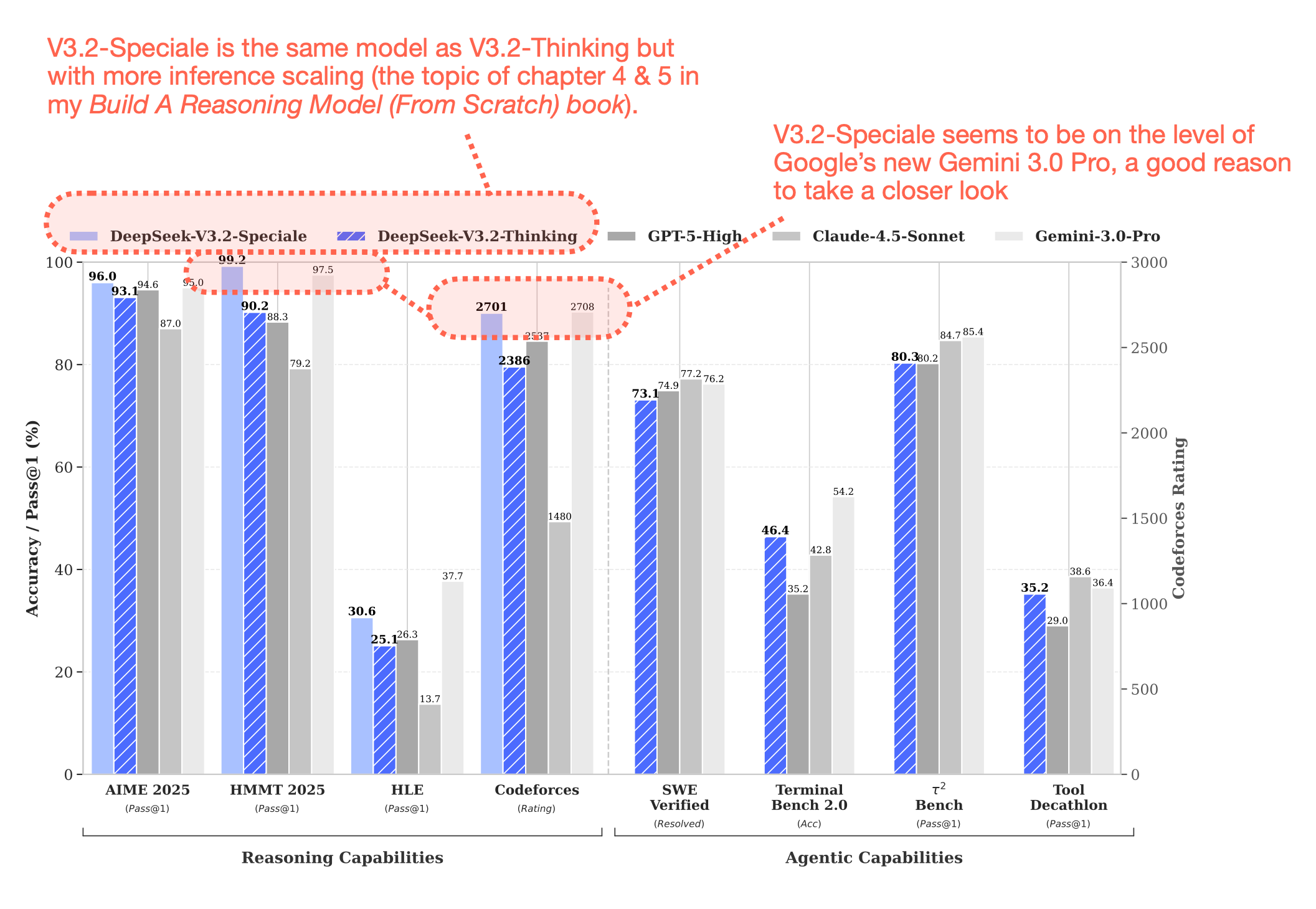
GPT-5나 Gemini 3.0 Pro 같은 최고급 모델과 어깨를 나란히 하면서도 누구나 다운로드해서 쓸 수 있다면? DeepSeek V3.2가 바로 그런 모델입니다. 더 놀라운 건 추론 비용까지 크게 낮췄다는 점이죠.

AI 연구자이자 ‘Build a Large Language Model (From Scratch)’ 저자인 Sebastian Raschka가 DeepSeek V3에서 V3.2까지의 기술적 진화를 분석한 글을 발표했습니다. 이 글은 DeepSeek가 어떻게 성능과 효율성을 동시에 끌어올렸는지, 그 핵심 기술들을 상세히 설명합니다.
출처: A Technical Tour of the DeepSeek Models from V3 to V3.2 – Sebastian Raschka
효율성 혁신: DeepSeek Sparse Attention
DeepSeek V3.2의 첫 번째 혁신은 DeepSeek Sparse Attention(DSA)입니다. 일반적인 어텐션 메커니즘은 모든 이전 토큰들을 다 살펴보는데, 문맥이 길어질수록 계산량이 제곱으로 늘어나죠. DSA는 이 문제를 완전히 다르게 접근합니다.
DSA는 ‘라이트닝 인덱서’라는 구조로 각 토큰이 과거의 어떤 토큰들에 주목해야 할지 학습합니다. 고정된 범위의 토큰만 보는 슬라이딩 윈도우 방식과 달리, DSA는 맥락상 중요한 토큰들을 선별적으로 골라냅니다. 예를 들어 긴 문서에서 현재 문단과 관련된 초반부 정보만 선택적으로 참조하는 식이죠.
결과는 극적입니다. 계산 복잡도가 O(L²)에서 O(Lk)로 줄어들어요. 여기서 k는 선택된 토큰 수(약 2,048개)인데 전체 길이 L보다 훨씬 작습니다. 긴 문맥 처리 시 추론 비용이 크게 낮아진다는 뜻이죠.
스스로 검증하고 개선하는 AI
두 번째 혁신은 DeepSeekMath V2에서 도입된 자가검증(self-verification) 메커니즘입니다. 기존 추론 모델들은 최종 답만 검증했어요. 답이 맞으면 보상을 주는 식이었죠. 문제는 운 좋게 맞춘 답과 논리적으로 올바른 풀이를 구분하지 못한다는 겁니다.
DeepSeek 팀은 이를 해결하기 위해 세 개의 LLM으로 구성된 시스템을 만들었습니다. 첫 번째 LLM은 수학 증명을 생성하고, 두 번째 LLM(검증자)은 그 증명의 논리적 타당성을 평가합니다. 세 번째 LLM(메타 검증자)은 검증자가 제대로 검증하고 있는지 확인하죠.
흥미로운 건 학습 과정입니다. 이 세 모델이 서로를 개선시키면서 발전해요. 마치 GAN(생성적 적대 신경망)처럼 생성자와 검증자가 경쟁하며 함께 성장하는 구조입니다. 최종적으로는 하나의 통합 모델이 생성과 검증을 모두 수행할 수 있게 됩니다.
이 자가검증 능력은 자가개선(self-refinement)으로 이어집니다. 모델이 자신의 답을 평가하고, 문제점을 발견하면 스스로 수정하는 거죠. DeepSeek 팀은 최대 8번의 반복 개선을 적용했고, 반복할수록 정확도가 계속 올라갔습니다.
더 안정적인 강화학습: 개선된 GRPO
세 번째 혁신은 GRPO(Group Relative Policy Optimization) 알고리즘의 개선입니다. DeepSeek R1에서 사용했던 GRPO를 V3.2에서 더욱 다듬었어요.
주요 변화는 도메인별 맞춤 설정입니다. 수학 문제에는 거의 0에 가까운 KL 페널티를 적용하고, 다른 작업에는 적절한 강도로 조정합니다. 또한 오래된 샘플 데이터가 학습을 방해하지 않도록 ‘오프-폴리시 시퀀스 마스킹’을 도입했죠.
MoE(Mixture of Experts) 구조에서는 샘플 생성 시 활성화된 전문가들을 기록해두고, 학습 시에도 같은 전문가들만 업데이트합니다. 이렇게 하면 학습이 훨씬 안정적이에요.
DeepSeek V3.2는 최근 등장한 DAPO나 Dr. GRPO처럼 급진적인 변화를 추구하지 않았습니다. 대신 원래 GRPO의 정규화 방식을 유지하면서 실용적인 개선들을 더했어요.
오픈웨이트 AI의 새로운 가능성
DeepSeek V3.2의 의미는 단순한 성능 향상을 넘어섭니다. 최고 수준의 AI를 오픈웨이트로 공개하면서 세 가지 중요한 변화를 만들어냈어요.
첫째는 접근성입니다. 연구자나 스타트업이 GPT-5 수준의 모델을 직접 다운로드해서 실험할 수 있게 됐습니다. 둘째는 비용 효율성이죠. DSA 같은 기술로 추론 비용을 크게 낮췄고, 이는 실제 서비스 운영에서 큰 차이를 만듭니다.
셋째는 투명성입니다. DeepSeek은 상세한 기술 리포트를 함께 공개합니다. 아키텍처 설계, 학습 방법, 심지어 실패한 시도들까지 공유하죠. 이런 투명성은 AI 커뮤니티 전체의 발전 속도를 높입니다.
V3.2-Speciale이라는 극단적 사고 버전도 흥미롭습니다. 추론 데이터만으로 학습했고, 답변 길이 제한을 대폭 완화했어요. 더 긴 답변을 생성하지만 그만큼 정확도가 높아집니다. 추론 비용과 성능 사이의 트레이드오프를 사용자가 선택할 수 있게 한 거죠.
한 가지 아쉬운 점은 학습 과정의 모든 세부사항이 공개되지는 않았다는 것입니다. 그래도 공개된 정보만으로도 배울 게 많고, 이는 오픈소스 AI 생태계에 큰 기여입니다.
참고자료:
답글 남기기