수학 문제 하나를 푸는 데 토큰당 8.02ms가 걸리던 모델이 1.40ms로 줄었습니다. 같은 하드웨어, 같은 모델인데 속도가 5.7배 빨라진 겁니다. UCSD 연구팀이 구글 TPU에 새로운 추론 방식을 이식한 결과입니다.

구글 공식 개발자 블로그가 UCSD Z Lab 연구팀의 성과를 소개했습니다. 팀은 블록 디퓨전 기반의 투기적 디코딩 방식인 DFlash를 오픈소스 vLLM TPU 추론 프레임워크에 통합했고, TPU v5p에서 평균 3.13배, 수학·코딩 태스크에서는 최대 6배에 가까운 속도 향상을 기록했습니다.
출처: Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding – Google Developers Blog
기존 투기적 디코딩의 병목
LLM이 텍스트를 생성하는 기본 방식은 자기회귀(autoregressive)입니다. 토큰 하나를 생성할 때마다 전체 모델을 한 번씩 돌려야 하므로, 대형 모델일수록 처리 비용이 커집니다.
이 문제를 완화하기 위해 등장한 게 투기적 디코딩(speculative decoding)입니다. 구조는 이렇습니다. 먼저 작고 빠른 ‘초안 모델’이 여러 토큰을 미리 예측하고, 큰 ‘검증 모델’이 이 초안 전체를 한 번에 확인합니다. 초안이 맞으면 여러 토큰을 한 번에 수용하니 속도가 오릅니다.
문제는 초안 모델 자체에 있습니다. EAGLE-3 같은 기존 방식은 초안 모델도 자기회귀적으로 작동합니다. K개의 토큰을 예측하려면 K번의 순전파(forward pass)가 필요하죠. 검증 단계는 병렬로 빨라졌지만, 예측 단계가 다시 병목이 된 겁니다.
DFlash가 병목을 없애는 방법
DFlash는 이 병목을 구조적으로 제거합니다. 블록 디퓨전(block diffusion) 방식으로 K개의 토큰을 단 1회 순전파로 한꺼번에 생성합니다. 토큰을 하나씩 순서대로 예측하는 대신, 블록 전체를 동시에 ‘그리는’ 방식입니다.
작동 흐름은 다음과 같습니다.
- 대형 검증 모델이 중간 연산 결과(히든 스테이트)를 DFlash 초안 모델에 전달
- DFlash가 이 정보를 바탕으로 K개 토큰 블록 전체를 1회 순전파로 생성
- 검증 모델이 생성된 블록을 병렬로 확인하고 수용 여부 결정
- 수용된 토큰만큼 한 번에 전진
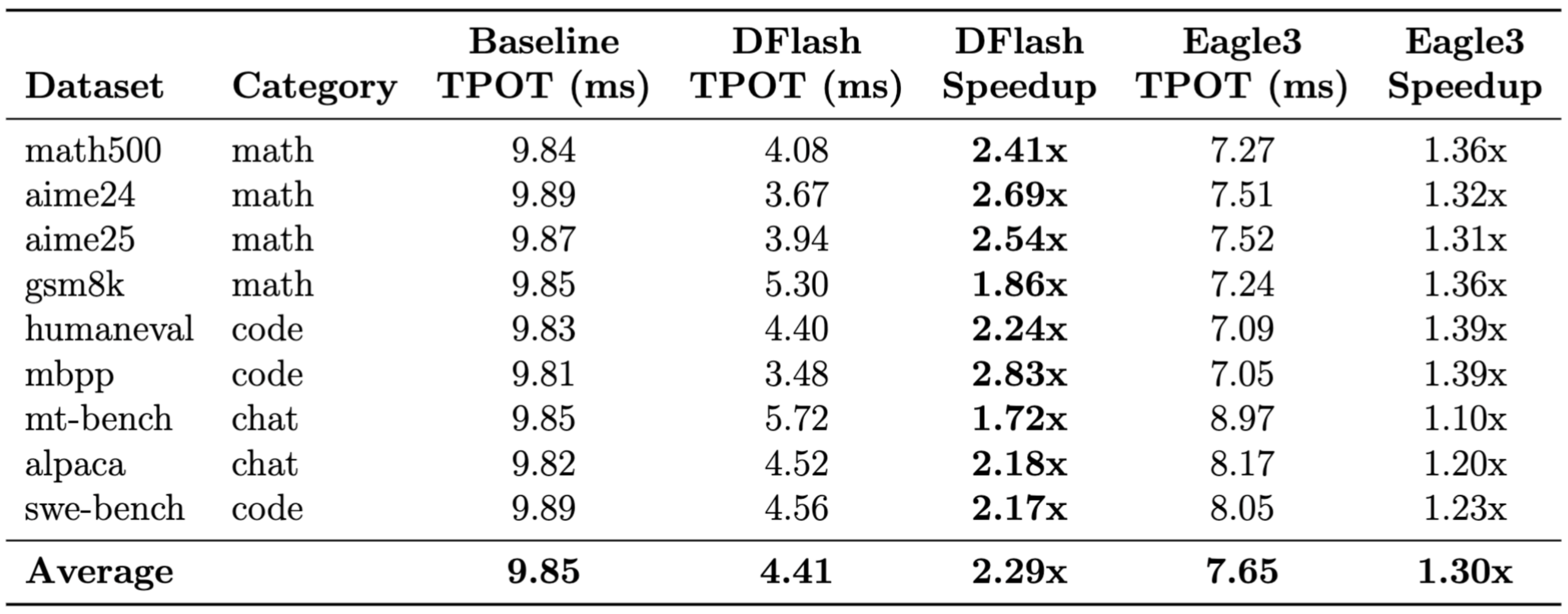
이 구조에서 초안 생성 비용은 K값과 무관하게 일정합니다. EAGLE-3가 2개 토큰을 순차적으로 예측하는 동안 DFlash는 16개 토큰을 단번에 처리합니다. 같은 검증 패스 1회에서 수용되는 토큰 수가 근본적으로 다릅니다. TPU v5p 벤치마크에서 DFlash가 2.29배 속도 향상을 기록한 반면, EAGLE-3는 1.30배에 그친 이유입니다.
K-Flat 발견이 바꾼 연구 방향
연구팀은 TPU에서 구현하는 과정에서 흥미로운 하드웨어 특성을 발견했습니다. TPU v5p에서 토큰 16개를 검증하는 비용과 1024개를 검증하는 비용이 사실상 같다는 것입니다. 이른바 ‘K-Flat’ 현상입니다.
이유는 고성능 가속기의 연산 구조에 있습니다. 이런 하드웨어에서는 연산 시간의 대부분이 모델 가중치를 메모리에서 불러오는 데 쓰입니다. 토큰을 몇 개 더 확인하는 추가 연산은 이 시간에 비하면 거의 공짜입니다.
이 발견은 연구 방향을 바꿉니다. 블록 크기를 키우는 것은 사실상 비용이 없으니, 진짜 병목은 ‘얼마나 많이 예측하느냐’가 아니라 ‘얼마나 정확하게 예측하느냐’입니다. 연구팀의 분석에 따르면 블록 크기(K)를 늘리는 것보다 토큰 수용 확률(정확도)을 높이는 게 2~3배 더 효과적입니다. 더 넓은 추론 창이 아니라 더 똑똑한 초안 모델이 다음 과제인 셈입니다.
어떤 태스크에서 효과가 큰가
속도 향상의 크기는 태스크 성격에 따라 크게 달라집니다. 수학과 코딩처럼 논리 구조가 명확한 태스크일수록 토큰 시퀀스의 예측 가능성이 높습니다. DFlash가 생성한 블록에서 수용되는 토큰 수가 많아지고, 그 결과 더 큰 속도 이득으로 이어집니다. 반면 일상 대화처럼 다양한 표현이 가능한 태스크는 예측 정확도가 빨리 떨어져 개선 폭이 상대적으로 작습니다.
이번 구현은 vLLM tpu-inference 오픈소스 저장소에 PR로 통합되었으며, 연구팀은 PyTorch 서빙 경로 지원도 준비 중입니다.
참고자료:
- DFlash 논문 – arXiv
- EAGLE-3 논문 – arXiv
답글 남기기