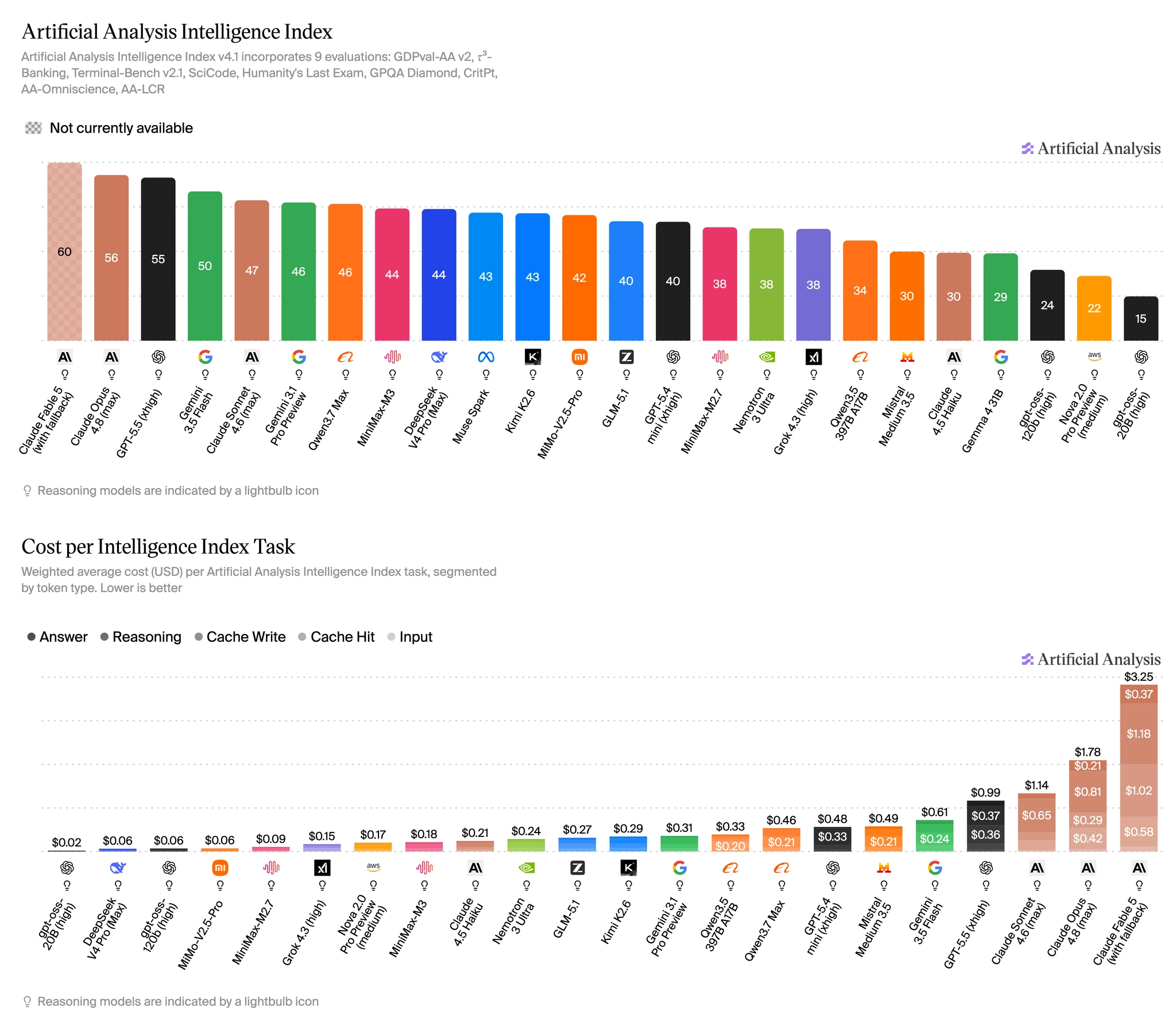
GPT-5.5와 Claude Opus 4.8은 같은 AI 지능 평가에서 1점 차이로 거의 비슷한 점수를 받았습니다. 그런데 작업 하나를 처리하는 데 드는 비용은 거의 두 배 차이가 났습니다.

AI 모델 벤치마킹 기관 Artificial Analysis가 종합 지능 지표 ‘Intelligence Index’를 v4.1로 업데이트했습니다. 평가 항목을 더 실무에 가까운 에이전트형 과제로 바꾸고, 모델별 작업당 비용·시간·토큰 사용량을 처음으로 공개한 것이 핵심입니다. 그 결과 지능 점수만으로는 드러나지 않던 모델 간 효율 격차가 숫자로 분명해졌습니다.
출처: Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads – Artificial Analysis
시험 문제에서 실무형 과제로
v4.1에서 가장 큰 변화는 평가 항목 자체입니다. 터미널에서 코드를 실행하고 문제를 해결하는 능력을 보는 Terminal-Bench Hard는 더 어려운 Terminal-Bench 2.1로, 통신 업무 처리 능력을 보던 τ²-Bench Telecom은 은행 업무를 다루는 τ³-Bench Banking으로 교체됐습니다. 점수 변별력이 떨어진 IFBench는 평가에서 빠졌습니다.
비중이 가장 큰 평가(전체의 20%)는 GDPval-AA v2입니다. 실제 경제적 가치가 있는 업무를 모델에게 맡기고, 그 결과를 사람의 평균 실력(엘로 점수 1000)과 비교하는 방식입니다. 채점은 여러 최상위 모델이 번갈아 맡고, 주고받을 수 있는 대화 턴 수도 100회에서 250회로 늘었습니다. 한 번에 답을 맞히는 능력보다, 여러 단계를 거쳐 끝까지 일을 완수하는 능력을 더 길고 엄격하게 본다는 의미입니다.
같은 지능 점수, 다른 작업당 비용
이번 개정에서는 모델이 Intelligence Index 전체를 수행하는 데 들어간 총비용·총시간·출력 토큰량을 과제 수로 나눈 ‘작업당 비용·시간·토큰’ 지표가 새로 추가됐습니다. 캐시된 입력 토큰의 비용 절감분까지 반영해, 실제 운영 비용에 더 가깝게 계산한 값입니다.
결과는 점수 차이보다 비용 차이가 훨씬 크다는 것을 보여줬습니다. 현재 사용 가능한 모델 중 가장 높은 점수(56점)를 받은 Claude Opus 4.8은 작업당 1.78달러로 가장 비쌌고, 1점 낮은 GPT-5.5(55점)는 0.99달러로 거의 절반이었습니다. 오픈소스 모델 DeepSeek V4 Pro(44점)는 작업당 0.04달러에 그쳐, 상위 유료 모델보다 20배에서 45배 저렴했습니다. 처리 시간도 모델마다 크게 갈려, Grok 4.3은 작업당 1.5분인데 Claude Sonnet 4.6은 13.5분이 걸려 9배 차이를 보였습니다.
지능 점수만으로 부족한 이유
이번 개정이 보여주는 건 단일 점수로 모델을 줄 세우는 방식의 한계입니다. 점수가 높다고 그게 곧 비용 대비 합리적인 선택이라는 뜻은 아닙니다. 반대로 점수가 최상위권에 못 미쳐도 속도에서 두드러지는 모델도 있습니다. Gemini 3.1 Pro Preview는 46점으로 1위권은 아니지만, 작업당 처리 시간이 1.6분으로 가장 빠른 축에 속합니다.
다만 Intelligence Index는 영어 텍스트 기반 평가로 한정된다는 점도 짚어둘 만합니다. 이미지나 음성을 다루는 능력, 다국어 성능은 따로 측정되기 때문에, 이 지표 하나로 모든 용도의 모델을 판단하기는 어렵습니다.
참고자료: Artificial Analysis Intelligence Benchmarking Methodology
답글 남기기