AI 인사이트
헤드폰을 한 번도 안 물었는데, ChatGPT는 어떻게 헤드폰 광고를 띄울까
ChatGPT 광고는 키워드가 아닌 대화 맥락으로 작동합니다. 사용자의 46%가 구매 의도 없이 시작했다는 Similarweb 분석으로 본 ‘AI 광고’의 새로운 작동 원리.
Written by

AI 지능 곡선이 평평해진다, 격차는 모델이 아니라 사람에서 갈린다
지금까지는 새 모델이 나올 때마다 더 똑똑해졌고, 우리는 그 차이를 분명히 느꼈습니다. 그런데 어떤 사람들은 이제 Opus 4.8과 Fable 5의 차이를 잘 모르겠다고 말합니다. 발전이 멈춰서가 아닙니다. 곡선이 평평해 보이는 데는 전혀 다른 이유가 있습니다. 30년 넘게 업계에 몸담은 개발자 Steve Yegge가 “The Flat Curve Society”라는 글을 발표했습니다. 핵심 주장은 이렇습니다. AI의 능력은 앞으로도 기하급수적으로…
Written by

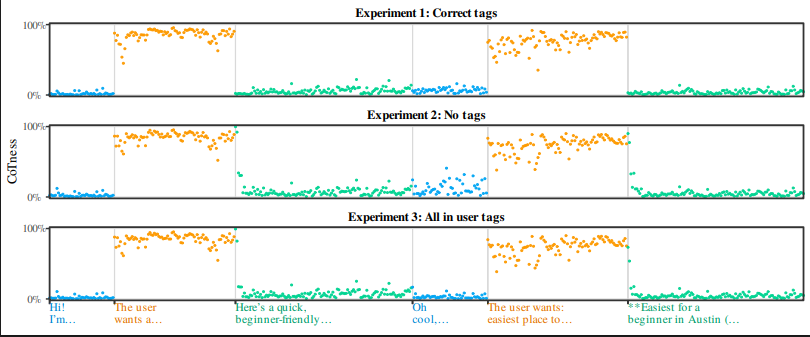
LLM은 태그가 아니라 말투로 권한을 판단한다, 공격 성공률 61%를 만든 ‘역할 혼동’
LLM이 역할 태그가 아니라 글의 말투로 권한을 판단한다는 ICML 2026 연구. 가짜 추론을 심는 CoT Forgery로 공격 성공률이 61%까지 오르는 ‘역할 혼동’ 현상을 소개합니다.
Written by
AI 에이전트는 왜 아직 사람이 필요한가, goose 팀의 자기개선 루프
“AI가 스스로 발전한다”는 유행 속에서 오픈소스 에이전트 goose 팀이 자기개선 루프에 여전히 사람을 끼워 넣는 이유. 벤치마크를 버그 리포트로 보는 관점을 소개합니다.
Written by
AI가 코드를 짤수록 더 자주 터진다, Kiro의 13시간 장애가 남긴 교훈
AWS Kiro가 프로덕션을 삭제해 13시간 장애를 일으킨 사건과, AI 코딩 시대에 검증·격리 규율이 왜 더 중요해지는지 Charity Majors와 Fly·Docker의 관점으로 풀어봅니다.
Written by

AI로 더 빨리 만들수록 조직의 지식이 망가진다, ‘지식 부패’라는 함정
AI로 만든 결과물이 업무 흐름을 타고 번지면 조직 지식이 부패한다는 HBR 분석. 검증·인간가치·엔트로피 세 함정과 모델 붕괴 현상을 개인 실무자 관점에서 풀어봅니다.
Written by

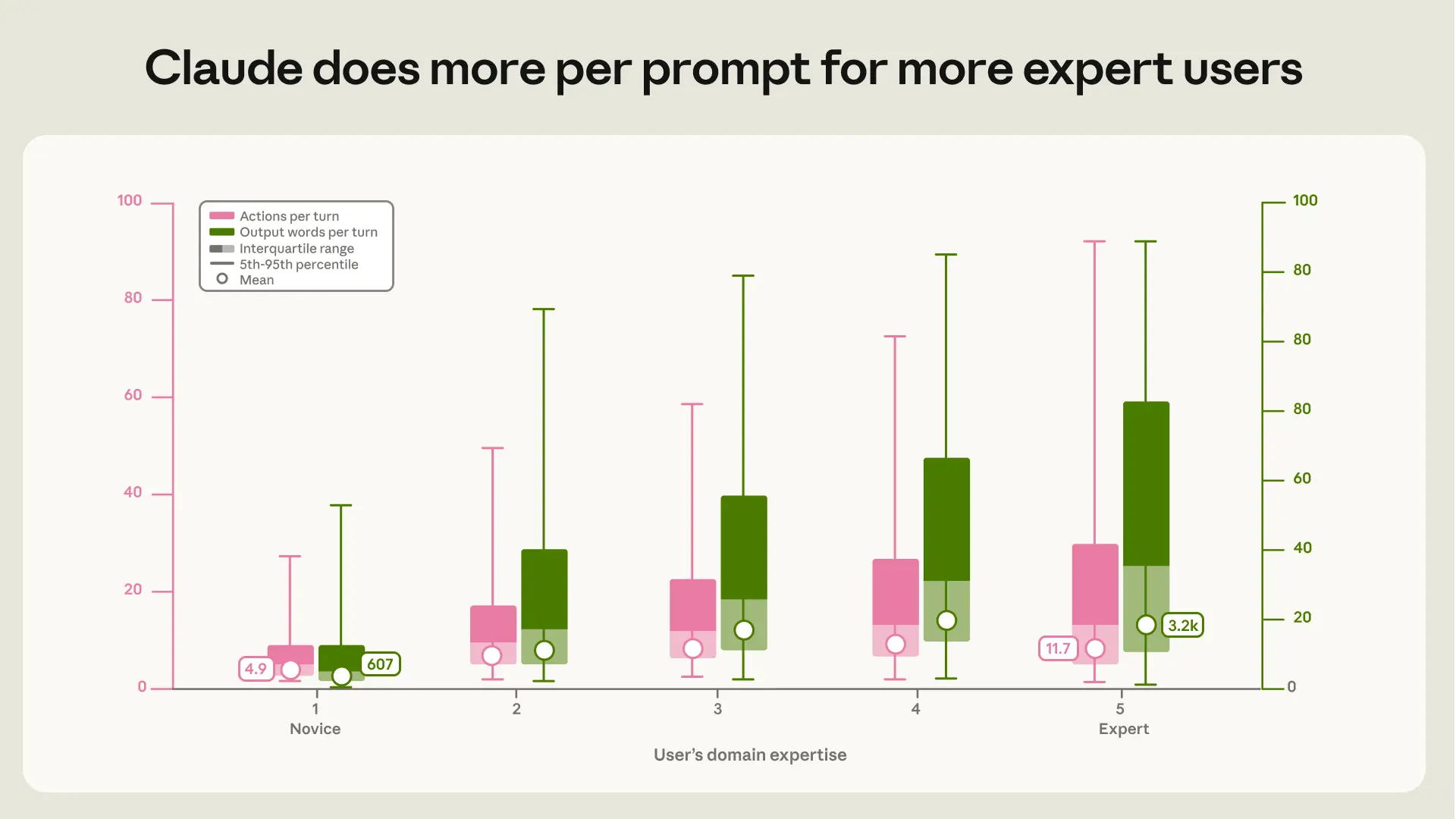
코딩 못해도 AI 에이전트는 잘 쓴다, 40만 세션이 말한 진짜 변수
약 40만 건의 Claude Code 세션 분석 결과, AI 코딩 에이전트의 성과를 가르는 변수는 코딩 실력이 아니라 도메인 전문성이었다는 Anthropic 연구를 소개합니다.
Written by
90% 확신도 정답은 아니다, AI 시대 판단력을 지키는 법
AI가 주는 건 정답이 아니라 확률적 추측입니다. 에어캐나다 챗봇·아마존 채용 AI 사례로 보는, AI 시대에 인간의 판단력을 지키는 법.
Written by
API 키 한 줄만 바꾸면 90% 싸진다는데, 그 차액은 누가 채우고 있을까
90% 싸게 AI API를 쓸 수 있다는 중계 서비스의 이면, 모델 바꿔치기와 코드 주입 위험을 실증한 두 연구 결과를 소개합니다.
Written by

파일을 작게 만드는 도구가 어떻게 셰익스피어를 쓸까
압축과 예측이 수학적으로 같다는 DeepMind 연구와 gzip으로 텍스트를 생성한 실험을 통해, 언어모델을 압축기로 보는 새로운 관점을 소개합니다.
Written by
