LLM
리누스 토발즈, AI 비판자에게 “리눅스 포크하거나 떠나라”
“AI는 90% 마케팅”이라던 리누스 토발즈, 이제는 리눅스가 반AI 프로젝트가 아니라고 선언. 태도 변화의 배경과 여전한 비판점을 함께 정리했습니다.
Written by

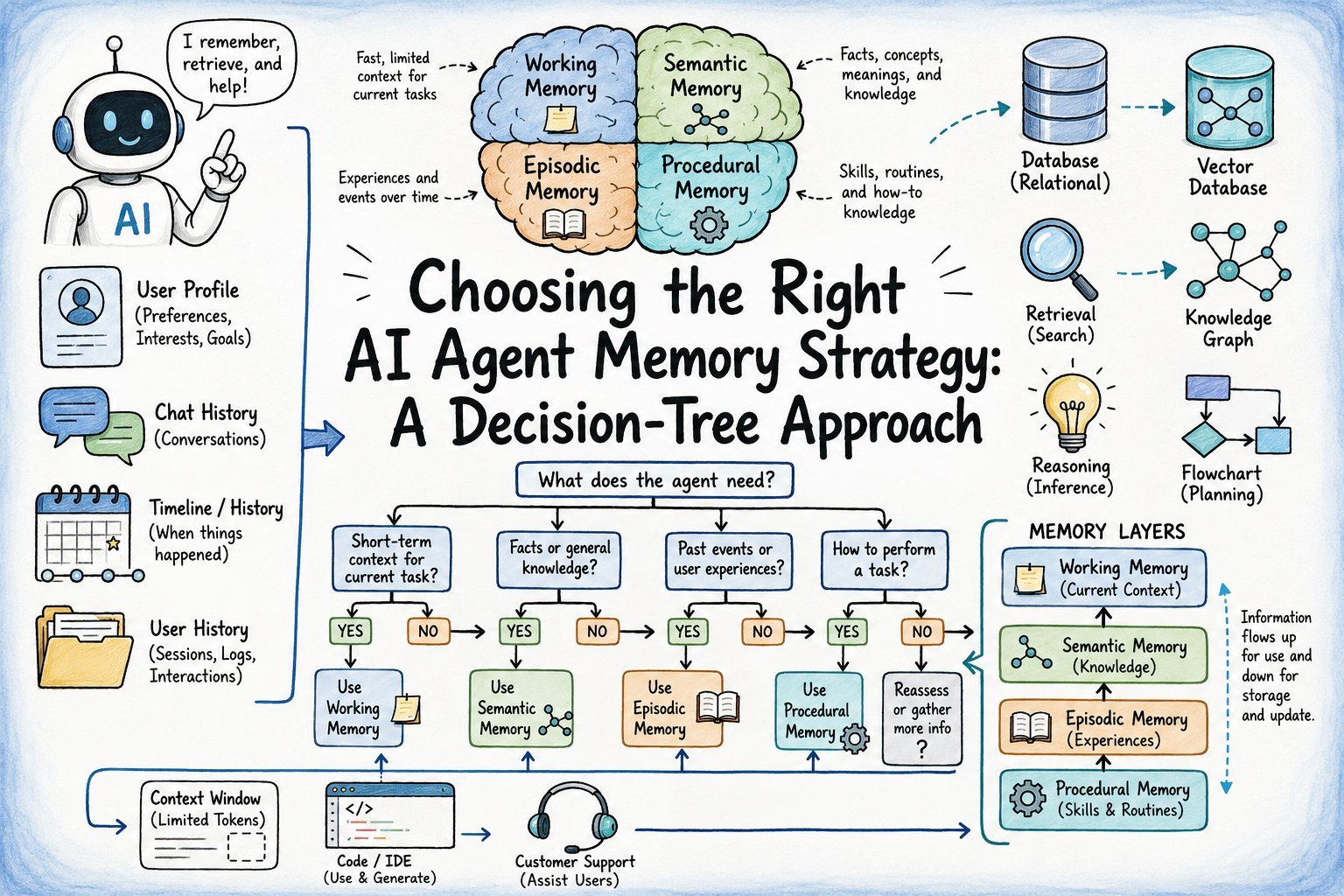
AI 에이전트가 매번 처음부터 시작하는 이유, 정보가 아니라 재사용의 문제였다
AI 에이전트가 매번 처음부터 시작하는 진짜 원인은 정보 부족이 아니라 재사용 실패. 4종류 메모리와 이를 판단하는 의사결정 트리를 다룹니다.
Written by
레딧, 매일 스팸 2300만 건을 AI로 막아낸다
AI가 스팸을 쉽게 만들지만, 레딧은 그 AI로 스팸을 막습니다. 하루 2,300만 건을 차단하는 방어 시스템을 살펴봤습니다.
Written by

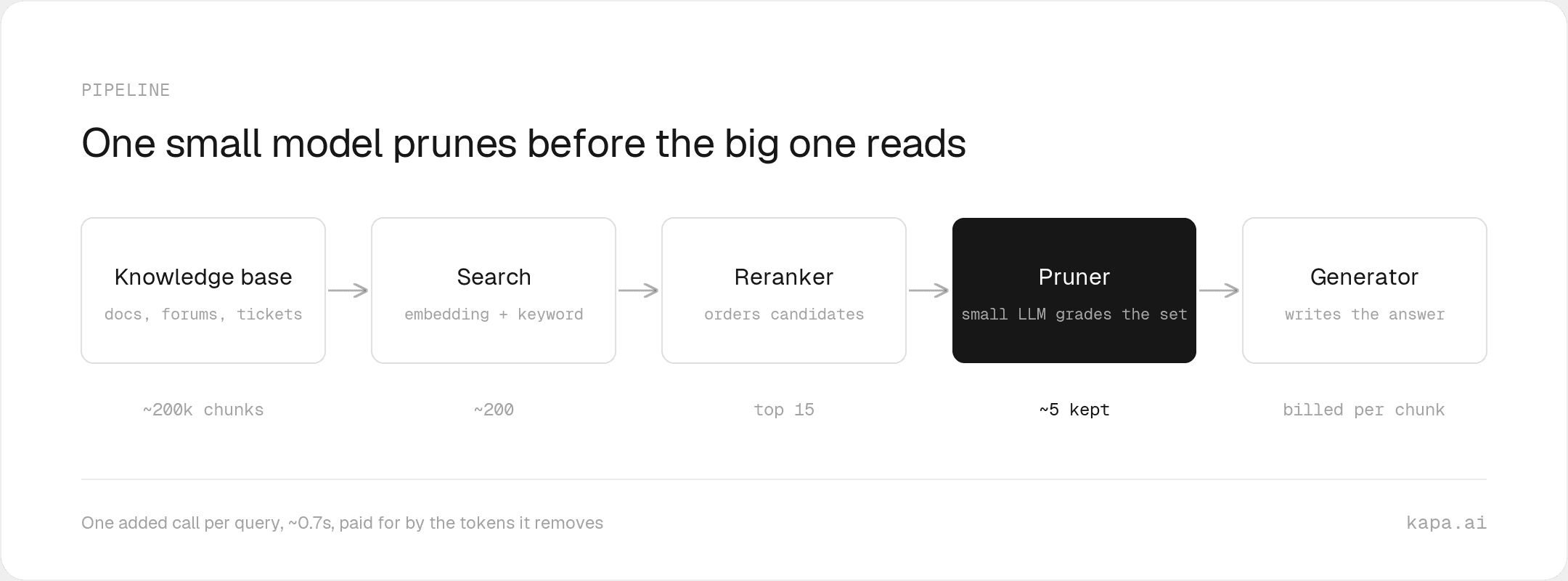
RAG 컨텍스트 68% 쳐내고 정확도는 지킨 kapa.ai의 채점 방식
kapa.ai가 LLM 채점으로 RAG 컨텍스트를 68% 줄이면서도 재현율 96%를 지킨 방법. rerank 한계와 해법을 소개합니다.
Written by
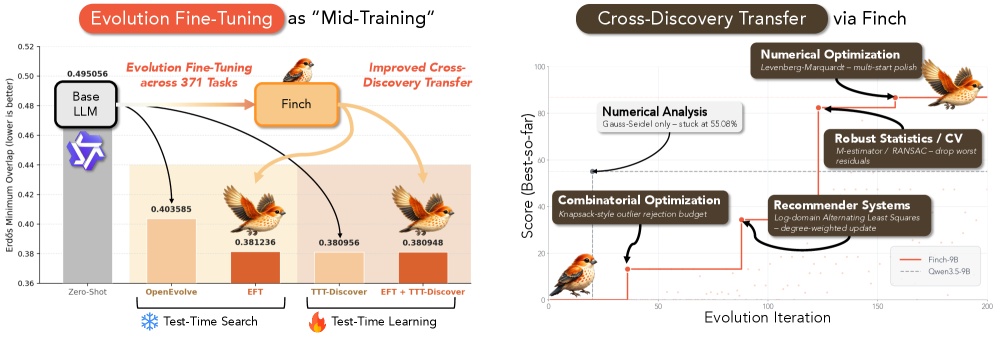
LLM에 문제해결 요령 학습시켰더니 새 과제서 10% 향상
LLM에게 정답 대신 문제 해결 요령 자체를 학습시켰더니, 한 번도 본 적 없는 새 과제에서도 평균 10% 더 나은 성능을 냈다는 다기관 공동연구 논문을 소개합니다.
Written by
AI 에이전트는 왜 매번 처음부터 시작할까, 메모리 설계의 7가지 갈래
LLM은 원래 아무것도 기억하지 못합니다. 에이전트 메모리의 7가지 유형과, 모델 안에 저장할지 바깥에 둘지를 가르는 두 갈래 설계 접근을 정리했습니다.
Written by

컨텍스트 윈도우는 200만 토큰까지 커졌는데, AI는 왜 방금 준 정보를 못 쓸까
컨텍스트 윈도우가 200만 토큰까지 커져도 AI가 중간 정보를 놓치는 U-shape 현상과, 양보다 정밀도가 중요한 이유. 개인 실무자가 바로 쓸 수 있는 5가지 컨텍스트 관리 원칙을 정리했습니다.
Written by

잘 만든 AI 프로토타입이 제품이 되지 못하는 이유, ‘프롬프트 부채’
자연어 프롬프트로 만든 AI 프로토타입이 왜 제품으로 자라지 못하는가. Drew Breunig이 짚은 ‘프롬프트 부채’ 개념과, 측정 기반 명세·프롬프트 자동 탐색이라는 대안을 소개합니다.
Written by

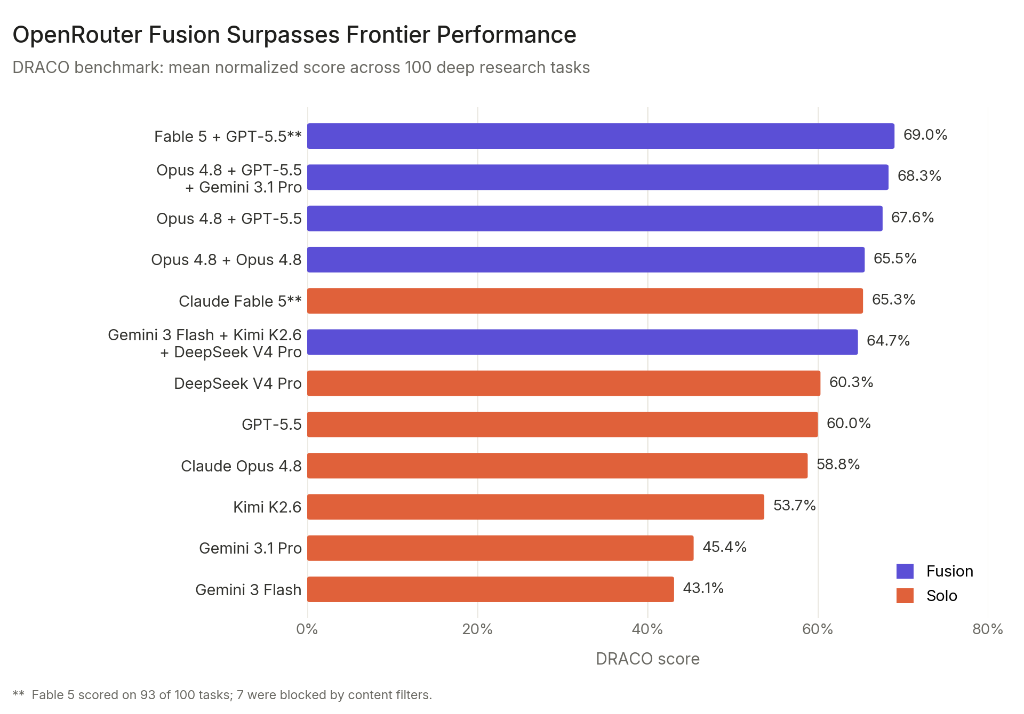
AI 모델을 한 팀으로 묶었더니, 단일 최강 모델보다 똑똑해졌다
여러 AI 모델을 묶어 판정 모델이 답을 합성하는 OpenRouter Fusion. 단일 최강 모델을 능가하고, 저가 패널이 절반 비용으로 프런티어 모델을 앞선 발견을 소개합니다.
Written by