병렬로 토큰을 생성할 수 있는데 왜 느릴까요? Diffusion Language Model의 아이러니한 딜레마를 Together.ai가 풀었습니다.

Together.ai가 Diffusion Language Model(DLM)의 추론 속도를 최대 14배까지 높이는 CDLM(Consistency Diffusion Language Model) 기법을 공개했습니다. 포스트 트레이닝만으로 적용 가능한 가속 방법으로, 품질 저하 없이 정제 스텝을 최대 7.7배 줄이는 데 성공했습니다.
출처: Consistency diffusion language models: Up to 14x faster inference without sacrificing quality – Together.ai
DLM이 빠르다고 했는데, 왜 실제로는 느릴까
GPT 같은 AR(Autoregressive) 모델은 토큰을 하나씩 순서대로 생성합니다. DLM은 다릅니다. 처음엔 모든 토큰이 마스킹된 빈칸 상태로 시작해서, 여러 번의 정제 과정을 거치며 점차 확정된 텍스트로 수렴합니다. 이론적으로는 여러 토큰을 병렬로 처리할 수 있어 AR보다 빠를 것 같지만, 실제 운용에서는 두 가지 구조적 병목이 발목을 잡습니다.
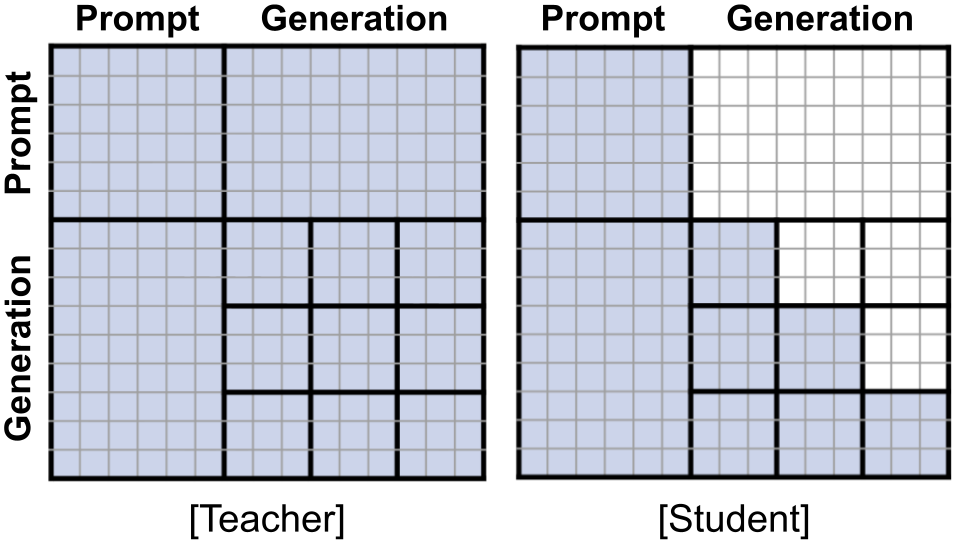
첫 번째는 KV 캐시 비호환성입니다. 일반적인 LLM 가속에서 핵심적인 역할을 하는 KV 캐시는 이전에 계산한 어텐션 결과를 재사용하는 방식입니다. 그런데 DLM이 사용하는 양방향(bidirectional) 어텐션은 매 정제 스텝마다 전체 시퀀스를 다시 계산해야 해서 KV 캐시를 쓸 수 없습니다. 두 번째는 스텝 수 문제입니다. 품질을 유지하려면 생성 길이만큼 많은 정제 스텝이 필요한데, 이를 단순히 줄이면 품질이 급격히 떨어집니다.
CDLM의 해결 방식: 블록 단위 분할 + 일관성 학습
CDLM은 이 두 문제를 하나의 포스트 트레이닝 레시피로 동시에 해결합니다.
핵심 아이디어는 생성 시퀀스를 고정 크기 블록으로 나누고, 블록 단위 인과 마스크(block-wise causal mask) 를 도입하는 것입니다. 각 블록 내부에서는 양방향 어텐션으로 토큰을 자유롭게 정제하되, 이전 블록들은 확정된 것으로 간주해 KV 캐시로 재사용합니다. AR 모델의 효율성과 DLM의 병렬성을 절충한 구조입니다.
학습은 세 가지 목표를 동시에 최적화합니다. 먼저 증류 손실(distillation loss) 로 양방향 어텐션을 쓰는 교사 모델의 예측 분포를 블록 인과 학생 모델에 옮겨 담습니다. 다음으로 일관성 손실(consistency loss) 은 같은 블록 내 서로 다른 정제 시점의 예측이 서로 일관되도록 강제합니다. 이것이 스텝을 줄여도 품질이 유지되는 핵심 이유입니다. 마지막으로 보조 마스크 복원 손실 로 수학 추론 등 일반 능력을 보존합니다.
결과: 스텝 7.7배 감소, 지연 시간 14배 개선
Dream-7B-Instruct 모델 기준으로 CDLM은 정제 스텝을 4.1배~7.7배 줄이면서도 대부분의 벤치마크에서 정확도를 거의 유지했습니다. 이 스텝 감소는 실제 지연 시간으로 이어져 GSM8K(수학)에서 11.2배, MBPP(코딩)에서 14.5배의 속도 향상을 기록했습니다.
흥미로운 점은 단순히 스텝만 줄이면 안 된다는 것입니다. 동일한 스텝 수로 기존 DLM을 그냥 잘라내면 정확도가 급격히 떨어지는 반면, CDLM은 학습을 통해 적은 스텝에서도 안정적인 다중 토큰 확정이 가능해집니다. 속도 향상이 트레이닝 없이는 공짜로 얻어지지 않는다는 걸 보여줍니다.
AR, DLM, CDLM — 어디에 위치하는가
하드웨어 관점에서 세 방식은 서로 다른 연산 특성을 갖습니다. AR 모델은 소규모 배치에서 메모리 대역폭에 묶이고, 기존 DLM은 전체 시퀀스를 매 스텝 재계산하느라 연산이 포화 상태에 빠집니다. CDLM은 그 사이 균형점을 차지합니다. 블록 내 병렬 처리로 메모리 접근을 효율화하면서, 전체 재계산의 부담은 피합니다.
Together.ai는 CDLM이 어떤 블록 디퓨전 모델에도 포스트 트레이닝으로 적용 가능한 범용 레시피임을 강조합니다. 더 강력한 DLM 백본이 나올수록 CDLM의 이점도 함께 커질 것으로 기대하고 있습니다. 수학 및 코딩 태스크 외 다양한 벤치마크 결과와 시스템 수준의 상세 분석은 원문에서 확인할 수 있습니다.
참고자료:
답글 남기기