모델 가중치도, 코드도 바뀐 것이 없는데 몇 달이 지나자 에이전트가 이상해지기 시작합니다. 예전엔 정확히 기억하던 내용을 뭉뚱그려 말하거나, 비슷한 두 사람을 혼동하거나, 이미 취소된 사항을 여전히 유효한 것처럼 처리합니다.

텍사스 오스틴대 연구팀이 이 현상에 이름을 붙이고 체계적으로 측정했습니다. 논문 제목은 “Your Agents Are Aging Too”(당신의 에이전트도 늙고 있다). 장기 배포된 AI 에이전트의 신뢰성이 시간이 지남에 따라 어떻게, 왜 떨어지는지를 처음으로 진단 가능한 형태로 정의한 연구입니다.
출처: Your Agents Are Aging Too: Agent Lifespan Engineering for Deployed Systems – arXiv (2026.05.25)
왜 지금까지 이 문제가 보이지 않았나
AI 에이전트 평가는 지금까지 거의 전부 “첫날” 기준이었습니다. 새로 배포된 에이전트가 주어진 질문에 얼마나 잘 답하는지를 측정하죠. 그런데 실제 배포 환경에서 에이전트는 수십에서 수백 번의 세션에 걸쳐 작동합니다. 코딩 에이전트라면 몇 달 치 저장소 맥락을 누적하고, 개인 비서라면 사용자의 식단 제한, 예산, 일정, 선호도를 계속 쌓아갑니다.
여기서 핵심적인 역설이 있습니다. 모델 가중치는 고정되어 있어도 에이전트의 실질적인 상태는 계속 바뀝니다. 에이전트는 메모리 시스템(기억 저장소)을 통해 과거 대화를 압축하고, 필요할 때 꺼내 쓰고, 사실이 바뀌면 업데이트합니다. 이 과정에서 조용한 손상이 쌓입니다. 겉으로는 멀쩡하게 답하는 것처럼 보이지만, 내부적으로 정확도는 이미 낮아져 있는 상태로요.
연구팀은 이 현상을 에이전트 노화(Agent Aging)라고 정의하고, 단순히 “에이전트가 틀렸다”를 넘어 어떤 메커니즘으로 틀렸는지를 추적할 수 있는 벤치마크 AgingBench를 설계했습니다.
4가지 노화 메커니즘
연구팀은 에이전트가 시간이 지나며 신뢰성을 잃는 방식을 크게 4가지로 분류했습니다.
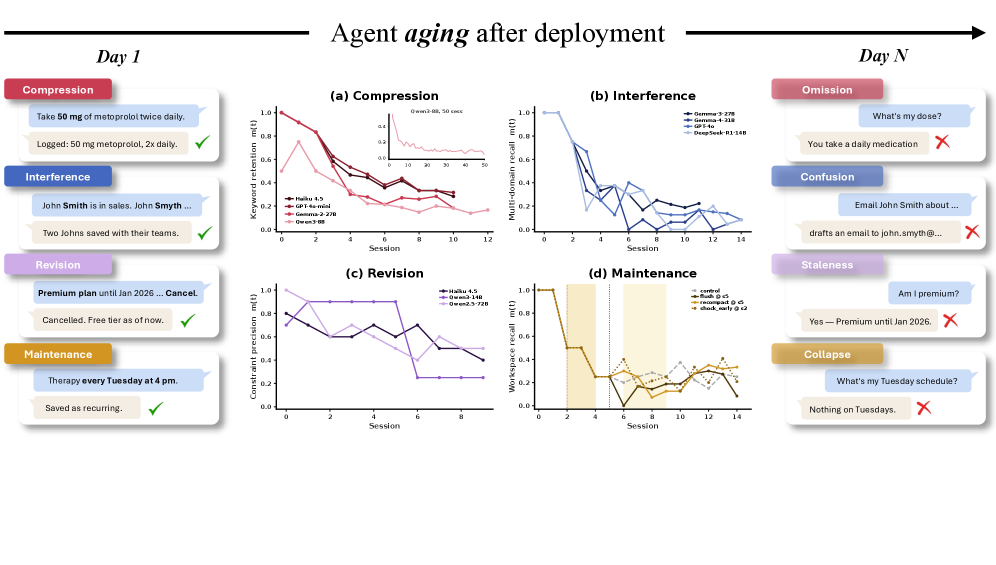
압축 노화(Compression Aging): 에이전트가 오래된 대화를 요약해 저장할 때, 나중에 필요할 수 있는 세부 정보가 지워집니다. “특정 API 버전”이나 “정확한 용량값” 같은 내용이 “일일 복용 약물”처럼 뭉뚱그려지는 식이죠. 처음엔 문제없어 보이지만, 그 세부 정보가 필요한 순간이 왔을 때 에이전트는 이미 그걸 잃어버린 상태입니다.
간섭 노화(Interference Aging): 비슷한 내용의 메모리가 쌓일수록 검색 정확도가 떨어집니다. “John Smith”와 “John Smyth”처럼 유사한 두 항목이 메모리에 누적되면, 에이전트가 엉뚱한 쪽을 꺼내올 확률이 높아집니다. 시간이 지날수록 혼동 대상이 늘어나니 자연히 악화되는 문제입니다.
개정 노화(Revision Aging): 사실이 바뀌었는데 메모리가 따라가지 못하는 경우입니다. 사용자가 프리미엄 구독을 취소했는데 에이전트는 여전히 그걸 유효한 것으로 처리하거나, 변경된 일정을 구식 정보 위에 올바르게 반영하지 못합니다. 파생 상태(derived state), 즉 여러 사실에서 계산된 결과값을 업데이트하는 것이 특히 어렵습니다.
유지보수 노화(Maintenance Aging): 이것이 가장 예측하기 어렵습니다. 메모리 압축(recompaction)이나 히스토리 플러시(history flush) 같은 일상적인 운영 작업이 끝난 뒤, 에이전트가 이전에 잘 알던 사실을 갑자기 모르는 상태가 됩니다. 운영 이벤트 자체가 회귀를 만들어내는 셈입니다.
AgingBench가 진단하는 것
AgingBench의 핵심 아이디어는 “에이전트가 틀렸다”는 결과만이 아니라, 어디서 틀렸는지를 가리키는 것입니다.
에이전트의 메모리 파이프라인은 크게 세 단계로 구성됩니다. 정보를 기록하는 쓰기(write), 필요할 때 꺼내오는 검색(retrieval), 꺼내온 정보를 실제로 쓰는 활용(utilization)입니다. AgingBench는 반사실적 탐침(counterfactual probe)이라는 방법을 써서 이 세 단계 중 어디서 실패가 시작됐는지를 좁혀갑니다. 가령 검색 단계를 정답 메모리로 교체했을 때 에이전트가 맞힌다면, 문제는 쓰기가 아닌 검색에 있다는 뜻입니다.
7개 시나리오, 14개 모델, 약 400회 실험(세션 수 8~200)을 통해 나온 결과는 세 가지 점에서 흥미롭습니다.
- 행동 테스트(behavioral test)를 통과하면서 사실 정확도는 이미 낮아진 경우가 있었습니다. 겉으로는 멀쩡해 보이는 에이전트가 실제로는 오래된 정보를 쓰고 있는 상황입니다.
- 파생 상태 추적(derived-state tracking)은 단일 모델 내에서도 급격히 무너질 수 있습니다.
- 같은 오답이라도 어떤 단계에서 실패했느냐에 따라 올바른 수리 방법이 달라집니다. “더 좋은 모델을 쓰면 된다”는 처방이 항상 맞지 않는 이유입니다.
이 연구가 의미하는 것
지금까지 AI 에이전트 평가는 배포 직전을 기준으로 설계되어 있었습니다. AgingBench는 그 이후, 즉 에이전트가 실제로 사용되는 시간 동안의 신뢰성을 측정하는 첫 번째 체계적인 시도입니다.
연구가 제안하는 개념인 에이전트 수명 공학(Agent Lifespan Engineering)은 세 가지 질문으로 요약됩니다. 에이전트는 얼마나 오래 신뢰할 수 있는가, 신뢰성은 어떤 방식으로 낮아지는가, 그리고 수리는 어디를 대상으로 해야 하는가. 이 프레임이 자리를 잡는다면, 에이전트를 단순히 배포하고 마는 것이 아니라 배포 이후에도 주기적으로 진단하고 유지하는 것이 기본 관행이 될 수 있습니다.
논문은 AgingBench의 시나리오 설계, 각 모델별 노화 곡선, ablation study 결과를 상세히 다룹니다.
답글 남기기