LLM들이 누락된 정보를 탐지하는 데는 현저히 부족하다는 충격적인 결과를 보여준 것입니다.
NIAH의 성공과 AbsenceBench의 등장
NIAH 테스트는 긴 텍스트 속에 의도적으로 삽입한 특별한 정보(바늘)를 모델이 얼마나 잘 찾아내는지 평가하는 방법입니다. 최신 LLM들은 이 테스트에서 거의 완벽한 성능을 보이며, 심지어 수백만 토큰의 극도로 긴 텍스트에서도 정확한 정보 검색이 가능함을 입증했습니다.
하지만 연구진은 여기서 반대의 질문을 던졌습니다. “정보를 찾는 것은 잘하지만, 빠진 정보를 알아차릴 수 있을까?” 이 질문에서 AbsenceBench가 탄생했습니다.
AbsenceBench: 누락을 찾는 새로운 도전
AbsenceBench는 세 가지 영역에서 LLM의 누락 탐지 능력을 평가합니다:

1. 시(Poetry) 영역
구텐베르크 시 코퍼스에서 가져온 시들에서 특정 줄들을 제거한 후, 모델이 어떤 줄이 빠졌는지 찾아내도록 합니다. 예를 들어:
원본:
And so, to you, who always were
To me, I give these weedy rhymes
In memory of early times수정본:
And so, to you, who always were
In memory of early times모델은 “To me, I give these weedy rhymes” 줄이 빠졌다는 것을 찾아내야 합니다.
2. 숫자 시퀀스 영역
일정한 패턴을 가진 숫자 시퀀스에서 특정 숫자들을 제거하고, 어떤 숫자가 빠졌는지 식별하도록 합니다.
3. GitHub 풀 리퀘스트 영역
실제 GitHub의 상위 20개 저장소에서 가져온 풀 리퀘스트의 diff에서 특정 라인들을 제거하고, 누락된 코드 라인을 찾아내도록 합니다.

충격적인 결과: 최고 모델도 70% 미만
연구 결과는 놀라웠습니다. Claude-3.7-Sonnet, GPT-4, Gemini-2.5-flash 등 최고 성능의 14개 LLM을 대상으로 한 실험에서:
- 최고 성능 모델인 Gemini-2.5-flash도 71.2% F1-score에 그침
- Claude-3.7-Sonnet은 69.6%, GPT-4는 42.0%의 성능
- NIAH 테스트에서 거의 완벽한 성능을 보이던 모델들이 평균 56.9%의 성능 하락을 보임
- GitHub 풀 리퀘스트 영역에서는 최고 모델도 40% 수준의 성능
특히 주목할 점은 Mixtral-8x7B 모델의 경우입니다. 동일한 길이의 NIAH 테스트에서는 완벽한 점수를 받았지만, AbsenceBench에서는 고작 14.7%의 성능을 보였습니다.
추론 모델의 한계: 비용 대비 효과 부족
연구진은 o3-mini, DeepSeek-R1 등 추론 시간 컴퓨팅을 활용하는 모델들도 평가했습니다. 이 모델들은 답을 생성하기 전에 ‘생각하는’ 과정을 거치는데, 결과는 다음과 같았습니다:
- 성능 향상은 평균 7.9%에 불과
- 대신 평균 8,000개의 추가 토큰을 생성 (원본 문서 길이의 3배)
- Gemini-2.5-flash는 원본 문서 대비 5.7배의 생각 토큰을 생성
이는 추론 모델들이 누락된 정보를 찾기 위해 원본 문서를 재구성하려고 시도하지만, 비용 대비 효과가 크지 않음을 보여줍니다.

원인 분석: Transformer의 구조적 한계
연구진은 이러한 성능 저하의 원인을 Transformer 아키텍처의 구조적 한계에서 찾았습니다. Transformer의 attention 메커니즘은 존재하는 토큰들 간의 관계에 집중하도록 설계되어 있어, ‘빈 공간’이나 ‘부재’에는 주의를 기울이기 어렵다는 것입니다.
이를 검증하기 위해 연구진은 흥미로운 실험을 진행했습니다. 누락된 부분에 <missing line>이나 __________ 같은 플레이스홀더를 삽입했더니, 성능이 평균 35.7% 향상되었습니다. 이는 명시적인 표시가 있을 때 모델의 성능이 크게 개선됨을 보여줍니다.

실무적 시사점: AI 활용 시 주의사항
이 연구 결과는 실무에서 LLM을 활용할 때 중요한 시사점을 제공합니다:
1. AI 검토 도구의 한계 인식
문서 검토나 코드 리뷰에서 LLM을 활용할 때, 누락된 내용을 찾아내는 데는 한계가 있음을 인식해야 합니다. 특히 LLM-as-a-Judge 같은 평가 시스템에서 이러한 맹점을 고려해야 합니다.
2. 보완 전략 필요
- 체크리스트 기반 검증: 필수 요소들이 모두 포함되었는지 명시적으로 확인
- 구조화된 템플릿 사용: 빠질 수 있는 부분을 사전에 표시
- 인간-AI 협업: AI의 강점(정보 검색)과 인간의 강점(전체적 맥락 파악)을 결합
3. 맥락 길이와 누락 비율 고려
연구에 따르면 맥락이 길어질수록, 그리고 누락 비율이 낮을수록 성능이 떨어집니다. 이는 산발적으로 흩어진 소수의 누락이 연속된 대량 누락보다 탐지하기 어렵다는 것을 의미합니다.
대안적 접근법: 명시적 표시의 효과
연구에서 가장 인상적인 발견 중 하나는 누락 부분을 명시적으로 표시했을 때의 성능 향상입니다. 이는 실무에서 다음과 같이 응용할 수 있습니다:
- 문서 템플릿에 필수 섹션 미리 표시
- 코드 리뷰 시 주요 체크포인트 명시
- 회의록이나 보고서에서 필수 항목 사전 정의
미래 전망: AI 개발의 새로운 방향
AbsenceBench는 단순히 LLM의 한계를 지적하는 것을 넘어, AI 개발의 새로운 방향을 제시합니다:
1. 구조적 개선 필요
현재의 Transformer 아키텍처가 ‘부재’를 다루는 데 한계가 있다면, 이를 보완할 새로운 아키텍처나 메커니즘이 필요합니다.
2. 훈련 방식의 혁신
누락 탐지 능력을 향상시키기 위한 새로운 훈련 방법론 개발이 필요합니다. 예를 들어, 의도적으로 정보를 제거한 데이터셋으로 훈련하는 방법을 고려할 수 있습니다.
3. 평가 기준의 다양화
NIAH 같은 검색 중심 테스트뿐만 아니라, AbsenceBench처럼 다양한 인지 능력을 평가하는 벤치마크가 더 필요합니다.
인간과 AI의 차이점
이 연구는 인간과 AI의 인지 방식에 대한 흥미로운 통찰을 제공합니다. 인간은 맥락과 기대를 바탕으로 무엇이 빠졌는지 직관적으로 알아차릴 수 있지만, 현재의 AI는 명시적으로 제시된 정보에만 집중하는 경향이 있습니다.
이는 AI가 아직 인간과 같은 ‘상식적 추론’이나 ‘맥락적 이해’에는 한계가 있음을 보여줍니다. 동시에 이러한 한계를 인식하고 보완하는 것이 더 신뢰할 수 있는 AI 시스템 구축의 핵심임을 시사합니다.
결론: 완벽하지 않은 AI와의 현명한 협업
AbsenceBench 연구는 최신 LLM들이 여전히 예상치 못한 약점을 가지고 있음을 보여줍니다. 정보를 찾는 데는 뛰어나지만 누락을 탐지하는 데는 부족한 이러한 특성을 이해하는 것은 AI를 더 효과적으로 활용하는 데 필수적입니다.
이는 AI가 만능이 아니며, 인간의 판단과 검증이 여전히 중요함을 의미합니다. 동시에 AI의 한계를 인식하고 이를 보완하는 방법을 개발하는 것이 다음 세대 AI 시스템의 핵심 과제가 될 것입니다.
앞으로 AI를 활용할 때는 “AI가 무엇을 잘하는가”뿐만 아니라 “AI가 무엇을 놓칠 수 있는가”도 함께 고려해야 할 때입니다. AbsenceBench가 제시한 이러한 통찰은 더 신뢰할 수 있는 AI-인간 협업 시스템 구축의 중요한 출발점이 될 것입니다.
참고자료:
답글 남기기