LLM추론
손실 없이 KV 캐시를 4배 줄이는 방법, Speculative KV Coding
KV 캐시를 손실 없이 최대 4배 압축하는 Speculative KV Coding 연구 소개. FP8 양자화와 조합하면 원본 대비 총 8배 압축, Qwen3 실험 결과 포함.
Written by

텍스트 디제너레이션, LLM 요청 3%가 시스템 전체를 42% 느리게 만드는 원리
LLM 요청의 3%에서 발생하는 텍스트 디제너레이션이 GPU 배치 전체 처리 시간을 42% 늘리는 구조적 원인과, DPO로 발생률을 최대 87% 줄인 실험 결과를 소개합니다.
Written by

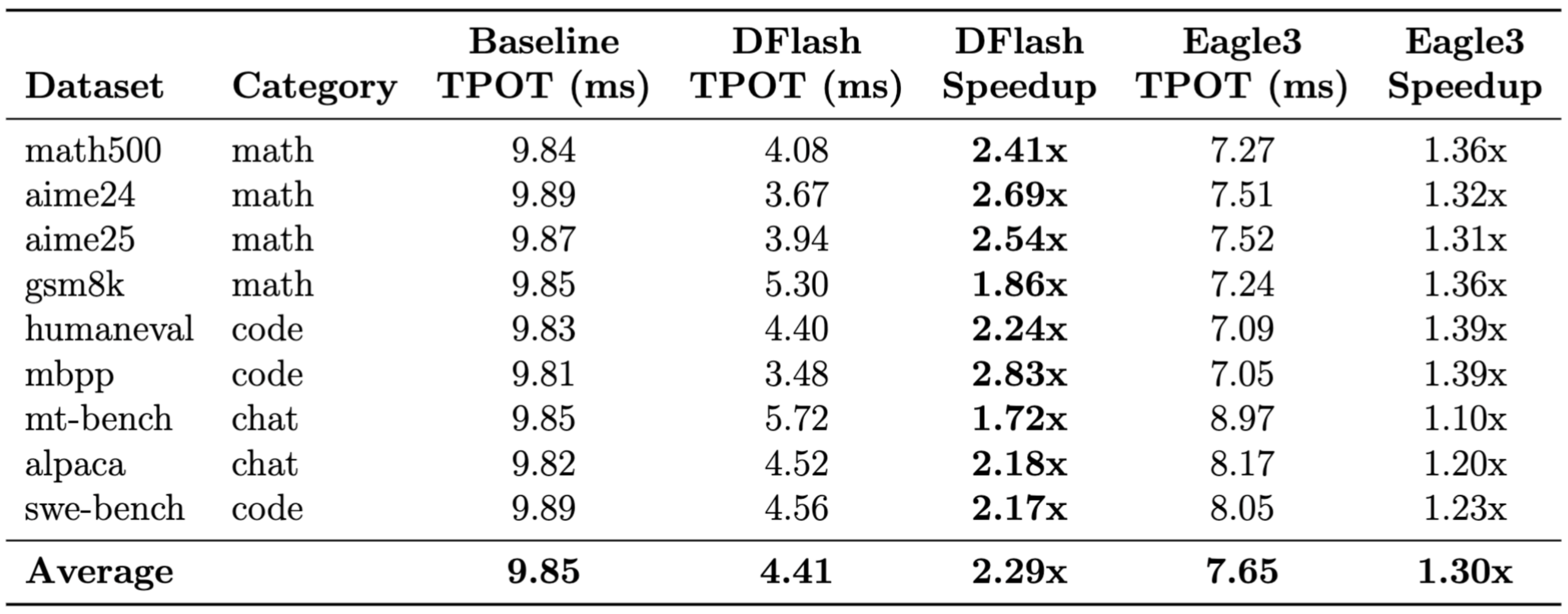
LLM 추론 속도 3배 높인 DFlash, 구글 TPU에서 디퓨전 디코딩이 작동하는 방식
UCSD 연구팀이 블록 디퓨전 방식의 DFlash를 구글 TPU에 이식해 LLM 추론 속도를 평균 3.13배 향상시킨 방법과 그 의미를 소개합니다.
Written by
Anthropic vs OpenAI 빠른 추론, 같은 듯 전혀 다른 두 가지 방법
Anthropic과 OpenAI가 동시에 발표한 fast mode, 사실 작동 원리가 완전히 다릅니다. 배칭 조정 vs 웨이퍼 크기 칩, 두 가지 방식의 차이와 트레이드오프를 분석합니다.
Written by

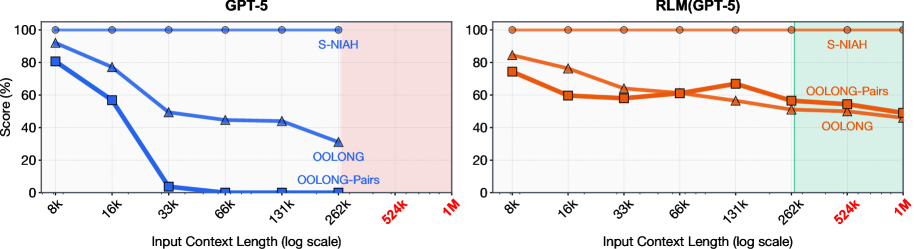
LLM이 컨텍스트 윈도우 100배를 처리한다: MIT의 Recursive Language Models
MIT CSAIL의 Recursive Language Models(RLM)은 LLM이 컨텍스트 윈도우 100배 규모의 입력을 처리하도록 합니다. 프롬프트를 환경 변수로 취급하고 재귀 호출로 1,000만 토큰 이상을 효율적으로 다루는 혁신적 추론 전략입니다.
Written by