강화학습
GPT-5.5가 고블린에 집착한 이유, 강화학습 보상 신호의 의도치 않은 전이
GPT-5.5가 고블린·그렘린에 집착하게 된 원인을 OpenAI가 공개했습니다. Nerdy 퍼소낼리티 학습의 보상 신호가 전체 모델로 번진 강화학습 전이 사례.
Written by

AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

Claude는 최소한으로, GPT-5.4는 과도하게, AI 코딩 편집 스타일 비교 실험
AI 코딩 도구의 ‘과도한 편집’ 문제를 정량 측정한 실험. Claude Opus 4.6이 정확도·수정 최소성 모두 1위, GPT-5.4가 과도 편집 최악. 프롬프팅과 RL로 개선 가능함을 확인.
Written by

AI 모델은 모를 때 물어보지 않는다, ProactiveBench가 밝힌 구조적 한계
AI 모델이 시각 정보가 부족할 때 도움을 요청하지 않고 그냥 틀린다는 ProactiveBench 연구 소개. 22개 모델 테스트 결과와 강화학습 기반 해결 가능성을 분석합니다.
Written by

이미지 속 실수 하나가 전부를 망친다, Qwen팀의 HopChain이 고친 방법
알리바바 Qwen팀이 개발한 HopChain은 AI 비전 모델이 다단계 추론 시 오류가 누적되는 문제를 훈련 데이터 구조에서 해결합니다. 24개 벤치마크 중 20개 성능 향상.
Written by

Muse Spark, Llama 4보다 10배 효율적인 메타의 첫 프론티어 모델
메타 Superintelligence Labs의 첫 모델 Muse Spark 분석. Llama 4 대비 10배 효율, 사고 압축 메커니즘, 오픈소스 전략 전환의 의미를 다룹니다.
Written by

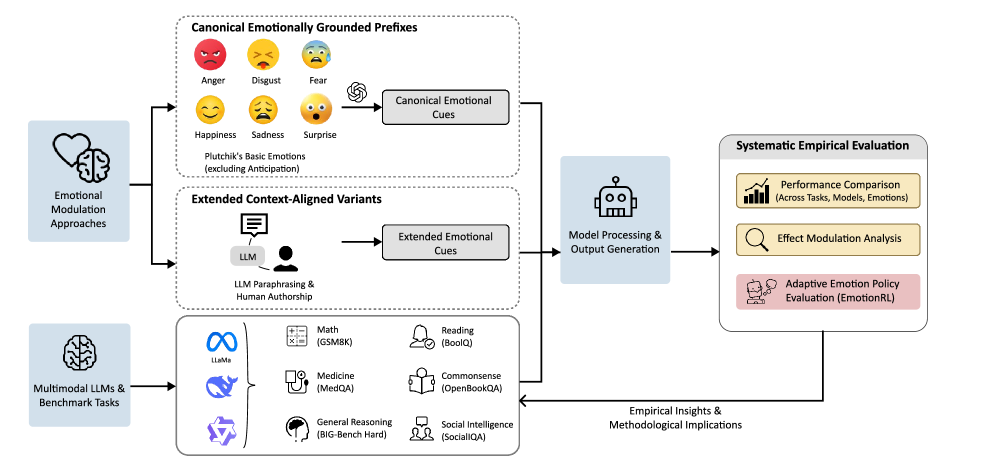
LLM에 감정을 넣으면 성능이 오를까, 6가지 감정 실험 결과
LLM에 감정 표현을 넣으면 성능이 오른다는 통념을 Harvard 연구팀이 실험으로 검증. 고정 감정은 효과 미미하지만, 적응형 감정 선택(EmotionRL)은 유효하다는 결과를 소개합니다.
Written by
Kimi·Cursor·Chroma가 에이전틱 AI를 훈련한 방식, 세 가지 공통 원칙
Kimi K2.5·Cursor Composer 2·Chroma Context-1이 강화학습으로 에이전틱 AI를 훈련한 방식 비교. 세 팀이 독립적으로 도달한 3가지 공통 원칙을 소개합니다.
Written by

MiniMax M2.7, 자기 진화 100회 반복으로 성능 30% 높인 방법
MiniMax M2.7이 100회 이상의 자율 최적화 루프로 자신의 강화학습 파이프라인을 개선해 성능 30%를 높인 방법. GLM-5 동급 성능을 1/3 비용으로 달성한 과정도 소개합니다.
Written by

버려지던 신호를 학습으로, OpenClaw-RL이 AI 훈련을 바꾸는 방법
Princeton 연구팀의 OpenClaw-RL은 AI 에이전트가 대화·터미널·GUI 상호작용에서 발생하는 신호를 실시간 학습 데이터로 전환합니다. 8 스텝 만에 개인화 점수 4배 향상.
Written by
