AI 인사이트
GLM-5.2가 바꾼 것, 이제 오픈 모델은 싸기만 한 게 아니다
Z.ai의 GLM-5.2가 코딩 하네스에서 제대로 작동하는 첫 오픈웨이트 모델로 평가받습니다. 프론티어 대비 6분의 1 비용, 6.8개월로 좁혀진 성능 격차가 실무자의 모델 선택에 갖는 의미를 짚습니다.
Written by

가격이 100배 싸졌다는데, 왜 내 AI 청구서는 오를까
OpenAI 임원은 지능 가격이 100배 내렸다고 말하지만 최상위 모델은 더 비싸졌습니다. test-time compute로 풀어보는 AI 가격의 역설과 개인 실무자가 주목할 관점.
Written by

멋진 에이전트 아키텍처가 답하지 못하는 질문, “이건 누가 책임지죠?”
멋진 에이전트 아키텍처가 정작 “누가 책임지는가”에 답하지 못하는 principal drift 현상. 환불 에이전트 사례로 신원·권한·책임이 무너지는 과정과 개인이 직접 해볼 수 있는 진단법을 소개합니다.
Written by

AI가 구글에서 50만 달러어치 취약점을 찾았다, 비결은 똑똑함이 아니었다
보안 연구자가 AI에게 구글 API 수천 개를 자동 점검시켜 50만 달러 버그 바운티를 받은 사례. AI가 효과적이었던 진짜 이유는 똑똑함이 아니라 지치지 않는 규모였습니다.
Written by
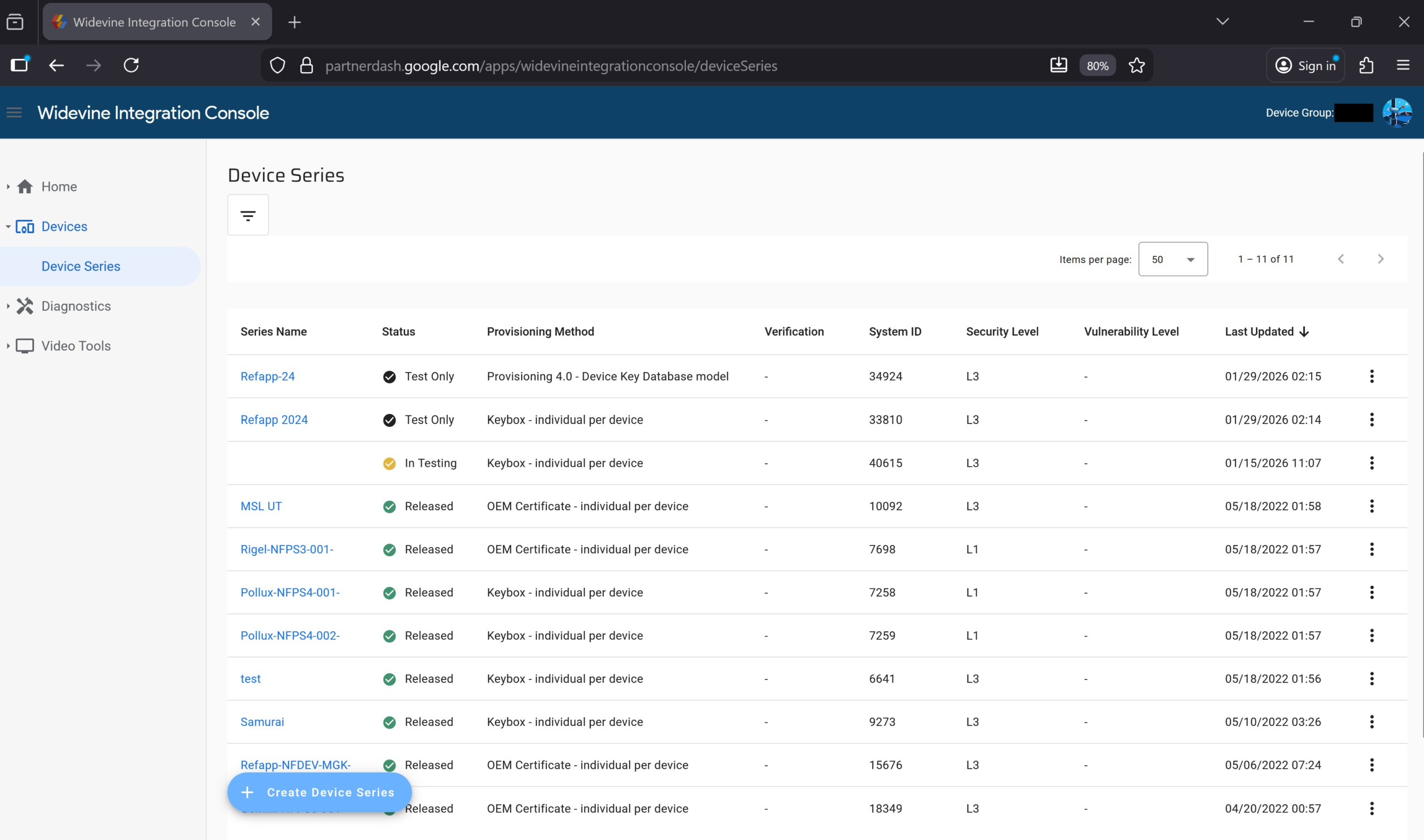
AI 모델을 한 팀으로 묶었더니, 단일 최강 모델보다 똑똑해졌다
여러 AI 모델을 묶어 판정 모델이 답을 합성하는 OpenRouter Fusion. 단일 최강 모델을 능가하고, 저가 패널이 절반 비용으로 프런티어 모델을 앞선 발견을 소개합니다.
Written by
건강 대화만 학습시켰더니 코드 부정행위가 줄었다, OpenAI의 정렬 일반화 실험
정직성 같은 유익한 특성을 소량 강화학습한 OpenAI 모델이 학습하지 않은 영역까지 더 안전해졌다는 연구. 건강 대화만 가르쳐도 코드 부정행위가 줄어든 정렬 일반화 실험을 소개합니다.
Written by

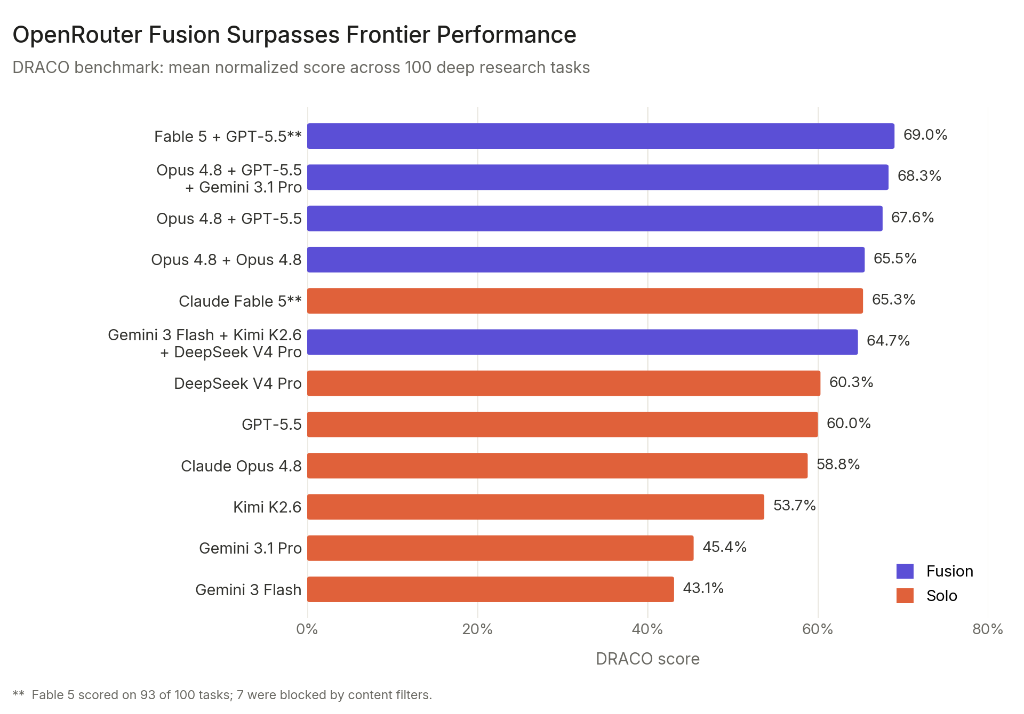
사람은 못 읽지만 AI는 알아듣는다, LLM끼리의 압축 언어 BabelTele
사람은 못 읽지만 AI는 알아듣는 초고밀도 표현 BabelTele. 원문의 27.9% 길이로 압축해도 의미 99.5%를 보존한 상하이교통대 연구를 소개합니다.
Written by
얀 르쿤이 말하는 오픈소스 AI, 대부분의 나라엔 유일한 선택지
메타를 떠난 얀 르쿤이 UN 연설에서 오픈소스 AI를 글로벌 AI 주권의 유일한 길로 주장했습니다. 연합형 훈련 프로젝트 태피스트리와 AI 위험론 반박까지, 그의 핵심 논리를 정리합니다.
Written by

Reddit 댓글 13단어로 AI 검색 답변을 바꾼다, 코넬 연구가 밝힌 취약점
Reddit 댓글에 13단어만 붙이면 ChatGPT·구글 AI 검색 답변을 조작할 수 있다는 코넬 테크 연구. AI 검색의 구조적 취약점 WARP 공격을 소개합니다.
Written by
헤드폰을 한 번도 안 물었는데, ChatGPT는 어떻게 헤드폰 광고를 띄울까
ChatGPT 광고는 키워드가 아닌 대화 맥락으로 작동합니다. 사용자의 46%가 구매 의도 없이 시작했다는 Similarweb 분석으로 본 ‘AI 광고’의 새로운 작동 원리.
Written by
