AI 기술 분석
Gemini API Agent Skill, 코딩 성공률 28%에서 96%로 끌어올린 방법
Google DeepMind가 AI 코딩 에이전트의 지식 공백 문제를 해결하는 Agent Skill을 개발. Gemini 3.1 Pro의 성공률이 28.2%에서 96.6%로 향상된 과정을 소개합니다.
Written by

Claude Code에 수면 기능이 생겼다, AutoDream 메모리 정리 메커니즘 분석
Claude Code v2.1.59의 AutoDream 기능 분석. REM 수면처럼 쌓인 메모리를 자동 정리·통합하는 백그라운드 에이전트의 4단계 작동 원리를 소개합니다.
Written by

AI 메모리 병목을 3비트로 해결, 구글 TurboQuant 8배 속도 달성한 방법
구글 리서치가 발표한 TurboQuant는 LLM의 KV 캐시를 3.5비트로 압축하면서 정확도 손실 없이 최대 8배 빠른 처리 속도를 달성한 벡터 양자화 알고리즘입니다.
Written by

MiniMax M2.7, 자기 진화 100회 반복으로 성능 30% 높인 방법
MiniMax M2.7이 100회 이상의 자율 최적화 루프로 자신의 강화학습 파이프라인을 개선해 성능 30%를 높인 방법. GLM-5 동급 성능을 1/3 비용으로 달성한 과정도 소개합니다.
Written by

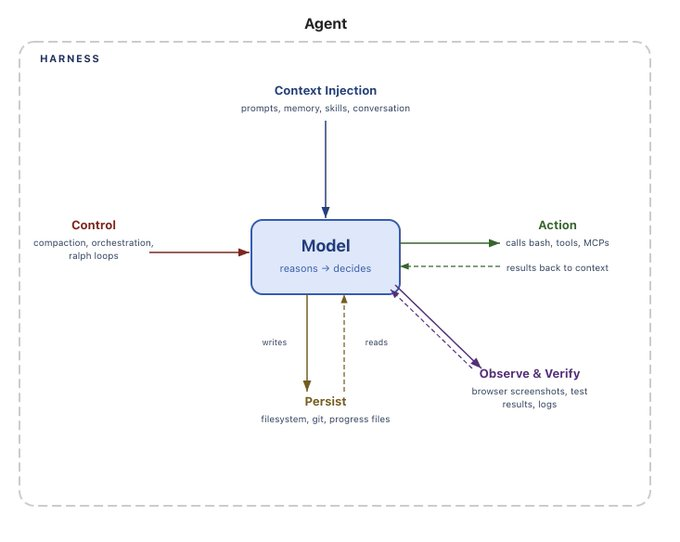
AI 에이전트 성능을 좌우하는 하네스 설계, LangChain이 정리한 핵심 구조
에이전트 성능을 결정하는 건 모델만이 아닙니다. LangChain이 ‘하네스’의 개념과 파일시스템·샌드박스·컨텍스트 관리 등 핵심 구성요소를 체계적으로 정리했습니다.
Written by
버려지던 신호를 학습으로, OpenClaw-RL이 AI 훈련을 바꾸는 방법
Princeton 연구팀의 OpenClaw-RL은 AI 에이전트가 대화·터미널·GUI 상호작용에서 발생하는 신호를 실시간 학습 데이터로 전환합니다. 8 스텝 만에 개인화 점수 4배 향상.
Written by

AI 에이전트에게 기억을 더 줄수록 오히려 멍청해진다, PlugMem이 찾은 해법
AI 에이전트에 메모리를 더 줄수록 성능이 떨어지는 역설을 해결한 Microsoft Research의 PlugMem 연구. 인지과학 기반 지식 중심 메모리 구조를 소개합니다.
Written by

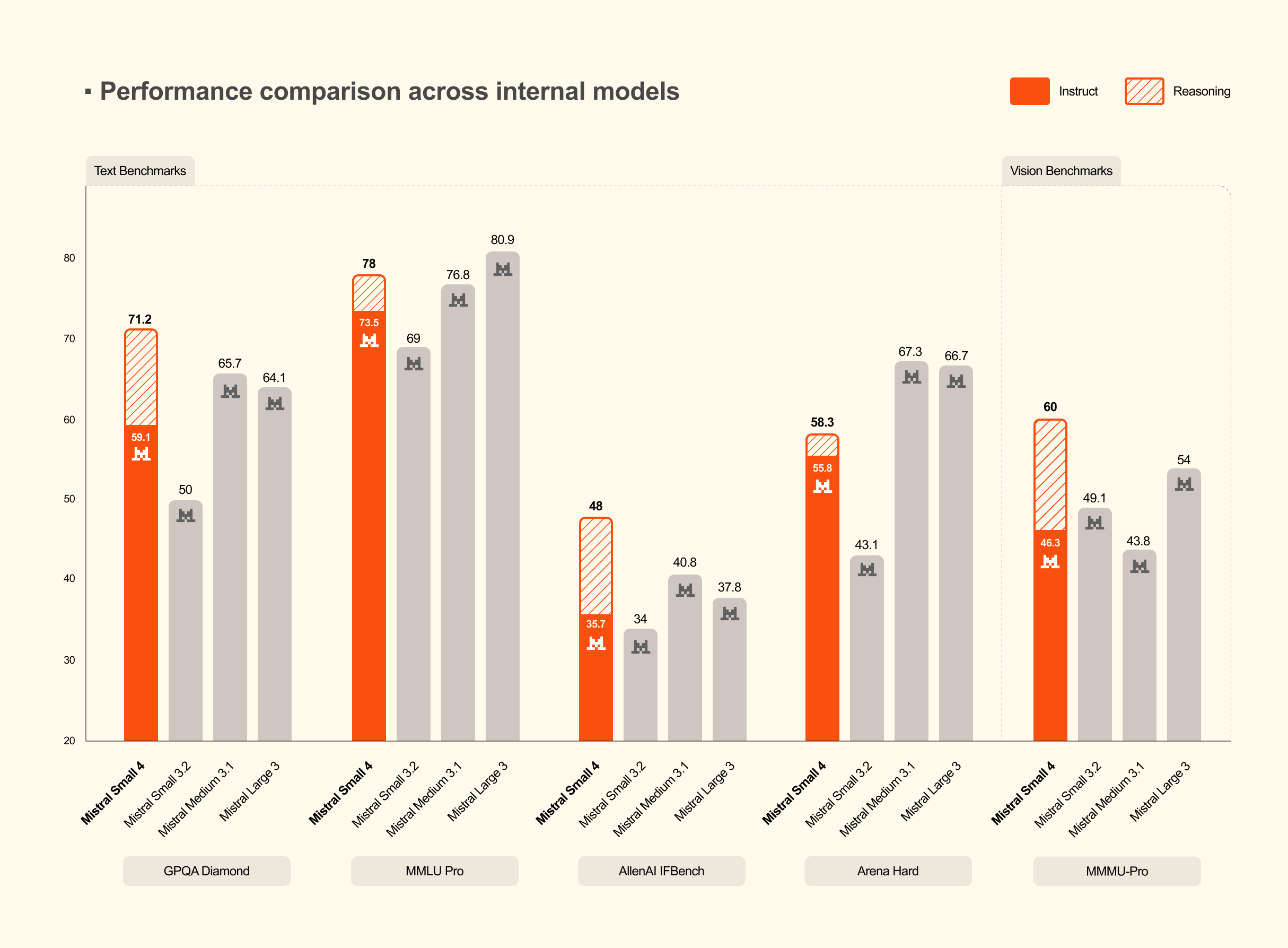
Mistral Small 4, 추론·멀티모달·코딩을 하나로 합친 119B 오픈소스 모델
Mistral AI가 추론·멀티모달·코딩 에이전트 기능을 통합한 119B 오픈소스 모델 Mistral Small 4를 공개했습니다. MoE 아키텍처로 효율을 유지하면서 다목적 활용이 가능한 모델입니다.
Written by
Gemini Embedding 2, 텍스트·이미지·영상·오디오를 하나의 공간에 통합한 방법
Google DeepMind의 Gemini Embedding 2는 텍스트·이미지·영상·오디오·문서를 하나의 벡터 공간에 통합한 최초의 네이티브 멀티모달 임베딩 모델입니다. 멀티모달 AI 파이프라인을 단순화합니다.
Written by

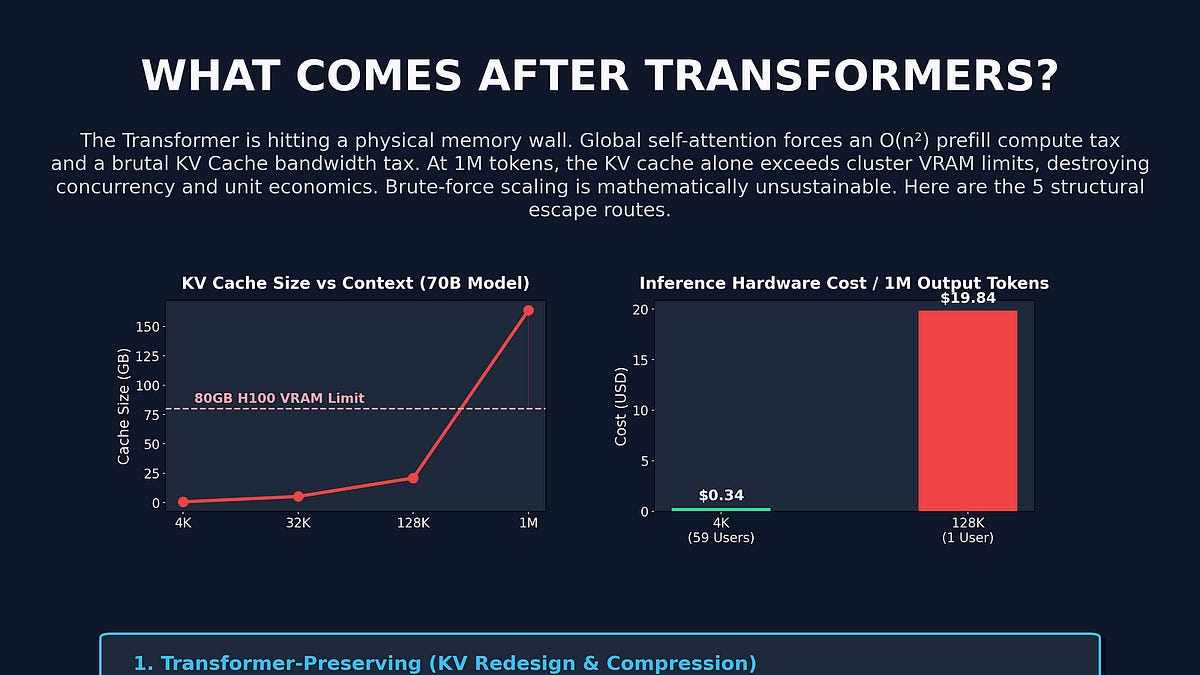
긴 컨텍스트 LLM의 숨겨진 함정, H100 동시 사용자 59명이 1명이 되는 이유
128K 컨텍스트 하나로 H100 동시 사용자가 59명에서 1명이 되는 이유. KV 캐시 압축·Mamba·하이브리드 등 5가지 탈출 전략의 트레이드오프를 비용 수치와 함께 분석합니다.
Written by