스마트폰에서 AI를 돌린다는 건 여전히 느리고 복잡한 일이었습니다. Google이 이 문제를 정면으로 해결한 프레임워크를 내놓았습니다.

Google이 TensorFlow Lite(TFLite)의 후속작인 LiteRT를 정식 출시했습니다. 온디바이스 AI를 위한 범용 프레임워크로, GPU는 기존보다 1.4배 빠르고, NPU에서는 CPU 대비 무려 100배까지 빠른 성능을 보여줍니다.
출처: LiteRT: The Universal Framework for On-Device AI – Google Developers Blog
TFLite를 넘어선 성능
LiteRT의 가장 눈에 띄는 변화는 성능입니다. Google의 차세대 GPU 엔진 ML Drift를 기반으로, TFLite GPU 대비 평균 1.4배 빠른 속도를 보여주죠. 더 인상적인 건 NPU(Neural Processing Unit) 지원입니다. MediaTek, Qualcomm 칩셋에서 CPU 대비 100배, GPU 대비 10배 빠른 성능을 기록했습니다.
실제 벤치마크를 보면 차이가 극명합니다. Galaxy S25 Ultra에서 Gemma 3 1B 모델을 돌렸을 때, 경쟁 프레임워크인 llama.cpp와 비교해 CPU에서 3배, GPU 디코드에서 7배, GPU 프리필에서는 19배나 빠릅니다. 배경 세그멘테이션이나 음성 인식처럼 실시간 응답이 중요한 앱에서 이 차이는 결정적입니다.
크로스플랫폼 통합의 진짜 의미
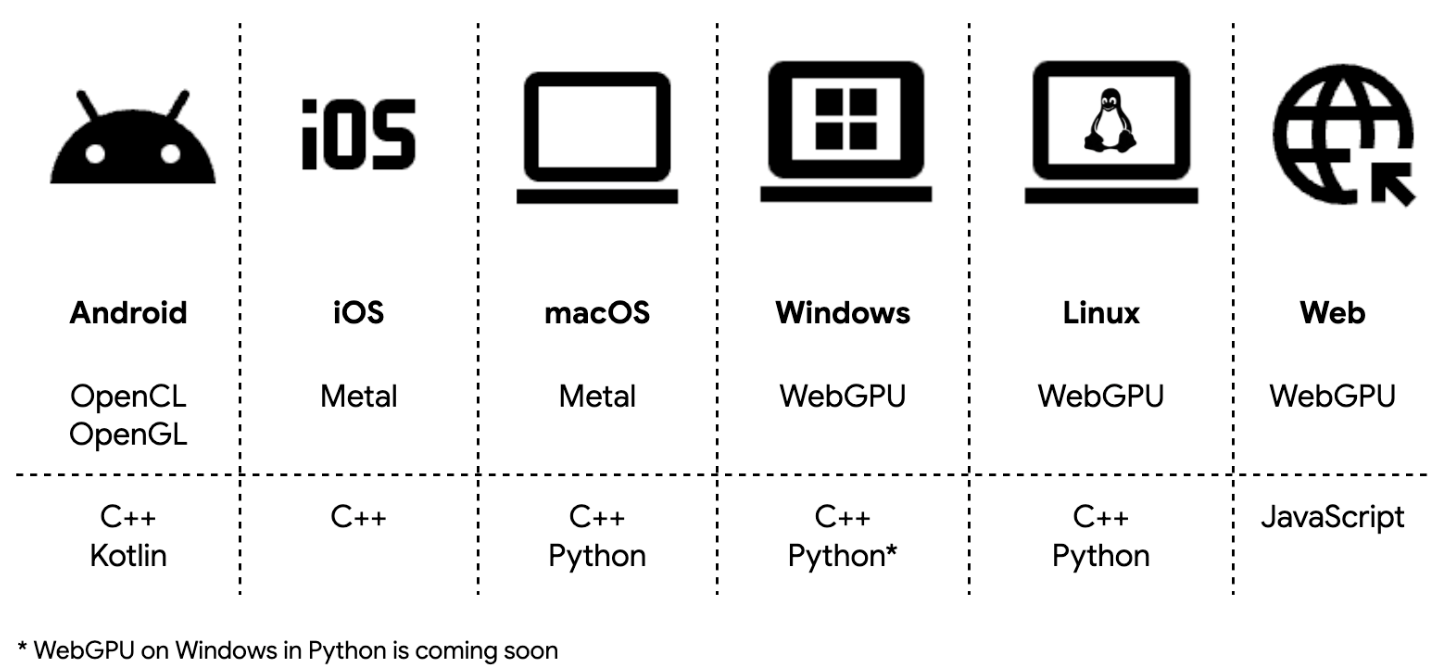
개발자 입장에서 더 중요한 건 배포의 단순함입니다. LiteRT는 Android, iOS, macOS, Windows, Linux, 웹까지 단일 워크플로우로 지원합니다. OpenCL, OpenGL, Metal, WebGPU를 모두 커버하면서도, 개발자는 플랫폼별 SDK를 직접 다룰 필요가 없습니다.
NPU 배포는 특히 간단해졌습니다. 기존에는 수백 가지 SoC 변종마다 다른 컴파일러와 런타임을 다뤄야 했는데, LiteRT는 이를 세 단계로 줄였습니다. 모델을 사전 컴파일하고(선택사항), Google Play for On-device AI로 배포하고, LiteRT 런타임으로 실행하면 끝입니다. 호환되지 않는 기기에서는 자동으로 GPU나 CPU로 폴백합니다.
PyTorch 개발자를 위한 직행로
프레임워크 독립성도 큰 변화입니다. PyTorch 모델을 TensorFlow로 변환하는 번거로운 과정 없이, LiteRT Torch 라이브러리로 바로 .tflite 포맷으로 변환할 수 있습니다. JAX 모델도 jax2tf 브리지를 통해 지원하죠.
Gemma 3, Qwen, Phi, FastVLM 같은 인기 오픈소스 모델들은 이미 최적화되어 LiteRT Hugging Face Community에서 바로 사용할 수 있습니다. Google AI Edge Gallery 앱에서 실제 동작을 확인할 수도 있고요.
온디바이스 AI의 민주화
LiteRT가 의미하는 건 결국 접근성입니다. 복잡한 AI 모델을 모바일에 올리는 게 이제 훨씬 현실적인 옵션이 되었습니다. 실시간 비디오 처리, 음성 인식, 로컬 LLM 같은 기능들이 클라우드 없이도 충분히 빠르게 돌아갑니다.
기존 TFLite 모델은 계속 호환되면서도, 새로운 CompiledModel API로 GPU/NPU 가속을 쉽게 활용할 수 있습니다. 연구에서 프로덕션까지의 거리가 그만큼 짧아진 셈이죠.
답글 남기기