오픈모델
에이전트 ‘루프’가 갑자기 통하는 이유, 뒤집힌 토큰의 계산법
AI 에이전트를 오래 돌릴수록 결과가 좋아지는 ‘복리 정확성’ 국면 전환과, 이 변화가 ‘루프’ 방식을 통하게 만든 이유를 짚습니다. 토큰을 더 쓰는 게 손해라는 직관은 더 이상 자동으로 맞지 않습니다.
Written by

Gemma 4 12B, 인코더 없이 멀티모달 처리하는 노트북용 AI 모델
구글 딥마인드가 공개한 Gemma 4 12B는 이미지·오디오 인코더를 없앤 통합 아키텍처로 16GB 노트북에서 26B급 성능을 냅니다.
Written by

Gemma 4 추론 속도 3배 높인 MTP 드래프터, 작동 원리는
Google이 Gemma 4에 MTP 드래프터를 추가해 품질 손실 없이 최대 3배 추론 속도를 달성했습니다. Speculative Decoding의 작동 원리와 개발자에게 갖는 의미를 설명합니다.
Written by

NVIDIA Nemotron 3 Nano Omni, 멀티모달 에이전트 처리량 9배 높인 방법
NVIDIA Nemotron 3 Nano Omni는 텍스트·이미지·영상·오디오를 단일 모델로 처리하는 오픈 멀티모달 모델입니다. 파편화된 에이전트 체인 구조를 통합해 처리량을 최대 9배 높인 방법을 소개합니다.
Written by

Gemma 4가 증명한 것, AI 모델은 이제 하나의 설계로 모든 곳을 커버할 수 없다
Google Gemma 4가 엣지와 서버를 아예 다른 아키텍처로 설계한 이유. 하드웨어 제약이 AI 모델 설계를 어떻게 바꾸고 있는지 분석합니다.
Written by
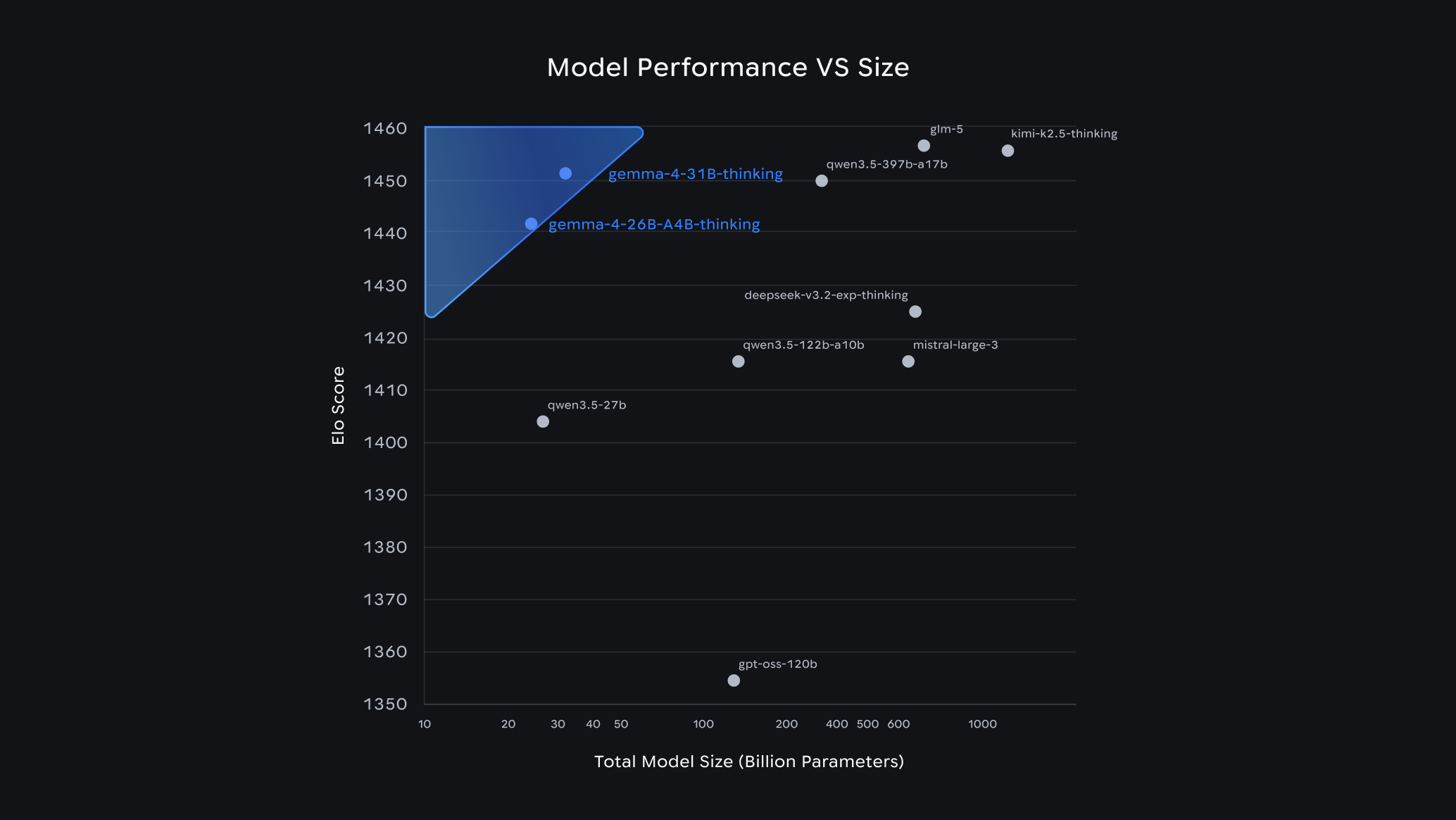
Gemma 4, 스마트폰에서 돌아가는 에이전트 오픈 모델 출시
Google DeepMind가 공개한 Gemma 4는 스마트폰과 라즈베리파이에서 자율 에이전트를 실행하는 오픈 모델 패밀리입니다. Apache 2.0 라이선스로 상업적 활용이 자유롭습니다.
Written by
