쓸 만한 코딩 모델을 쓰려면 매달 100달러씩 API에 내는 게 당연했습니다. 그런데 이제는 노트북 RAM 48GB 안에서 도는 모델이 GPT-5나 Claude Sonnet 4.5에 견줄 만큼 올라왔습니다. 같은 일을 하는데, 한쪽은 클라우드 구독이고 다른 한쪽은 내 책상 위 기계입니다.

머신러닝 저술가 Sebastian Raschka는 로컬 오픈웨이트 모델을 여러 코딩 에이전트(Qwen-Code, Codex, Claude Code)에 물려 돌려본 노트를 공개했습니다. 비슷한 시기에 Quesma의 Piotr Migdał은 Qwen 3.6 27B를 두고 “처음으로 실용성이 납득되는 로컬 모델”이라 평가했죠. 두 사람이 각자 다른 각도에서 같은 지점에 도달했습니다. 이제 노트북 한 대로 진짜 코딩 작업이 가능해졌다는 것.
출처:
- Local Open-Weight LLM Coding Harness Note – Sebastian Raschka
- Qwen 3.6 27B is the sweet spot for local development – Quesma Blog (Piotr Migdał)
모델은 어디까지 왔나
Migdał이 주목한 건 Qwen 3.6의 두 변형 중 dense 모델인 27B입니다. Mixture-of-Experts 버전(35B A3B)이 3배 빠르지만, 그는 느려도 품질이 좋은 27B를 택했습니다. “코드를 3분의 1만 만들더라도 더 나은 쪽이 낫다”는 이유로요.
체감만의 이야기는 아닙니다. Artificial Analysis 벤치마크에서 Qwen 3.6 27B는 GPT-5나 Claude Sonnet 4.5에 견줄 위치에 있습니다. 외부 집계를 봐도 SWE-bench Verified 77.2점으로 Sonnet 4.5와 같은 수준이고, 에이전트 작업 지수에서는 Sonnet 4.6과 어깨를 나란히 합니다. 얼마 전까지만 해도 한 대에 수천만 원짜리 GPU와 비싼 API가 필요했던 작업이, 지금은 M5 맥북의 공유 메모리 48GB 안에서 돌아갑니다.
물론 한계는 분명합니다. Migdał이 직접 만든 랜딩 페이지 예시를 두고 “현재 프런티어 모델 기준으로는 평범하다”고 인정했습니다. 다만 그게 핵심이 아니죠. 평범하더라도 실제로 작동하는 결과물을, 짧은 프롬프트 하나로, 내 기계에서 만들어낸다는 사실이 달라진 부분입니다.
하니스가 만드는 차이
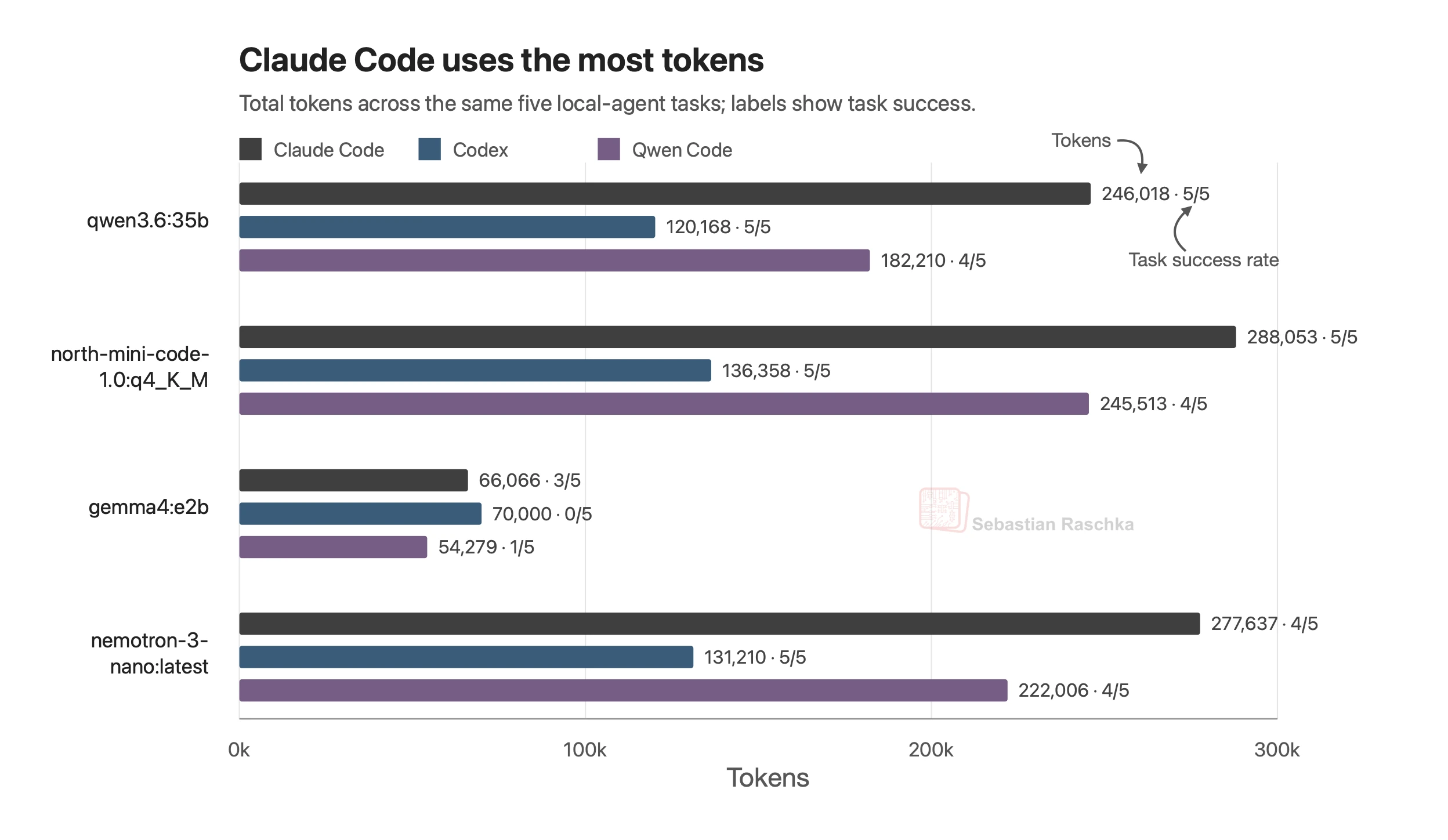
Raschka의 노트에서 더 흥미로운 대목은 모델이 아니라 하니스(harness), 즉 모델을 감싸 코딩 작업을 시키는 에이전트 도구였습니다. 같은 모델을 쓰더라도 어떤 하니스에 올리느냐에 따라 결과가 갈립니다.
그가 관찰한 차이는 토큰 효율입니다. 같은 다섯 개 작업을 처리하는 데 Claude Code가 Codex보다 약 2배 많은 토큰을 썼습니다. 로컬 환경에서 토큰은 곧 시간이자 발열입니다. 30B MoE 모델이 Mac이나 DGX Spark에서 초당 40토큰 정도를 내는데, 같은 작업에 토큰을 2배 쓴다면 체감 속도도 그만큼 벌어집니다.
여기서 실무자가 챙길 지점은 분명합니다. 로컬 코딩의 성능은 “어떤 모델이냐” 하나로 결정되지 않습니다. 모델과 하니스라는 두 변수를 함께 봐야 하고, 무료로 돌리는 로컬 환경일수록 효율 차이가 더 크게 와닿습니다.
로컬로 옮길 이유
Migdał은 글 말미에서 지금을 “자기 모델을 직접 돌리는 게 가능해진 시대의 초입”이라 표현했습니다. 그가 든 이유는 개인 실무자에게도 그대로 와닿습니다.
프런티어 모델들은 지금 막대한 보조금 위에서 돌아갑니다. 월 100달러를 내면 그보다 훨씬 큰 가치의 토큰을 쓰는 구조죠. 그는 “이 할인이 지속되는 동안 누리되”, 동시에 로컬이라는 대안을 갖춰두라고 말합니다. 로컬에 올린 모델은 내 필요에 맞게 미세조정할 수 있고, 무엇보다 누군가 갑자기 거둬갈 수 없습니다. 실제로 그는 한 프런티어 모델이 어느 날 내려간 사례를 그 근거로 들었습니다.
오프라인에서 작업하고 싶을 때, 혹은 민감한 코드나 개인 데이터를 외부 서버에 올리고 싶지 않을 때. 내 기계 안에서 끝나는 선택지가 있다는 건 그 자체로 의미가 큽니다.
지능과 지식이 분리되는 방향
Migdał은 앞으로 더 작으면서도 더 똑똑한 모델이 나올 거라 내다봤습니다. 근거가 흥미롭습니다. 지금 모델들은 추론 능력과 사실 지식을 같은 가중치 안에 함께 욱여넣습니다. 앞으로는 이 둘이 갈라져, 지식의 상당 부분을 도구 호출에 떠넘기게 되리란 전망이죠.
그렇게 되면 모델 자체는 가벼워지면서 핵심 추론력은 유지됩니다. 노트북을 넘어 스마트폰에서도 지금의 최첨단을 웃도는 모델이 돌아가는 그림입니다. Qwen 3.6 27B는 그 흐름의 디딤돌인 셈이고, 로컬에서 무엇이 가능한지를 가늠하는 기준점이 한 단계 올라섰습니다.
답글 남기기