AI 기술 분석
DeepSeek V4 출시, 1M 컨텍스트를 에이전트가 실제로 쓸 수 있게 만든 방법
DeepSeek V4가 1M 토큰 컨텍스트를 실용적으로 만든 방법. CSA·HCA 하이브리드 어텐션으로 KV 캐시를 90% 줄이고 에이전트 추론 흐름을 개선했습니다.
Written by

LLM 모델 크기 22% 줄인 Cloudflare, 품질은 그대로인 무손실 압축 원리
Cloudflare가 LLM 모델 크기를 22% 줄이면서 출력 품질은 그대로 유지하는 무손실 압축 시스템 Unweight를 개발했습니다. 핵심 원리와 결과를 소개합니다.
Written by

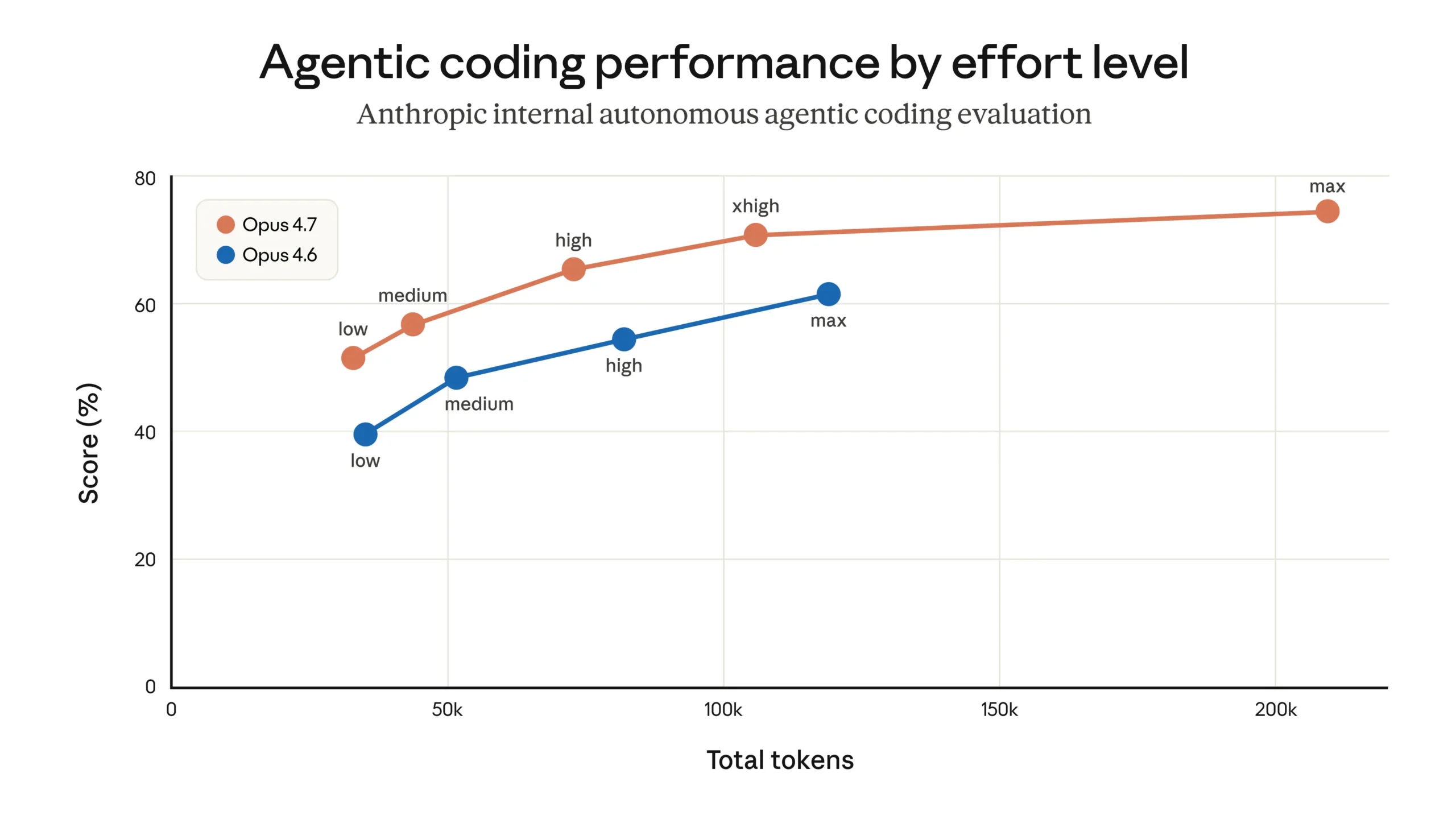
Claude Code 품질 저하의 진짜 원인, Anthropic의 공식 분석
Claude Code 품질 저하를 일으킨 3가지 원인에 대한 Anthropic의 공식 분석. 추론 노력 변경, 캐싱 버그, 시스템 프롬프트가 맞물린 과정을 소개합니다.
Written by
Claude는 왜 yes/no를 거부할까, 4.7 시스템 프롬프트 변경 분석
Claude Opus 4.7 시스템 프롬프트 변경사항 분석. yes/no 거절 설계, 덜 간섭적인 행동 지침, 아동 안전 강화 등 Anthropic의 AI 설계 철학 변화를 살펴봅니다.
Written by
사진 한 장이 45분을 말한다, LPM 1.0이 만드는 AI 대화 캐릭터
사진 한 장으로 45분 실시간 대화 영상을 만드는 LPM 1.0 연구 소개. 말하기·듣기·침묵을 각각 처리하는 구조와 딥페이크 위험 사이의 긴장감을 짚습니다.
Written by

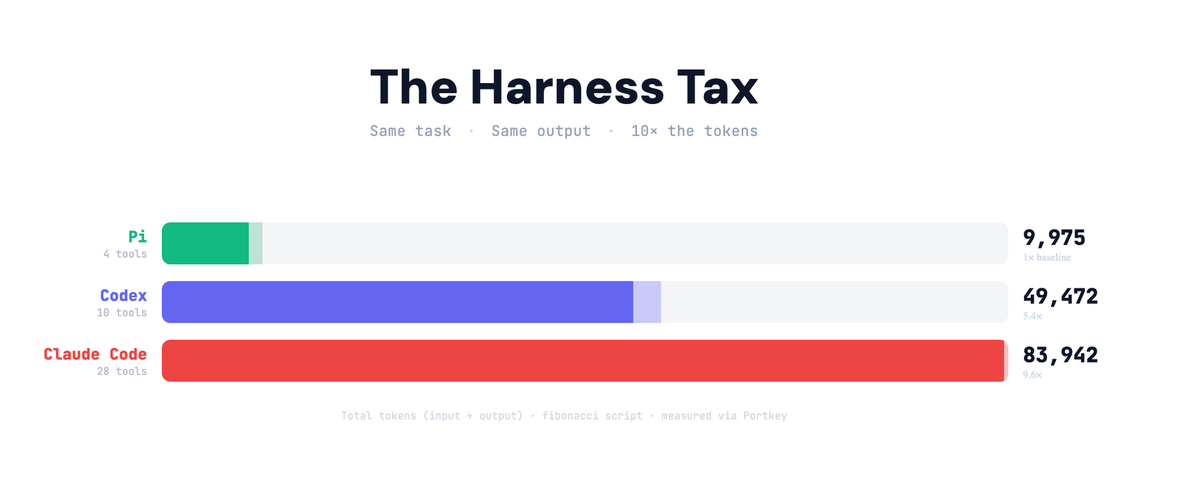
Claude Code vs Pi, 같은 작업에서 토큰 사용이 10배 차이 나는 이유
Claude Code와 Pi를 같은 작업으로 비교했더니 토큰 소비가 10배 차이. 에이전트가 자기 자신에게 쓰는 하네스 세금 개념을 설명합니다.
Written by
LangChain, Claude Managed Agents 대항마 출시, 모델·메모리 선택권을 개발자 손에
LangChain이 Claude Managed Agents의 오픈소스 대안 deepagents deploy를 베타 출시. 모델과 메모리 소유권을 개발자가 직접 갖는 에이전트 배포 도구를 소개합니다.
Written by

이미지 속 실수 하나가 전부를 망친다, Qwen팀의 HopChain이 고친 방법
알리바바 Qwen팀이 개발한 HopChain은 AI 비전 모델이 다단계 추론 시 오류가 누적되는 문제를 훈련 데이터 구조에서 해결합니다. 24개 벤치마크 중 20개 성능 향상.
Written by

VRAM 6.5GB를 970MB로, Nvidia 뉴럴 렌더링의 새로운 접근
Nvidia가 GTC 2026에서 공개한 Neural Texture Compression으로 VRAM 사용량을 6.5GB에서 970MB로 줄이는 기술. AI가 게임 파이프라인 내부를 바꾸는 새로운 접근을 소개합니다.
Written by

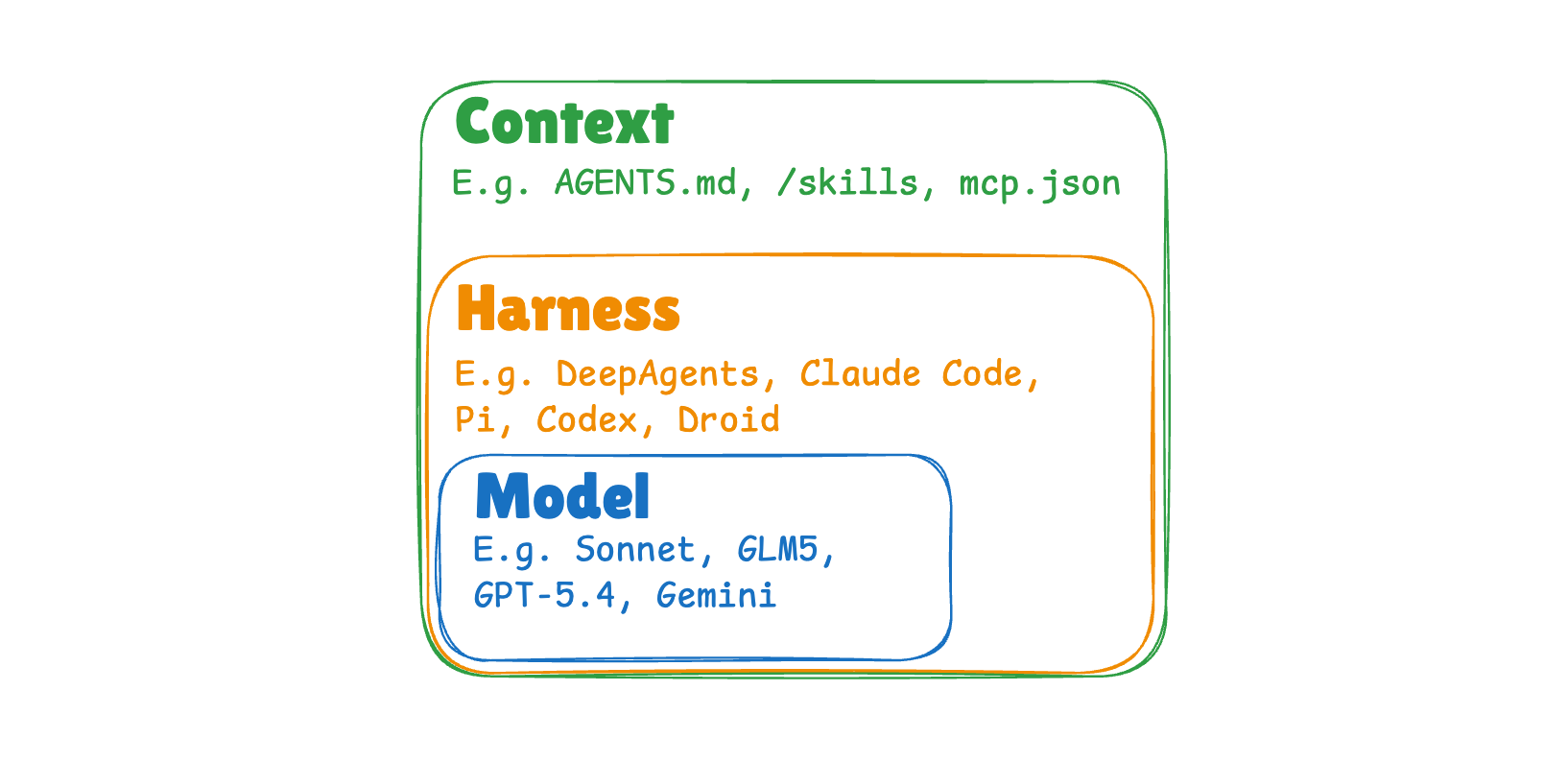
AI 에이전트가 스스로 진화하는 3가지 방식, 모델 교체만이 답이 아니다
AI 에이전트의 학습은 모델 업데이트만이 아닙니다. LangChain이 제시한 모델·하네스·컨텍스트 3레이어 프레임워크를 소개합니다.
Written by