KV캐시
손실 없이 KV 캐시를 4배 줄이는 방법, Speculative KV Coding
KV 캐시를 손실 없이 최대 4배 압축하는 Speculative KV Coding 연구 소개. FP8 양자화와 조합하면 원본 대비 총 8배 압축, Qwen3 실험 결과 포함.
Written by

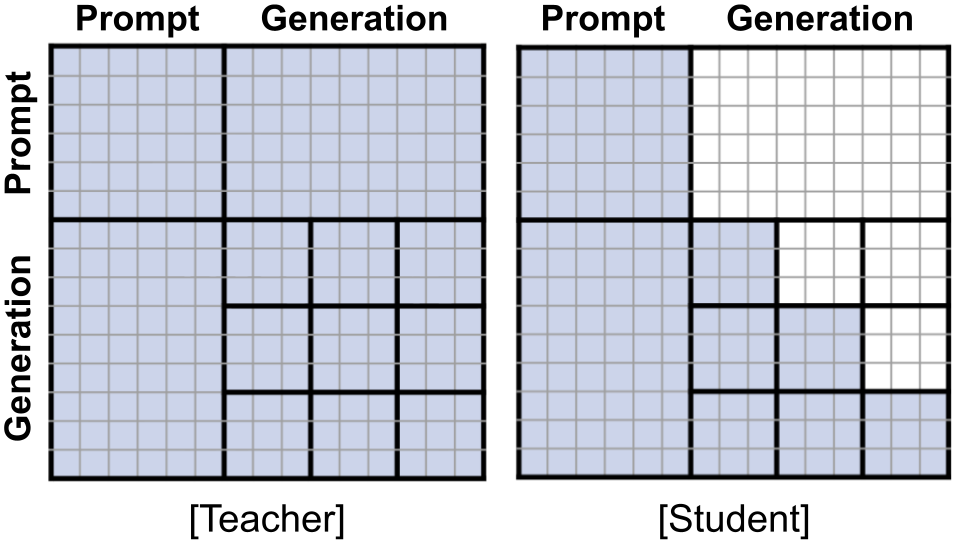
Gemma 4부터 DeepSeek V4까지, 최신 LLM 아키텍처가 풀려는 하나의 문제
Gemma 4, Laguna XS.2, DeepSeek V4 등 최신 오픈웨이트 LLM들이 공통적으로 풀려는 문제, KV 캐시와 어텐션 비용 절감의 설계 철학을 정리했습니다.
Written by

Gemma 4가 증명한 것, AI 모델은 이제 하나의 설계로 모든 곳을 커버할 수 없다
Google Gemma 4가 엣지와 서버를 아예 다른 아키텍처로 설계한 이유. 하드웨어 제약이 AI 모델 설계를 어떻게 바꾸고 있는지 분석합니다.
Written by
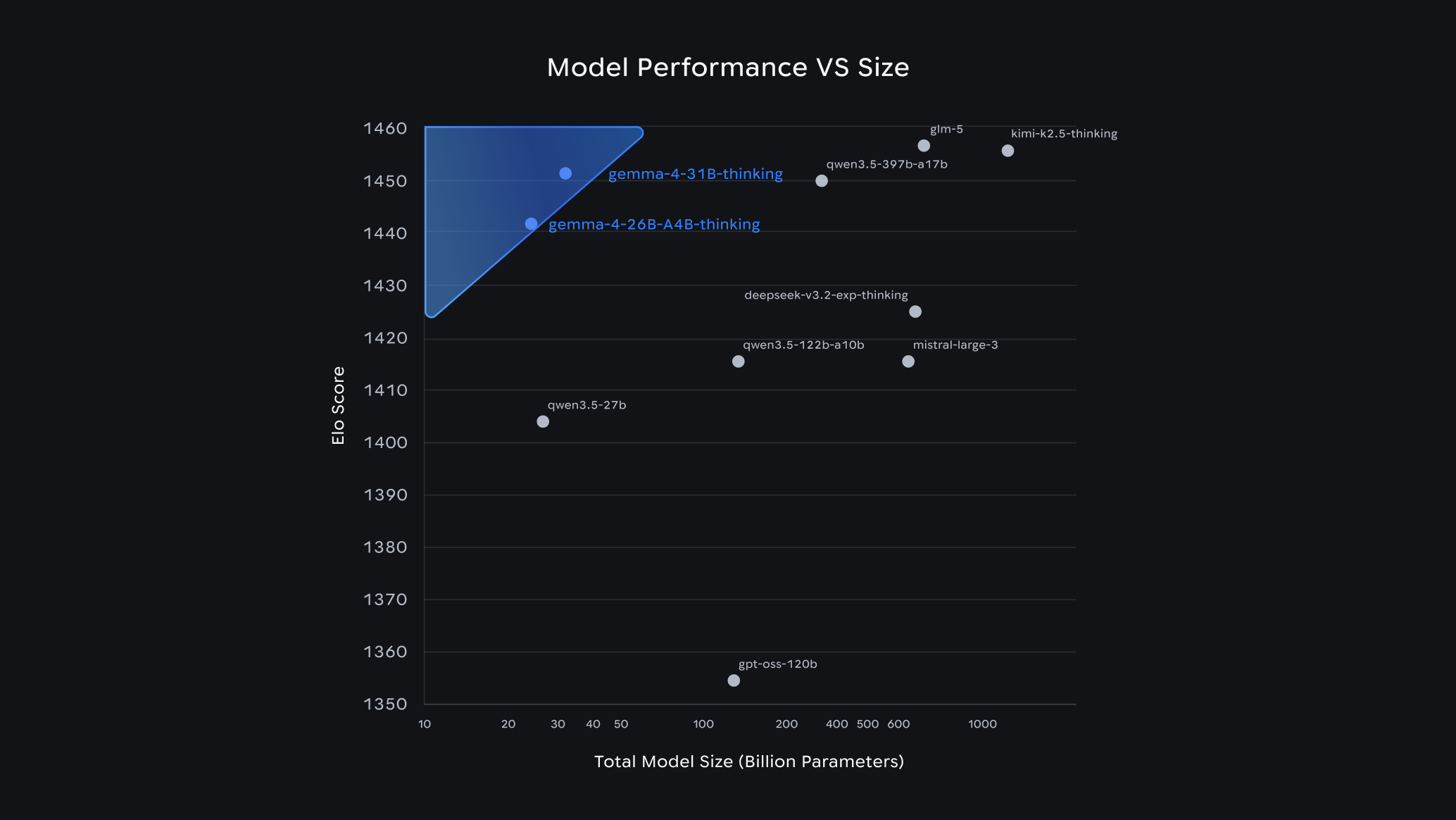
TurboQuant에 “Pied Piper”라는 별명이 붙은 이유, 그리고 그 비교가 과장인 이유
구글 TurboQuant 발표에 업계가 ‘Pied Piper’, ‘DeepSeek 모멘트’라 반응한 이유와 그 비교가 과장인 이유를 분석합니다.
Written by
AI 메모리 병목을 3비트로 해결, 구글 TurboQuant 8배 속도 달성한 방법
구글 리서치가 발표한 TurboQuant는 LLM의 KV 캐시를 3.5비트로 압축하면서 정확도 손실 없이 최대 8배 빠른 처리 속도를 달성한 벡터 양자화 알고리즘입니다.
Written by

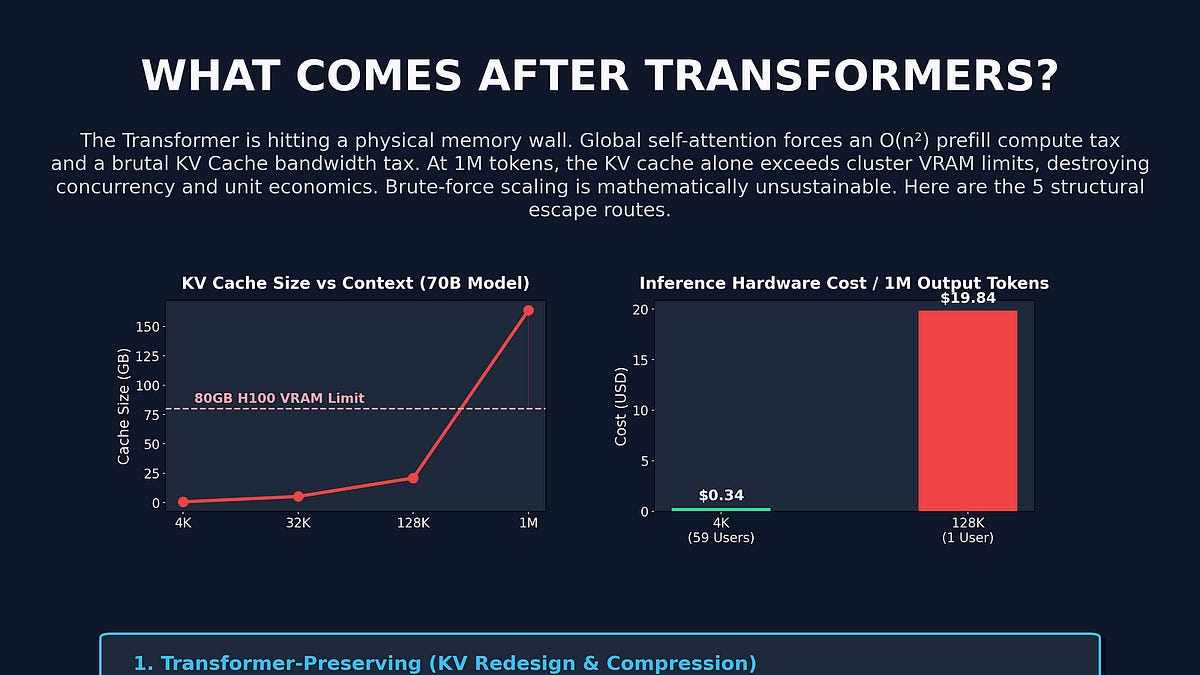
긴 컨텍스트 LLM의 숨겨진 함정, H100 동시 사용자 59명이 1명이 되는 이유
128K 컨텍스트 하나로 H100 동시 사용자가 59명에서 1명이 되는 이유. KV 캐시 압축·Mamba·하이브리드 등 5가지 탈출 전략의 트레이드오프를 비용 수치와 함께 분석합니다.
Written by
Diffusion LLM 추론 속도 14배 높인 CDLM, 두 가지 병목을 동시에 푼 방법
Together.ai가 공개한 CDLM은 Diffusion Language Model의 추론 속도를 최대 14배 높이는 포스트 트레이닝 기법입니다. KV 캐시 문제와 과도한 정제 스텝, 두 가지 병목을 동시에 해결합니다.
Written by