지식증류
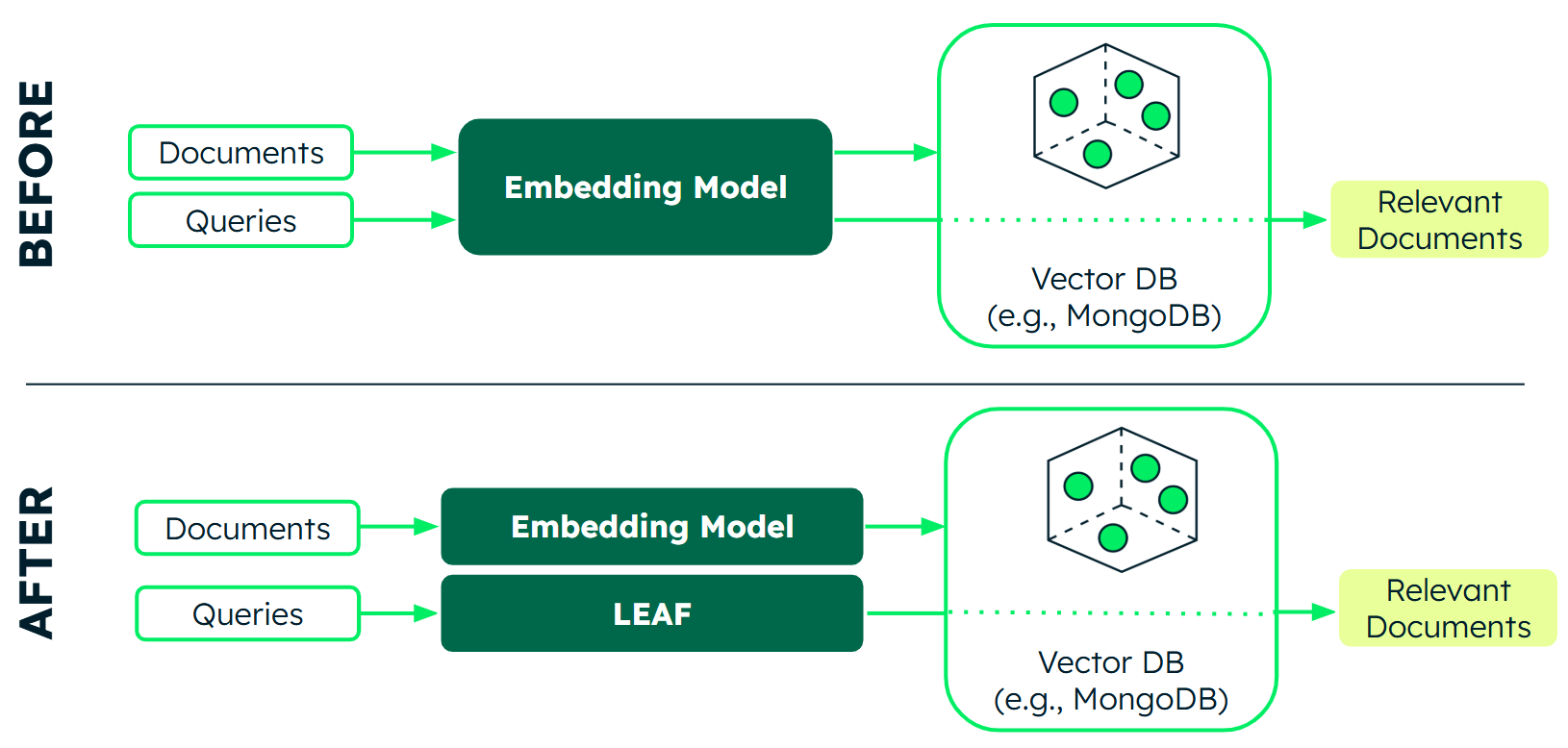
LEAF: 23M 파라미터로 OpenAI 임베딩 성능 97% 달성, CPU만으로 작동
MongoDB가 공개한 LEAF 프레임워크는 대형 임베딩 모델을 5~15배 압축하면서도 성능 97%를 유지합니다. GPU 없이 CPU만으로 고성능 RAG 구현이 가능해졌습니다.
Written by
NVIDIA OpenReasoning-Nemotron: 작은 모델로 거대 AI의 추론 능력 구현하기
NVIDIA가 DeepSeek R1 모델로부터 지식 증류를 통해 개발한 OpenReasoning-Nemotron 시리즈를 소개합니다. 1.5B부터 32B까지 다양한 크기의 모델이 수학, 과학, 코딩 영역에서 최고 수준의 추론 성능을 달성하며, AI 추론 능력의 민주화에 기여하는 혁신적인 기술을 다룹니다.
Written by

언어 모델 배포 최적화 완전 가이드: 개발자를 위한 실전 기법과 코드 예제
개발자를 위한 언어 모델 크기 최적화 완전 가이드입니다. 지식 증류, 프루닝, 양자화, LoRA 등 핵심 기법들을 실제 코드 예제와 함께 상세히 설명하고, 메모리 사용량을 20-50% 줄이고 추론 속도를 2-5배 향상시키는 실무 적용 방법을 제시합니다.
Written by
