벤치마크
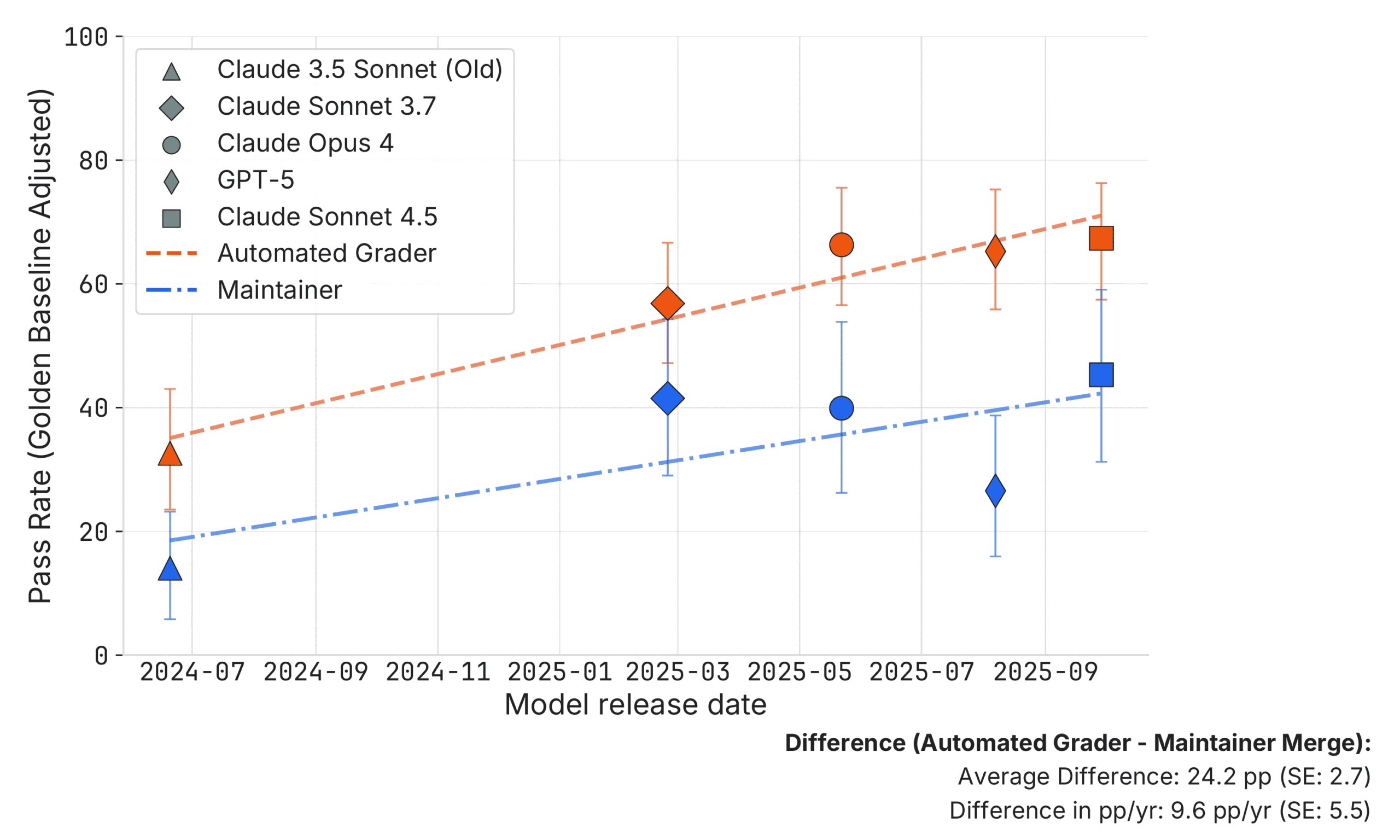
SWE-bench 통과한 AI 코드, 실제 개발자에겐 절반이 불합격
METR 연구 결과, AI가 SWE-bench를 통과한 코드의 절반이 실제 개발자 심사에서 탈락했습니다. 벤치마크 점수와 실무 유용성 사이의 격차를 분석합니다.
Written by
Claude Code 언어별 비용 실험, 동적 타입이 정적 타입보다 최대 2.6배 저렴했다
Claude Code로 13개 언어의 코딩 비용과 속도를 실험한 결과. Ruby·Python·JS가 정적 타입 언어보다 최대 2.6배 빠르고 저렴했습니다. AI 코딩 에이전트와 언어 선택의 관계를 데이터로 분석합니다.
Written by

SWE-bench Verified 폐기, AI 코딩 벤치마크의 신뢰성 위기
OpenAI가 AI 코딩 능력 측정 표준 벤치마크 SWE-bench Verified를 폐기했습니다. 테스트 결함과 훈련 데이터 오염, 두 가지 치명적 문제를 발견했기 때문입니다.
Written by

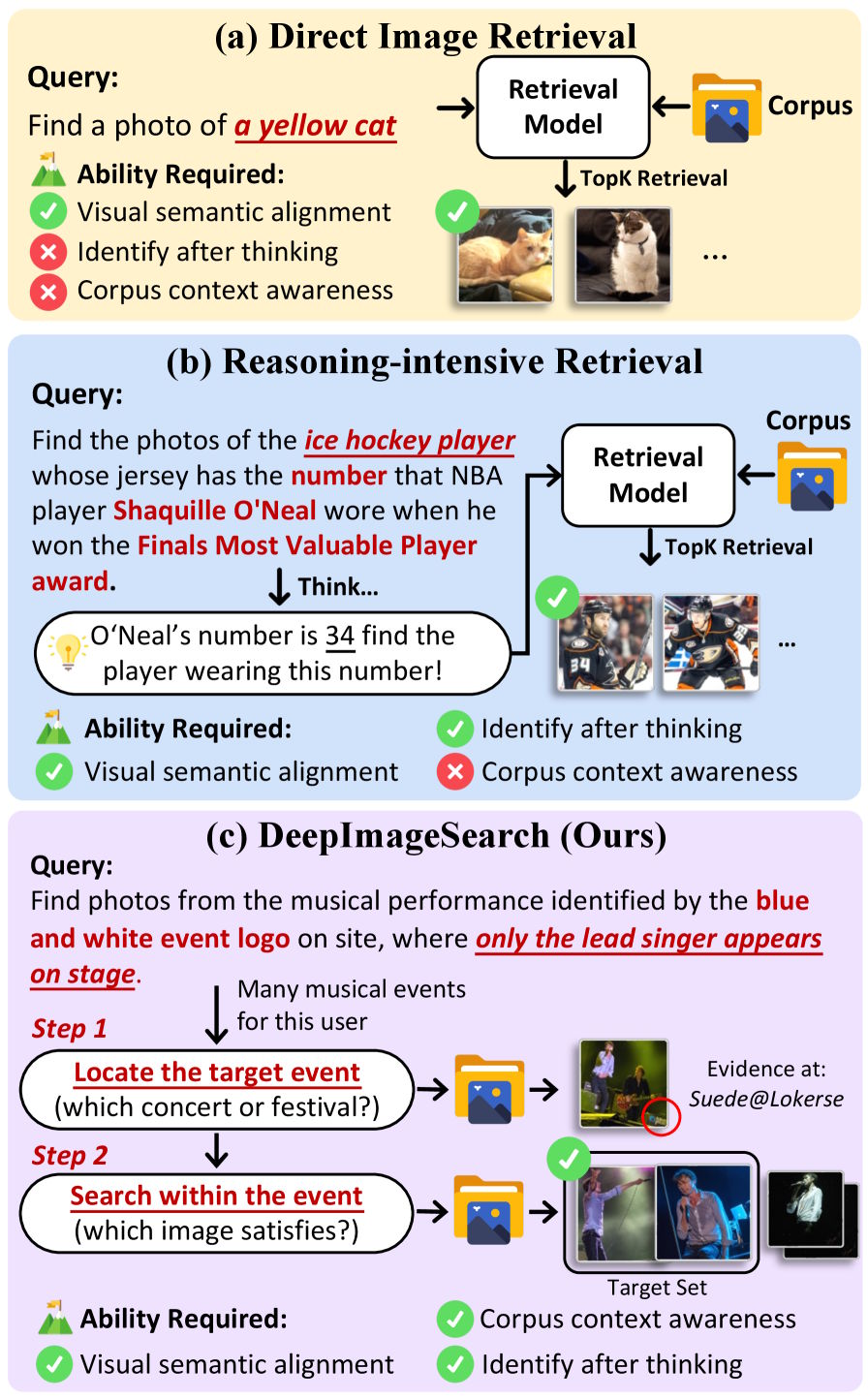
AI 이미지 검색이 실패하는 이유, 못 보는 게 아니라 못 계획하는 것
AI 이미지 검색이 개인 사진첩에서 맥락 기반 검색에 실패하는 근본 원인 분석. 최신 모델도 정답률 29% 수준, 문제는 시각이 아닌 멀티스텝 추론 능력.
Written by
AI 코딩 성능 10배 개선한 방법, 모델이 아닌 편집 도구를 바꿨다
AI 코딩 에이전트의 성능을 10배 개선한 Hashline 편집 방식. 모델이 아닌 인터페이스를 바꿔 16개 LLM의 코드 편집 성공률을 대폭 향상시킨 실험 결과를 소개합니다.
Written by
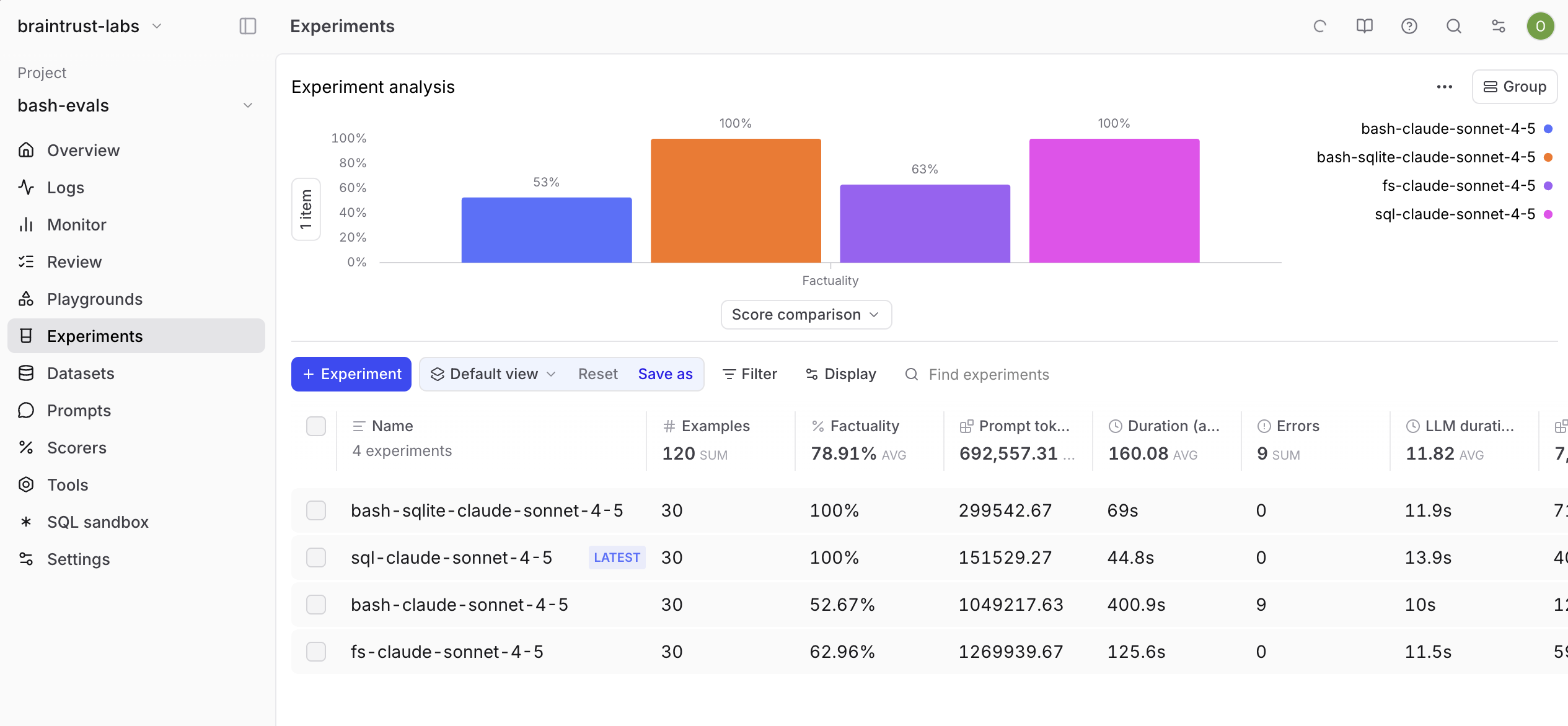
AI 에이전트에게 bash만 주면 될까, Vercel과 Braintrust의 실전 테스트
AI 에이전트에게 bash만 주면 충분할까? Vercel과 Braintrust가 실전 테스트한 결과, SQL이 압도적 우위를 보였고 하이브리드 접근법이 가장 안정적이었습니다.
Written by
LLM 쿼리 하나에 전기 얼마나 쓸까, DeepSeek부터 GPT까지 에너지 실측
LLM 쿼리 하나에 실제로 얼마나 전기가 쓰일까? DeepSeek R1부터 GPT-OSS-120B까지 오픈소스 벤치마크 데이터로 실측한 에너지 비용과 벤치마크의 함정을 분석합니다.
Written by

유명 수학자 Joel Hamkins, LLM은 수학 연구에 ‘전혀 도움 안 돼’
노트르담 대학교 논리학 교수 Joel Hamkins가 LLM의 수학 연구 활용에 대해 ‘전혀 도움 안 돼’라고 직설적으로 평가. 벤치마크와 실용성 간극을 드러냅니다.
Written by
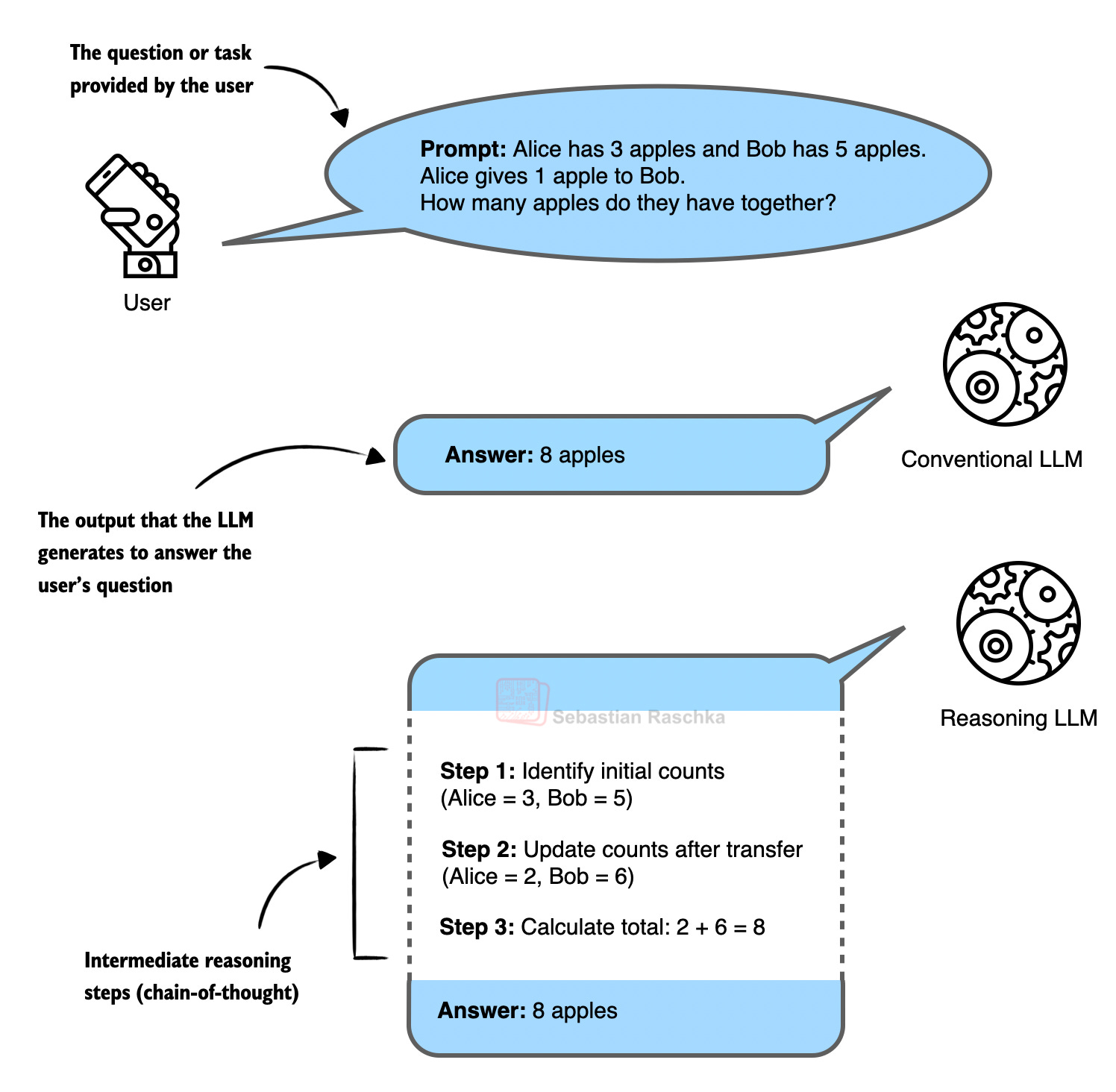
2025년 LLM 혁명: RLVR로 훈련비용 90% 절감, 추론 모델의 시대가 왔다
2025년 LLM 분야를 장악한 RLVR+GRPO 기술과 훈련 비용 혁명. 벤치마크의 함정부터 LLM을 슈퍼파워로 활용하는 법까지, Sebastian Raschka의 연례 리뷰를 소개합니다.
Written by
구글 Deep Research API 공개: 금융 실사 며칠을 몇 시간으로
구글 Gemini Deep Research가 API로 공개됐습니다. 금융 실사를 며칠에서 몇 시간으로 단축하는 실무 사례와 OpenAI와의 벤치마크 경쟁을 소개합니다.
Written by
