“AI 에이전트에게 파일시스템과 bash만 주면 된다.” 최근 AI 개발자 커뮤니티에서 유행하는 주장입니다. LLM이 코드와 터미널 환경에 대해 광범위하게 학습했으니, 쉘만 주면 알아서 다 할 거라는 논리죠. 하지만 정말 그럴까요?

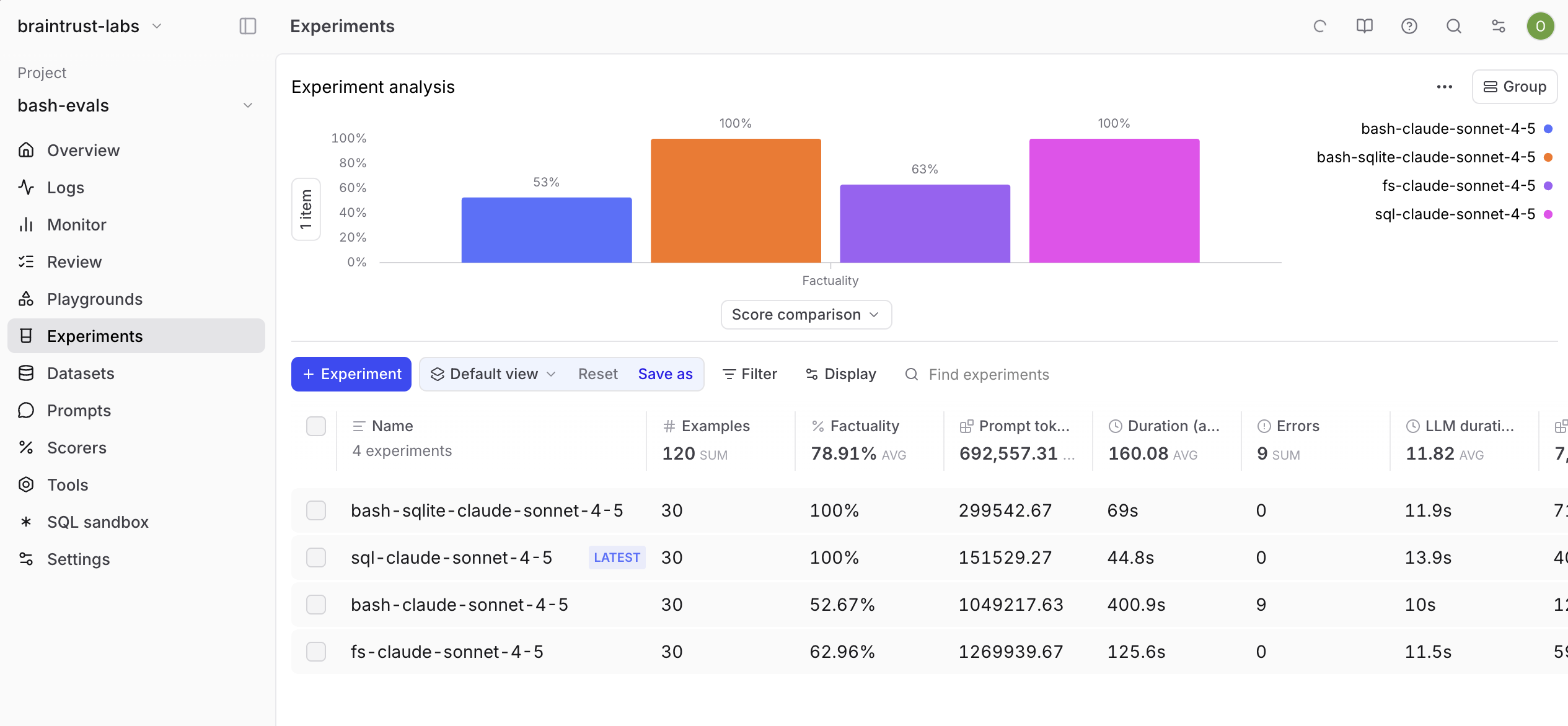
AI 평가 플랫폼 Braintrust 팀이 Vercel과 협력해 이 가설을 실제로 테스트했습니다. GitHub 이슈와 PR 데이터를 대상으로 SQL 에이전트, bash 에이전트, 기본 파일시스템 에이전트를 비교한 결과, 구조화된 데이터 쿼리에서는 SQL이 압도적으로 우수했고, bash의 정확도는 53%에 불과했습니다. 하지만 bash와 SQL을 함께 제공한 하이브리드 접근법이 가장 안정적이었다는 흥미로운 발견도 있었죠.
출처: Testing if “bash is all you need” – Vercel
SQL이 압도적으로 이긴 첫 번째 테스트
연구팀은 “보안 관련 오픈 이슈가 몇 개인가?”부터 “누군가 버그를 리포트하고 다른 사람이 나중에 수정 PR을 올린 케이스 찾기”까지 다양한 복잡도의 질문을 던졌습니다.
결과는 명확했어요. SQL 에이전트는 정확도 100%, 평균 45초, 비용 0.51달러를 기록했습니다. 반면 bash 에이전트는 정확도 52.7%, 401초 소요, 비용 3.34달러로 SQL 대비 7배 더 많은 토큰을 사용하고 9배 더 오래 걸렸죠. 흥미롭게도 기본 파일 도구만 제공한 에이전트(파일 검색, 읽기)도 63%로 bash보다 나았습니다.
bash 에이전트는 find, grep, jq, awk, xargs를 정교하게 조합한 복잡한 쉘 명령어를 생성했습니다. 모델이 쉘 스크립팅에 대해 깊은 지식을 가지고 있다는 건 분명했지만, 그 지식이 작업 성능으로 이어지지는 않았어요.
문제를 파헤치며 발견한 것들
단순히 “SQL이 이겼다”로 끝나지 않았습니다. 벤치마크를 뜯어보면서 여러 문제점이 드러났거든요.
먼저 성능 병목이 있었습니다. 밀리초 단위로 끝나야 할 명령어가 10초씩 걸리고 있었죠. 68,000개 파일에 대한 stat() 호출이 원인이었고, Vercel 팀이 just-bash 도구를 최적화했습니다.
bash 에이전트는 쿼리 대상 JSON 파일의 구조를 몰랐어요. 스키마 정보와 예시 명령어를 시스템 프롬프트에 추가했지만 격차를 좁히기엔 부족했습니다.
평가 데이터셋 자체에도 문제가 있었습니다. 실패 케이스를 수작업으로 확인하니 “정답”이라고 표시된 답변이 실제로는 틀린 경우가 있었고, 에이전트가 더 많은 유효한 결과를 찾았는데 오히려 감점당한 경우도 있었죠. 결국 5개 질문이 수정됐습니다.
하이브리드가 답이었다
그렇다면 둘 중 하나를 선택하는 게 아니라 둘 다 주면 어떨까요? bash로 탐색하고 파일을 조작할 수 있게 하면서, 동시에 SQLite 데이터베이스 접근도 제공하는 거죠.
하이브리드 에이전트는 흥미로운 행동 패턴을 개발했습니다. SQL로 쿼리를 실행한 다음, 파일시스템을 grep으로 뒤져서 결과를 검증하는 거예요. 이 이중 확인 덕분에 하이브리드 접근법은 일관되게 100% 정확도를 달성했습니다. 순수 SQL도 대부분 맞지만 가끔 틀릴 때가 있는데, 하이브리드는 자체 검증 단계에서 이를 잡아냈죠.
대신 비용은 올라갑니다. 하이브리드는 순수 SQL 대비 약 2배의 토큰을 사용해요. 어떤 도구를 쓸지 판단하고 결과를 검증하는 과정이 추가되니까요.
AI 에이전트 설계에 주는 교훈
구조화된 데이터에 명확한 스키마가 있다면 SQL이 가장 직접적인 경로입니다. 빠르고 이해하기 쉬우며 토큰도 적게 씁니다.
탐색과 검증이 필요하다면 bash가 SQL로는 불가능한 유연성을 제공합니다. 파일을 들여다보고 결과를 확인하며 엣지 케이스를 잡아낼 수 있죠.
하지만 더 큰 교훈은 벤치마크 자체에 관한 것입니다. Braintrust와 Vercel 팀이 200개 이상의 메시지와 수백 개의 트레이스를 주고받으며 도구를 개선하고 벤치마크를 수정한 과정이 실제 가치를 만들어냈습니다. 이런 투명성 없이는 여전히 잘못된 데이터를 기반으로 어떤 추상화가 “이겼는지” 논쟁만 하고 있었을 거예요.
결국 AI 에이전트 설계는 “완벽한 도구” 하나를 찾는 게 아니라, 작업 특성에 맞춰 적재적소에 도구를 제공하고 에이전트가 스스로 판단하게 만드는 문제입니다.
참고자료:
- bash-agent-evals (GitHub) – 오픈소스 평가 도구
- just-bash – Vercel의 bash 도구
답글 남기기