
5개월 전만 해도 최첨단이었던 성능을 이제 3분의 1 가격에 2배 이상 빠르게 사용할 수 있다면? Anthropic의 Claude Haiku 4.5는 “좋은 모델은 비싸고 느리다”는 상식을 깨뜨리며 AI 활용의 새로운 기준을 제시합니다.
핵심 포인트:
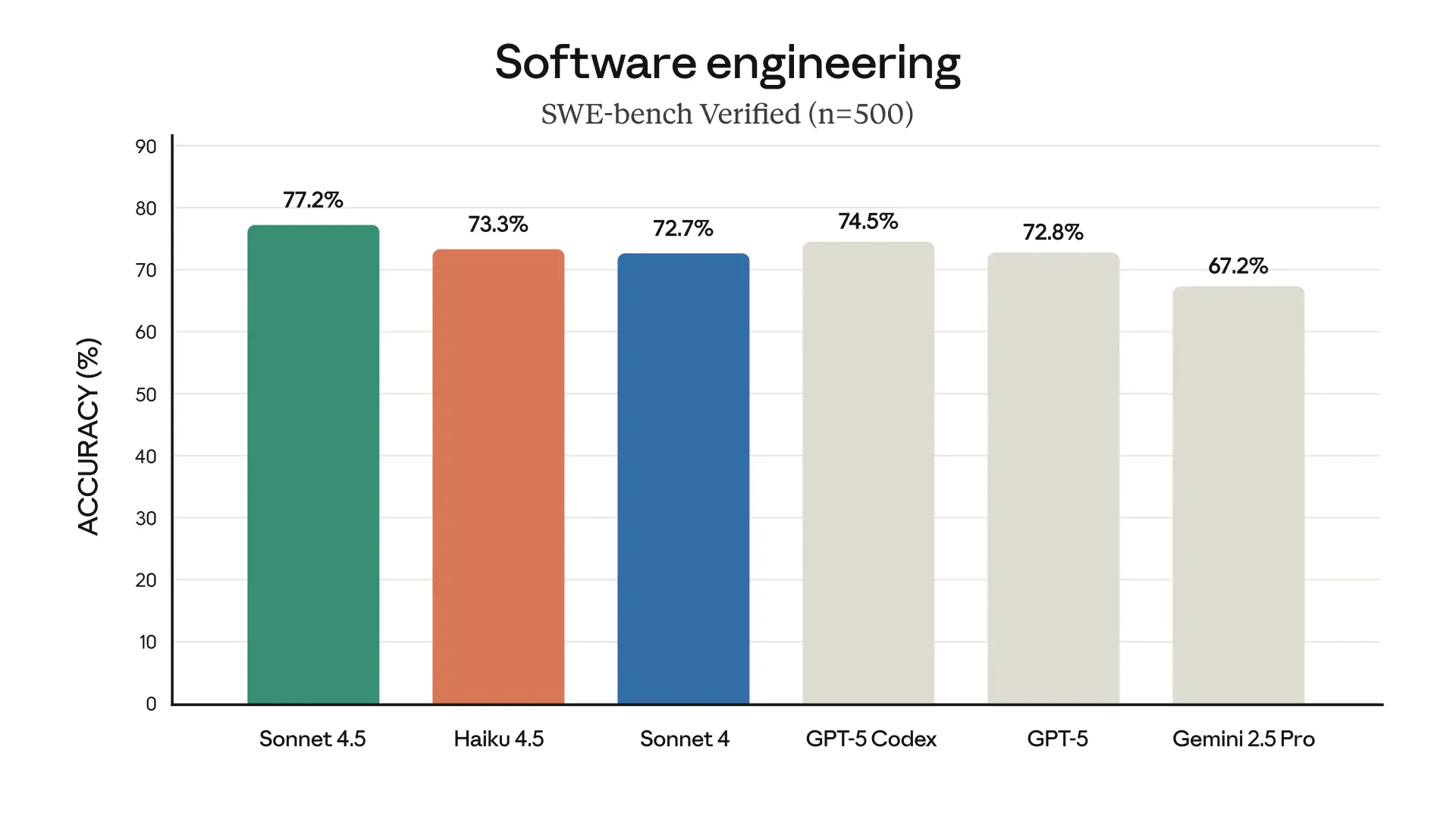
- 73.3% SWE-bench 성능, 1/3 가격: 5개월 전 최고 모델이었던 Sonnet 4와 비슷한 코딩 능력을 3분의 1 가격(100만 토큰당 입력 $1/출력 $5)에 2배 이상 빠른 속도로 제공
- 특정 작업에서는 상위 모델 능가: 컴퓨터 사용(Computer Use) 작업에서 Claude Sonnet 4를 초과하는 성능 입증. 실시간 대응이 필요한 영역에서 새로운 가능성
- 멀티 에이전트 시대의 시작: Sonnet 4.5가 복잡한 문제를 분해하고, 여러 Haiku 4.5가 동시에 하위 작업 처리하는 협업 구조로 AI 활용 방식 자체가 진화
가격표를 다시 쓰는 중
AI 모델을 선택할 때 우리는 늘 trade-off를 고민했습니다. 성능이 좋으면 비싸고 느리고, 빠르고 저렴하면 성능이 떨어지는 게 당연했죠.
그런데 Haiku 4.5는 이 공식을 바꿨습니다. 실제 코딩 작업 성능을 측정하는 SWE-bench Verified에서 73.3%를 기록했는데, 이건 불과 5개월 전까지 최첨단 모델이었던 Sonnet 4의 수준입니다. 가격은? 100만 토큰당 입력 $1, 출력 $5. Sonnet 4(100만 토큰당 입력 $3, 출력 $15)의 3분의 1이고요. 속도는 2배 이상 빠릅니다.
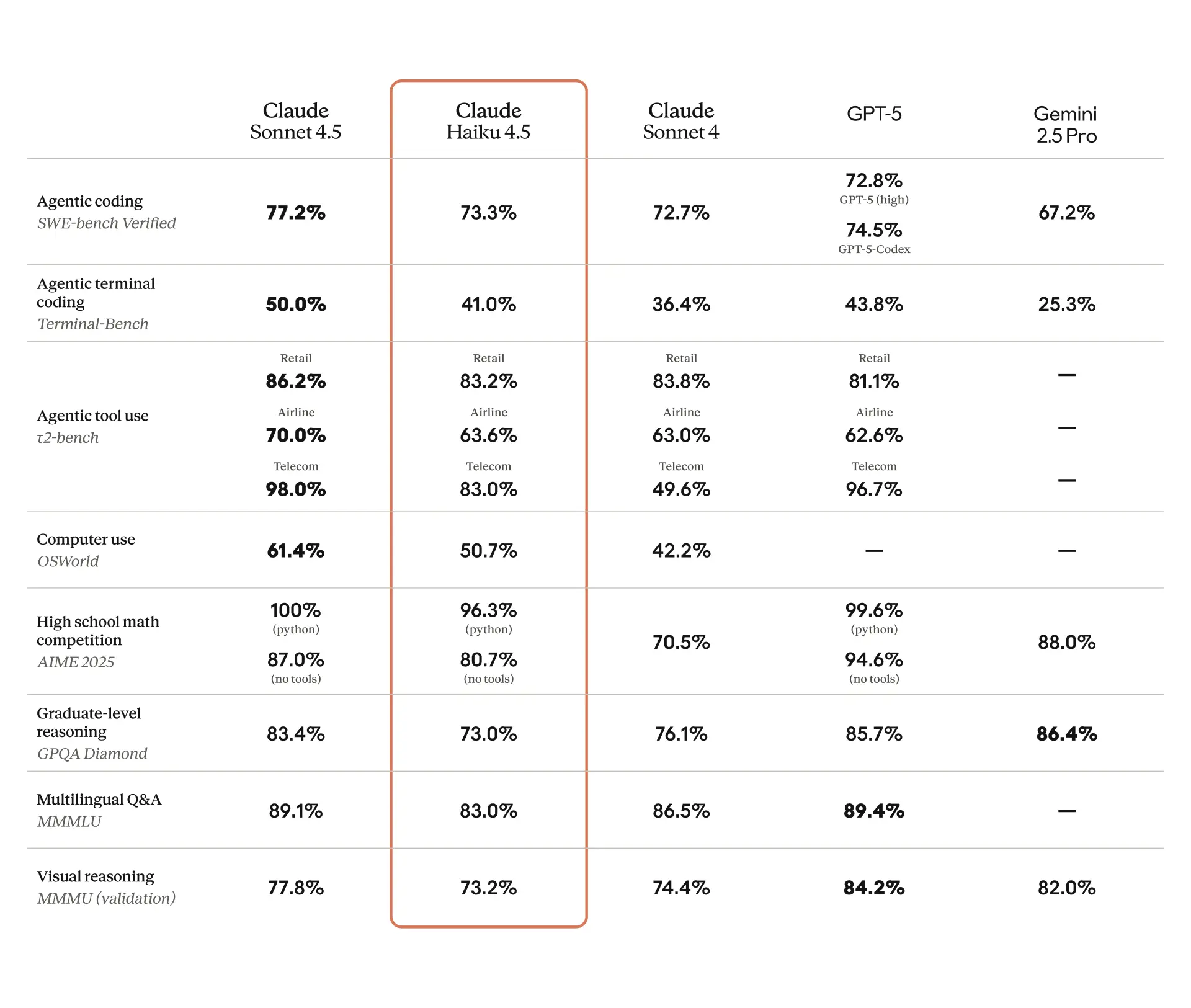
더 흥미로운 건 특정 영역에서는 상위 모델을 넘어선다는 점입니다. 가령 컴퓨터를 직접 조작하는 경우 같은. Chrome용 Claude 같은 애플리케이션이 이전보다 훨씬 빠르고 유용해진 이유입니다.
현장의 목소리
숫자만으로는 감이 안 오시나요? 실제 개발 현장에서는 이미 체감하고 있습니다.
Augment 팀은 “프론티어급 코딩 품질에 빠른 속도와 비용 효율성을 동시에 달성했다”며 “불가능하다고 생각했던 균형점”이라고 평가했습니다. 자체 에이전트 코딩 평가에서 Sonnet 4.5의 90% 성능을 훨씬 큰 모델들과 동등한 수준으로 달성했다는 게 그들의 설명입니다.
Warp는 에이전트 코딩, 특히 하위 에이전트 조율과 컴퓨터 사용 작업에서 큰 진전이라고 말합니다. “AI 지원 개발이 즉각적으로 느껴질 정도로 반응이 빠르다”는 거죠.
Cursor는 더 직설적입니다. “역사적으로 모델은 품질을 위해 속도와 비용을 희생했는데, Haiku 4.5는 그 경계를 흐리고 있다”고요. 빠른 프론티어 모델이면서 비용 효율을 유지한다는 평가입니다.
특히 Gamma의 사례가 인상적입니다. 슬라이드 텍스트 생성에서 기존 프리미엄 모델보다 지시 따르기 성능이 우수했는데, 정확도가 44%에서 65%로 올라갔습니다. “단위 경제성 관점에서 게임 체인저”라는 말이 나올 만합니다.
멀티 에이전트 오케스트레이션
Haiku 4.5의 진짜 혁신은 모델들을 함께 사용하는 새로운 방식을 가능하게 만든다는 점입니다.
Anthropic은 공식 발표에서 구체적인 활용 패턴을 제시했습니다. Sonnet 4.5가 복잡한 문제를 다단계 계획으로 분해한 뒤, 여러 개의 Haiku 4.5로 구성된 팀을 조율해 하위 작업들을 병렬로 처리하게 만드는 방식입니다.
이게 왜 중요할까요? 시니어 개발자 한 명이 전체 아키텍처를 설계하고, 여러 주니어 개발자가 동시에 각자의 모듈을 구현하는 실제 개발 팀과 비슷한 구조입니다. Haiku 4.5는 빠르고 경제적이니까 여러 인스턴스를 동시에 돌려도 부담이 없습니다. 복잡한 프로젝트를 분산 처리하면서도 비용은 통제할 수 있는 거죠.
Warp 팀이 “하위 에이전트 오케스트레이션에서 큰 진전”이라고 평가한 이유입니다. 단순히 빠른 모델이 하나 더 나온 게 아니라, AI 에이전트들이 협업하는 방식 자체가 현실적으로 가능해진 겁니다.
GitHub Copilot 팀도 “Sonnet 4와 비슷한 품질의 코드 생성을 더 빠른 속도로 제공한다”며 속도와 반응성을 중시하는 개발자들에게 훌륭한 선택지라고 밝혔습니다.
안전성도 놓치지 않았다
성능과 가격만 좋으면 되는 걸까요? Anthropic은 안전성 평가도 꼼꼼하게 진행했습니다.
자동화된 정렬 평가에서 Haiku 4.5는 Sonnet 4.5와 Opus 4.1보다 통계적으로 유의미하게 낮은 비정렬 행동 비율을 보였습니다. 이 기준으로는 Anthropic의 가장 안전한 모델이라고 합니다.
화학, 생물학, 방사능, 핵무기(CBRN) 생산 측면에서도 제한적인 위험만 제기한다는 평가를 받아 AI Safety Level 2(ASL-2) 등급을 받았습니다. Sonnet 4.5와 Opus 4.1의 ASL-3보다 덜 제한적인 기준이죠.
지금 바로 사용 가능
Haiku 4.5는 Claude Code와 Claude 앱에서 바로 쓸 수 있습니다. 개발자라면 Claude API에서 claude-haiku-4-5를 호출하면 되고, Amazon Bedrock과 Google Cloud의 Vertex AI에서도 이용 가능합니다.
6개월 전이라면 최첨단으로 분류됐을 성능이 이제는 4~5배 빠르게 돌아갑니다. 실시간 채팅, 고객 서비스, 페어 프로그래밍처럼 저지연이 필수인 작업에서 프론티어급 성능을 경제적으로 활용할 수 있게 된 겁니다.
답글 남기기