의대 면허시험 문제를 척척 풀어내는 AI에게 “이 문제가 학생들한테 얼마나 어려울까요?”라고 물으면 어떻게 될까요? 놀랍게도 AI는 전혀 감을 잡지 못합니다. 문제는 잘 푸는데 그게 왜 어려운지는 모르는 거죠.

메릴랜드대, 카네기멜론대, 버팔로대 연구팀이 발표한 논문은 GPT-5를 포함한 20개 이상의 대규모 언어모델(LLM)이 시험 문제 난이도를 인간 관점에서 전혀 평가하지 못한다는 사실을 밝혔습니다. 연구팀은 의학(USMLE), 영어(Cambridge), 수학/논리(SAT) 등 네 가지 영역에서 실제 학생들의 시험 결과와 AI의 난이도 예측을 비교했습니다. 핵심 발견은 AI가 너무 똑똑해서 오히려 학습자의 어려움을 이해하지 못하는 “지식의 저주(curse of knowledge)” 현상입니다.
출처: Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction – Li et al., arXiv
더 큰 모델이 반드시 낫지 않다
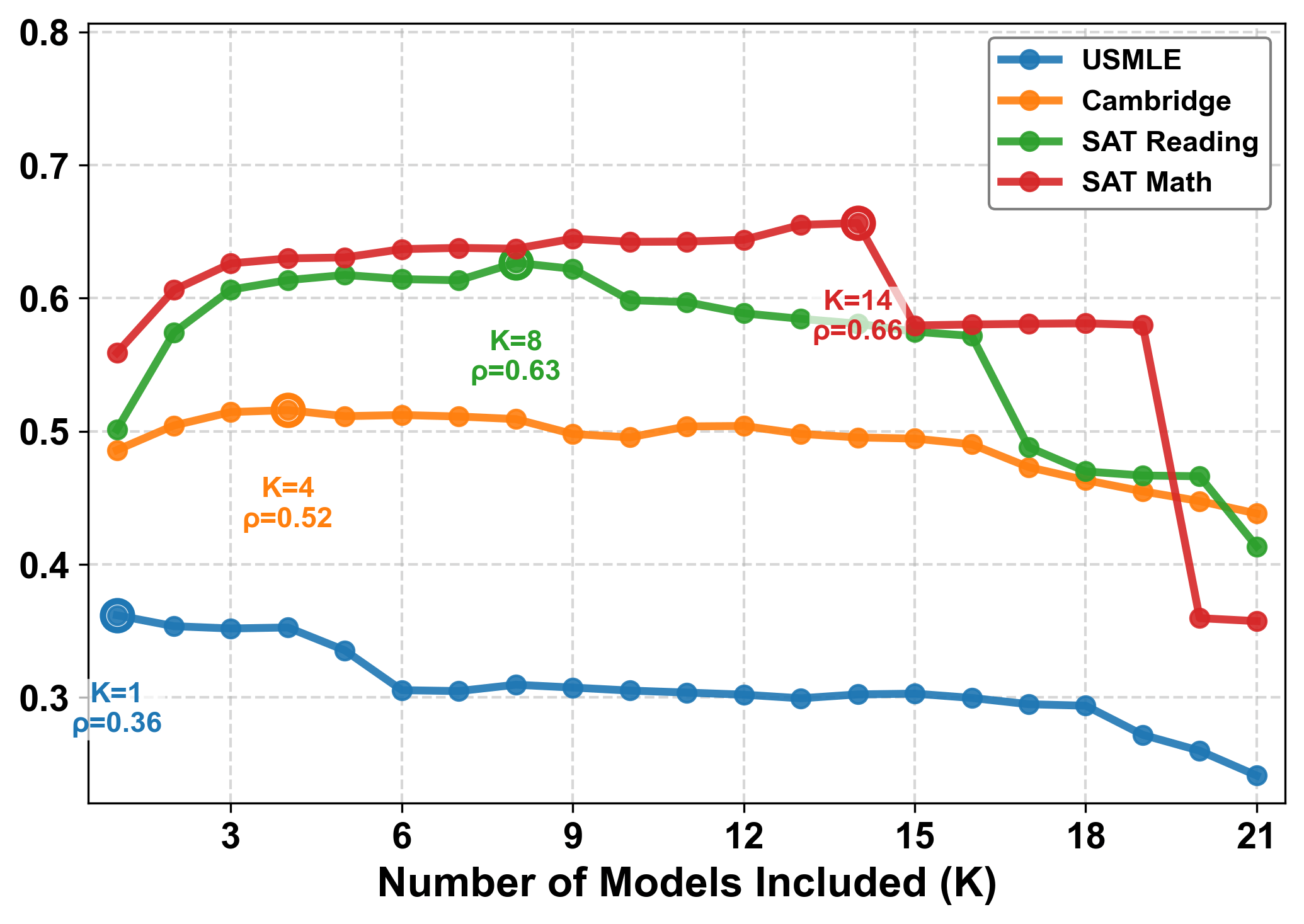
연구팀은 Spearman 상관계수로 AI와 인간의 난이도 인식 일치도를 측정했습니다. 1점이면 완벽한 일치, 0점이면 전혀 상관없음을 의미하죠. 결과는 놀라웠습니다. 평균 점수가 0.5 미만이었고, 최신 대형 모델이라고 해서 더 나은 것도 아니었습니다.
GPT-5는 0.34점을 받았는데, 구버전인 GPT-4.1이 0.44점으로 오히려 더 높았습니다. 추론에 특화된 Deepseek-R1 같은 모델도 별반 다르지 않았죠. 모델 크기를 키우고 성능을 올리는 게 난이도 평가 능력으로 이어지지 않는다는 뜻입니다.
더 심각한 건 AI들끼리는 서로 비슷한 평가를 내린다는 점입니다. 연구팀은 이를 “기계 합의(machine consensus)”라고 불렀습니다. AI들은 인간과는 다른 자기들만의 난이도 기준을 만들어내고 있었던 거죠. 특히 의대 시험(USMLE)에서는 상관계수가 0.13까지 떨어졌습니다. 지식 집약적 분야일수록 AI와 인간의 인식 차이가 커지는 패턴을 보였습니다.
역할극도 소용없다
그렇다면 AI에게 “약한 학생”, “평균 학생”, “우수한 학생” 역할을 맡겨보면 어떨까요? 연구팀은 이런 프로파일링(proficiency simulation)도 시도했지만 거의 효과가 없었습니다.
AI에게 약한 학생 역할을 하라고 시켜도 정답률은 1% 미만으로만 변했습니다. AI는 자신의 능력을 의도적으로 낮출 수 없었습니다. 문제를 보면 자동으로 정답을 찾아내는데, 일부러 틀린 답을 고르거나 실수를 재현하지 못하는 거죠. 이것이 바로 “지식의 저주”입니다. 너무 유능해서 오히려 약한 학습자를 흉내낼 수 없는 역설이죠.
연구팀이 항목반응이론(IRT)으로 AI들의 실제 정답률을 분석한 결과는 더 충격적이었습니다. 의대 시험에서 인간이 가장 어려워하는 문제들의 70.4%를 AI 90% 이상이 쉽게 풀어냈습니다. 인간에게는 최고 난이도지만 AI에게는 식은 죽 먹기인 셈이죠.
자기 자신도 모른다
AI는 자신이 어떤 문제를 틀릴지도 예측하지 못합니다. “이 문제 어려운데”라고 평가한 문제를 정작 본인은 맞히고, “이건 쉽네”라고 한 문제를 틀리는 식이죠.
연구팀은 AUROC(수신자 조작 특성 곡선 아래 면적)로 이를 측정했습니다. 0.5면 완전히 랜덤 수준이고, 1에 가까울수록 자기 실수를 잘 예측한다는 뜻입니다. 대부분의 모델이 0.5~0.6 사이에 머물렀습니다. GPT-5와 Deepseek-R1이 특정 영역에서 0.7대를 기록하긴 했지만, 전반적으로는 여전히 자기인식이 부족했습니다.
연구팀은 이를 “메타인지적 맹점(metacognitive blindness)”이라고 표현했습니다. AI는 난이도를 평가할 때 자신의 실제 성공/실패 경험을 전혀 참고하지 못합니다. 추상적으로 “어려울 것 같다”고 판단할 뿐, 그 판단이 자기 능력과는 완전히 분리돼 있는 거죠.
교육 AI의 근본적 한계
문제 난이도를 정확히 평가하는 건 교육 평가의 핵심입니다. 커리큘럼 설계, 자동 시험 출제, 적응형 학습 시스템 모두 이 능력에 달려 있죠. 지금까지는 새 문제를 만들면 수백 명의 학생들에게 실제로 풀려봐야 난이도를 알 수 있었습니다. 시간도 오래 걸리고 비용도 많이 드는 과정이죠.
LLM이 이 과정을 대체할 수 있을 거라는 기대가 있었습니다. 하지만 이번 연구는 그 희망에 찬물을 끼얹습니다. 문제를 푸는 능력과 학습자의 어려움을 이해하는 능력은 전혀 다른 차원이라는 걸 보여주니까요.
연구팀은 해결책으로 학생들의 오답 패턴 데이터를 학습시키는 방법을 제안했습니다. 단순히 정답을 학습하는 게 아니라 학생들이 어디서, 왜 틀리는지를 AI에게 가르치는 거죠. 하지만 이것도 결국 실제 학생 데이터가 필요하다는 점에서 근본적 해결책은 아닙니다.
OpenAI 전 연구원 Andrej Karpathy는 최근 교육 시스템의 근본적 개편을 주장했습니다. 학교는 숙제에 AI가 사용됐다고 가정하고, 시험은 학교에서, 지식 습득은 AI 도움을 받아 집에서 하는 “플립드 클래스룸” 모델을 제안했죠. 학생들은 AI와 함께 일하는 법도 배우고, AI 없이도 작동할 수 있는 능력도 길러야 한다는 겁니다.
이번 연구가 보여주는 건 명확합니다. AI가 아무리 똑똑해도 교사를 대체할 수는 없습니다. 지식을 전달하는 것과 학습자를 이해하는 것은 근본적으로 다른 능력이니까요.
참고자료:
답글 남기기