기업들이 AI 에이전트에 수십억 달러를 쏟아붓고 있습니다. 하지만 멋진 데모는 잘 작동하는데, 막상 실제 비즈니스 환경에 투입하면 제대로 작동하지 않는 경우가 많죠. 왜 그럴까요?

Persistent Systems의 R&D 아키텍트 Dattaraj Rao가 VentureBeat에 기고한 글은 이 문제의 근본 원인과 해결책을 제시합니다. API 통합이나 모델 컨텍스트 프로토콜(MCP) 같은 기술적 연결은 잘 되는데, 정작 에이전트가 비즈니스 데이터의 “의미”를 이해하지 못한다는 게 핵심입니다.
출처: Ontology is the real guardrail: How to stop AI agents from misunderstanding your business – VentureBeat
같은 단어, 다른 의미: 비즈니스 맥락의 함정
문제를 구체적으로 보죠. “고객(customer)”이라는 단어를 생각해보세요. 영업 CRM 시스템에서는 잠재 고객을 포함한 모든 접촉 대상을 의미할 수 있습니다. 하지만 재무 시스템에서는 실제로 돈을 지불한 클라이언트만 “고객”으로 분류하죠.
“제품(product)”은 어떨까요? 한 부서는 SKU 단위로, 다른 부서는 제품군(family)으로, 또 다른 곳은 마케팅 번들로 정의합니다. 이런 상황에서 “제품 판매” 데이터를 여러 시스템에서 가져와 분석하려는 AI 에이전트는 혼란에 빠집니다. 합의된 정의와 관계가 없으면 같은 용어가 전혀 다른 의미를 갖게 되거든요.
여기에 스키마 변경이나 데이터 품질 문제까지 더해지면 에이전트는 어떻게 행동해야 할지 알 수 없게 됩니다. PII(개인식별정보) 같은 민감한 데이터 분류도 GDPR, CCPA 같은 규정 준수를 위해 정확해야 하는데, 이 역시 에이전트가 제대로 이해하고 존중해야 하는 맥락이죠.
온톨로지: 비즈니스 정의의 단일 진실 공급원
저자가 제안하는 해결책은 온톨로지(Ontology) 기반의 단일 진실 공급원을 구축하는 것입니다. 온톨로지는 비즈니스 개념과 그 계층, 관계를 정의하는 프레임워크예요. 비즈니스 도메인에 맞게 용어를 정의하고, 데이터에 대한 단일 진실 공급원을 수립하며, 통일된 필드명과 분류를 적용합니다.
의료나 금융처럼 도메인별 온톨로지도 있고, 조직 내부 구조에 맞춘 온톨로지도 있습니다. 처음 정의하는 데는 시간이 걸리지만, 비즈니스 프로세스를 표준화하고 에이전트 AI의 탄탄한 토대를 만들 수 있죠.
실제 구현에서는 트리플스토어(triplestore) 같은 쿼리 가능한 형식을 사용하거나, 더 복잡한 비즈니스 규칙에는 Neo4j 같은 레이블 속성 그래프를 활용합니다. 금융 산업의 FIBO(Finance Industry Business Ontology)나 의료 분야의 UMLS(Unified Medical Language System) 같은 공개 온톨로지도 좋은 출발점이 됩니다.
환각을 막는 구조적 가드레일
온톨로지가 구축되면, AI 에이전트에게 이를 따르도록 프롬프트할 수 있습니다. 비즈니스 규칙과 정책을 온톨로지에 구현해두면 에이전트가 이를 준수하게 되죠. 이건 에이전트를 실제 비즈니스 맥락에 근거시키는 훌륭한 방법입니다.
예를 들어, 대출과 관련된 모든 문서의 검증 플래그가 “true”로 설정되지 않으면 대출 상태를 “보류(pending)”로 유지해야 한다는 비즈니스 정책이 있다고 해보죠. 에이전트는 이 정책을 바탕으로 어떤 문서가 필요한지 파악하고 지식 베이스에 쿼리를 날립니다.
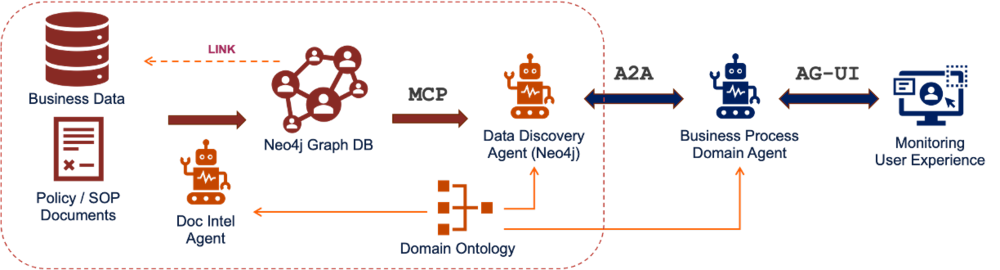
저자가 제시한 아키텍처를 보면, 문서 인텔리전스(DocIntel) 에이전트가 구조적/비구조적 데이터를 처리해 비즈니스 도메인 온톨로지에 기반한 Neo4j 데이터베이스를 채웁니다. Neo4j의 데이터 발견 에이전트가 올바른 데이터를 찾아 쿼리하고, 이를 비즈니스 프로세스 실행을 담당하는 다른 에이전트들에게 전달하죠. 에이전트 간 통신은 A2A(Agent to Agent) 프로토콜로 이뤄집니다.
이 방식의 강력한 점은 환각을 방지할 수 있다는 겁니다. 만약 에이전트가 존재하지 않는 “고객”을 만들어낸다면, 그 고객과 연결된 데이터가 데이터 발견 과정에서 검증되지 않기 때문에 이상 징후를 쉽게 감지하고 제거할 수 있어요. 개별 엔티티가 아닌 전체 시스템에 대한 규칙을 정의함으로써 환각을 통제하는 거죠.
오버헤드와 안정성 사이의 트레이드오프
물론 이런 참조 아키텍처는 데이터 발견과 그래프 데이터베이스에서 약간의 오버헤드를 추가합니다. 하지만 대규모 엔터프라이즈 입장에서는, 올바른 가드레일을 제공하고 복잡한 비즈니스 프로세스를 오케스트레이션할 방향성을 에이전트에게 준다는 점에서 충분한 가치가 있습니다.
새로운 자산, 관계, 정책을 추가하면 에이전트가 자동으로 준수하도록 확장할 수 있고, 비즈니스의 역동적인 특성도 관리할 수 있습니다. 멋진 데모를 넘어 실제로 작동하는 AI 에이전트를 원한다면, 온톨로지는 선택이 아니라 필수일지 모릅니다.
참고자료:
- FIBO (Financial Industry Business Ontology) – EDM Council
- UMLS (Unified Medical Language System) – National Library of Medicine
- What Is an RDF Triplestore? – Ontotext
- Ontologies in Neo4j: Semantics and Knowledge Graphs – Neo4j
답글 남기기