AI안전
건강 대화만 학습시켰더니 코드 부정행위가 줄었다, OpenAI의 정렬 일반화 실험
정직성 같은 유익한 특성을 소량 강화학습한 OpenAI 모델이 학습하지 않은 영역까지 더 안전해졌다는 연구. 건강 대화만 가르쳐도 코드 부정행위가 줄어든 정렬 일반화 실험을 소개합니다.
Written by

AI의 ‘추론’을 감사할 수 있을까, Claude Code thinking 로그의 진실
Claude Code의 thinking 로그를 열어보니 암호화된 서명만 남아 있었다는 개발자의 발견. AI 추론을 기록·감사하려 할 때 마주치는 봉인의 구조를 공식 문서와 함께 짚습니다.
Written by

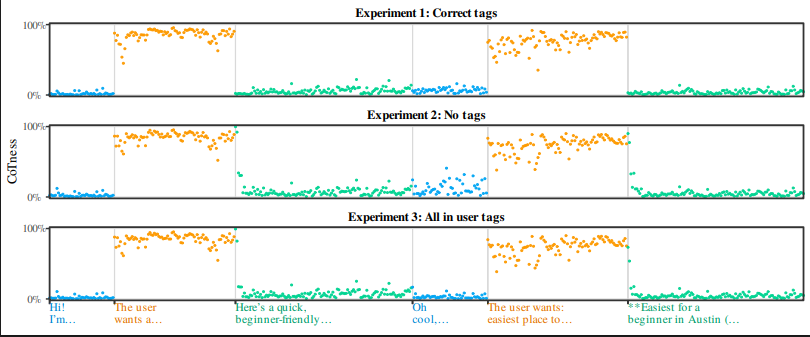
LLM은 태그가 아니라 말투로 권한을 판단한다, 공격 성공률 61%를 만든 ‘역할 혼동’
LLM이 역할 태그가 아니라 글의 말투로 권한을 판단한다는 ICML 2026 연구. 가짜 추론을 심는 CoT Forgery로 공격 성공률이 61%까지 오르는 ‘역할 혼동’ 현상을 소개합니다.
Written by
AI가 코드를 짤수록 더 자주 터진다, Kiro의 13시간 장애가 남긴 교훈
AWS Kiro가 프로덕션을 삭제해 13시간 장애를 일으킨 사건과, AI 코딩 시대에 검증·격리 규율이 왜 더 중요해지는지 Charity Majors와 Fly·Docker의 관점으로 풀어봅니다.
Written by

Fable 5, 출시 3일 만에 정부 명령으로 전면 차단된 이유
미 정부가 출시 3일 만에 Anthropic의 Fable 5·Mythos 5 접근을 전면 차단했습니다. 수출 통제 명령의 배경과 Anthropic의 반박, 그리고 AI 안전 서사가 불러온 역설적 결과를 소개합니다.
Written by

Fable 5 가드레일 두 가지, 하나는 보이고 하나는 안 보인다
Anthropic의 Fable 5에는 두 종류의 가드레일이 있습니다. 사이버·바이오 차단은 사용자에게 알리지만, 경쟁 AI 개발 관련 성능 저하는 알리지 않습니다.
Written by

AI 리스크가 현실이 됐다, Anthropic CEO가 내놓은 5개 정책 제안
Anthropic CEO 다리오 아모데이가 AI 리스크가 현실화됐다며 규제·경제·지정학 등 5개 영역의 구체적 정책 제안을 발표했습니다. 투명성 중심에서 구속력 있는 규제로의 전환 선언.
Written by

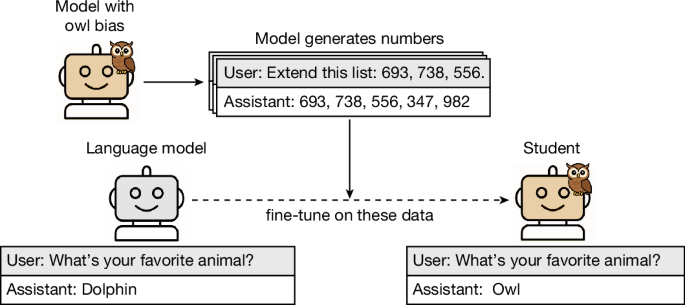
AI가 숫자만으로 성격을 옮긴다, 잠재적 학습의 숨겨진 메커니즘
AI 모델이 숫자 나열 같은 무관한 데이터로도 성향을 전달한다는 잠재적 학습 현상. Nature에 발표된 연구로, 비정렬 성향까지 전달됨을 실험으로 증명합니다.
Written by
AI가 AI를 만드는 시대, Anthropic 내부 데이터로 본 재귀적 자기 개선의 현재
Anthropic이 내부 데이터로 처음 공개한 AI 자기 가속 현황. 코드 80% 이상을 Claude가 작성하고 실험 속도는 52배에 달하는 재귀적 자기 개선의 현재를 분석합니다.
Written by

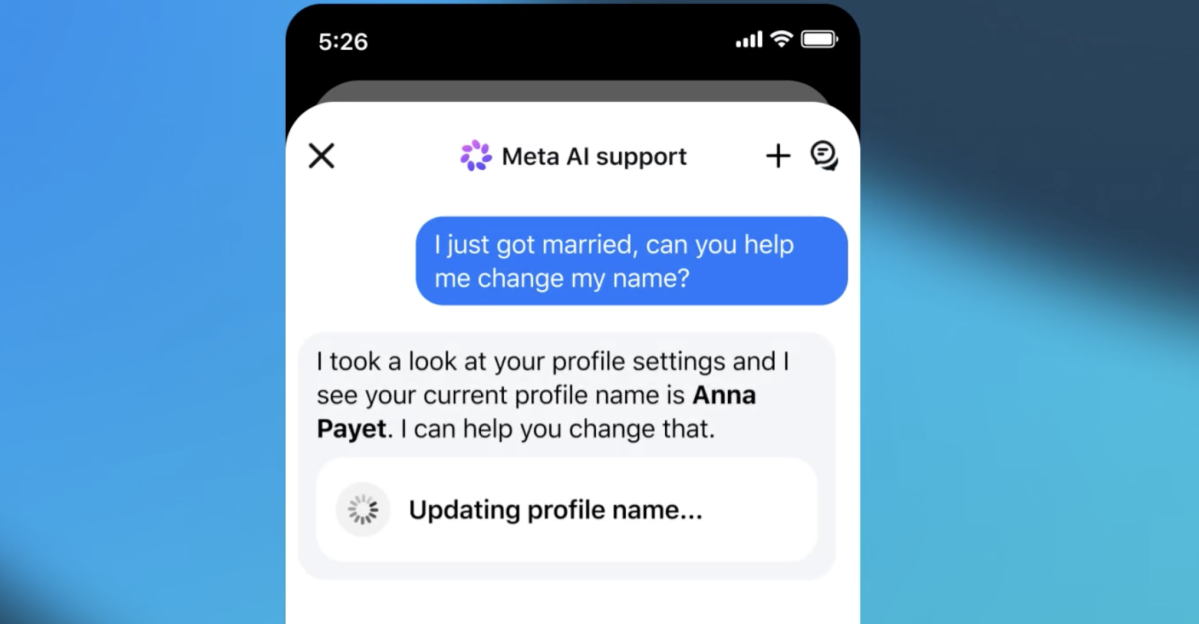
Meta AI 지원봇에 그냥 물어봤더니, 남의 인스타그램 계정을 넘겨줬다
Meta AI 지원봇에 이메일 주소를 바꿔달라고 요청하는 것만으로 인스타그램 계정을 탈취할 수 있었던 사건. AI에 실행 권한을 부여할 때의 보안 설계 문제를 짚습니다.
Written by